21 Yinelemeler
21.1 Giriş
Fonksiyonlarda, kodunuzdaki tekrarları azaltmak için kopyala-yapıştır yapmak yerine, fonksiyonları kullanmanın ne kadar önemli olduğunu konuşmuştuk. Kod tekrarlarını azaltmanın üç ana faydası vardır:
Kodunuzun amacını görmek daha kolaydır, çünkü gözleriniz farklı kodlara odaklanır, sürekli aynı kalanlara değil.
Gerek duyduğunuz değişiklikleri yapmak daha kolaydır. Gereksinimleriniz değiştikçe, kodu kopyaladığınız ve yapıştırdığınız her yeri değiştirmeyi hatırlamak yerine yalnızca bir yerde değişiklikler yapmanız yeterlidir.
Her kod daha fazla işlemi kapsayacak şekilde kullanıldığı için, hata ile karşılaşma olasılığınız azalır.
Kod tekrarlarını azaltmanın bir yolu fonksiyonlardır; kodunuzdaki tekrarlanan örüntüleri tanımlar ve bunları bağımsız parçalar olarak yazarsınız, böylece başka yerlerde kullanımları ya da güncellenmeleri kolaylaşır. Diğer yol ise yinelemeler (iteration) olarak geçer. Farklı sütunlar ya da farklı veri setleri gibi birden fazla girdiye, aynı işlemleri uygulamanızı kolaylaştırır. Bu bölümde iki önemli yineleme paradigmasını öğreneceksiniz: emirli programlama ve fonksiyonel programlama. Emirli Programlamada (EP), while ve for döngüleri gibi araçlarınız vardır, ve başlangıç için harikadırlar çünkü yinelemeyi çok net hale getirirler, ne olduğu çok açıktır. Diğer taraftan, for döngülerinde laf kalabalığı vardır ve her döngü için bazı sayım yapan kodları sürekli tekrarlamayı gerektirir. Fonksiyonel programlama (FP) bu kopyalanmış kodu ayıklamak için araçlar sunar, böylece her ortak for döngüsü kodu kendi fonksiyonunu alır. FP sözlüğüne hakim olduğunuzda, birçok yaygın yineleme problemini daha az kodla, daha kolay ve daha az hatayla çözebilirsiniz.
21.2 For döngüleri
Basit bir tibbleımız olsun:
df <- tibble(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)Her sütunun ortalamasını hesaplamak istiyoruz. Bunu kopyala-yapıştır ile yapabilirsiniz:
median(df$a)
#> [1] -0.246
median(df$b)
#> [1] -0.287
median(df$c)
#> [1] -0.0567
median(df$d)
#> [1] 0.144Fakat bu temel kuralımıza aykırıdır: asla iki defadan fazla kopyalayıp yapıştırma. Onun yerine, for döngüsü kullanabiliriz:
output <- vector("double", ncol(df)) # 1. output
for (i in seq_along(df)) { # 2. sequence
output[[i]] <- median(df[[i]]) # 3. body
}
output
#> [1] -0.2458 -0.2873 -0.0567 0.1443Her döngünün üç bileşeni vardır:
çıktı:
output <- vector("double", length(x)). Döngüyü başlatmadan önce, her zaman çıktı için yeterli alan ayırmanız gerekir. Bu, verimlilik için çok önemlidir: eğer her for döngünüzü her yinelemede (örneğin)c ()’yi kullanarak büyütürseniz for döngünüz çok yavaş olacaktır.Belirli bir uzunlukta boş bir vektör oluşturmanın genel yolu
vector ()fonksiyonudur. İki argümanı vardır: vektör tipi (“logical”, “integer”, “double”, “character”, etc) ve vektör uzunluğu.dizi:
i in seq_along(df). Bu, döngüye neyin gireceğini belirler: for döngüsünün her çalışmasıiyiseq_along (df)den farklı bir değere atar.iyi “O” gibi bir zamir olarak düşünmek faydalı olabilir.Daha önce
seq_along ()u görmemiş olabilirsiniz. Bu, tanıdık1: length (l)nin güvenli bir versiyonudur, önemli bir farkla: sıfır uzunluklu bir vektörünüz varsa,seq_along ()doğru olanı yapar:y <- vector("double", 0) seq_along(y) #> integer(0) 1:length(y) #> [1] 1 0Muhtemelen kasıtlı olarak sıfır uzunluklu bir vektör oluşturmazsınız, ancak kazayla oluşmaları kolaydır.
Seq_along (x)yerine1: length (x)kullanırsanız, kafa karıştırıcı bir hata mesajı alabilirsiniz.gövde:
output[[i]] <- median(df[[i]]). İşi yapan kod budur. Her seferinde “i” için farklı bir değerde tekrar tekrar çalıştırılır. İlk yinelemede, ilk girdiyi çalıştıracakoutput[[1]] <- median(df[[1]]), ikinci yinelemeoutput[[2]] <- median(df[[2]])i, ve böyle devam edecektir.
For döngüsü için hepsi bu kadar! Şimdi aşağıdaki alıştırmaları kullanarak bazı temel (ve çok da temel olmayan) for döngüleri oluşturmak için iyi bir zaman. Daha sonra for döngüsünün, pratikte ortaya çıkacak bazı sorunları çözmenize yardımcı olacak farklı varyasyonlarına geçeceğiz.
21.2.1 Alıştırmalar
Aşağıdakiler için döngü yazınız:
mtcarsverisindeki tüm sütunların ortalamasını bulunuz.nycflights13::flightsverisindeki her sütunun veri tipini bulunuz.irisverisinin sütunlarındaki “benzersiz değerlerin” sayısını hesaplayın.- \(\mu = -10\), \(0\), \(10\), and \(100\) değerlerini içeren 10 tane rnorm (normal dağılıma sahip rasgele sayılar seçimi) üretin.
Döngüleri yazmaya başlamadan önce output, sequence, ve body ’leri düşünün.
Vektörlerle çalışan mevcut fonksiyonlardan yararlanarak aşağıdaki örneklerin her birinde for döngüsünü kaldırın:
out <- "" for (x in letters) { out <- stringr::str_c(out, x) } x <- sample(100) sd <- 0 for (i in seq_along(x)) { sd <- sd + (x[i] - mean(x)) ^ 2 } sd <- sqrt(sd / (length(x) - 1)) x <- runif(100) out <- vector("numeric", length(x)) out[1] <- x[1] for (i in 2:length(x)) { out[i] <- out[i - 1] + x[i] }Fonksiyon yazma ve for döngüsü oluşturma becerilerinizi birleştirin:
1.
print()kullanarak, bir çocuk şarkısı olan Kırmızı balık şarkısının sözleriniyazdıranbir for döngüsü oluşturun.“ten in the bed” tekerlemesini bir fonksiyona dönüştürün. Herhangi bir sayıdaki uyuyan insan yapısına genelleyin. Herhangi bir uyku yapısındaki herhangi bir sayıda insana genelleyin.
“99 bottles of beer on the wall” şarkısının sözlerini bir fonksiyona çevirin. Herhangi bir yüzeyde, herhangi bir sıvı içeren herhangi bir kap sayısını genelleştirin. (Çeviri Notu: “99 bottles of beer on the wall” şişeleri 99dan geriye sayan tekrarlı bir şarkıdır. Yazacağınız fonksiyonu daha iyi şekillendirmek için şarkının sözlerine bakmanızı öneririz.)
for döngülerini, çıktıyı vektörün önceden belirli bir yerine atamak yerine,
döngünün her adımında vektörün uzunluğunu bir birim artıracak şekilde görmek oldukça yaygındır.output <- vector("integer", 0) for (i in seq_along(x)) { output <- c(output, lengths(x[[i]])) } outputBu kodunuzun performansını nasıl etkiler? Bir deneme kodu tasarlayın ve kodunuzu çalıştırın.
21.3 For döngüsü varyasyonları
for döngüsünün temellerini özümsedikten sonra, bazı varyasyonlarından haberdar olmakta fayda var. Bu varyasyonlar, tekrarlamayı nasıl yaptığınız fark etmeksizin önemlidir, yani her yöntemde işinize yarayabilirler. Bu nedenle bir sonraki bölümde öğreneceğiniz FP yöntemlerine hakim olduktan sonra da, bu varyasyonları unutmayın!
for döngüsünün ana temasında dört varyasyon vardır:
- Yeni bir nesne oluşturmak yerine mevcut bir nesneyi değiştirmek.
- İndeksler yerine isimler veya değerleri döngüye sokmak.
- Bilinmeyen uzunluktaki çıktıları kontrol altında tutmak.
- Bilinmeyen uzunluktaki dizgeleri kontrol altında tutmak.
21.3.1 Mevcut bir nesneyi değiştirmek
Bazen varolan bir nesneyi değiştirmek için bir for döngüsü kullanmak istersiniz. Örneğin, fonksiyonlardaki alıştırmamızı hatırlayın. Bir veri tablosundaki her sütunu yeniden ölçeklendirmek istemiştik:
df <- tibble(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)
rescale01 <- function(x) {
rng <- range(x, na.rm = TRUE)
(x - rng[1]) / (rng[2] - rng[1])
}
df$a <- rescale01(df$a)
df$b <- rescale01(df$b)
df$c <- rescale01(df$c)
df$d <- rescale01(df$d)Bunu, bir for döngüsü ile çözmek için üç bileşeni tekrar düşünelim:
çıktı: çıktımız zaten var — girdi ile aynı!
dizi: veri tablosunu sütunlar listesi olarak düşünebiliriz, dolayısıyla her sütunu
seq_along(df)ile yineleyebiliriz.gövde:
rescale01()uygulayın.
Yani:
for (i in seq_along(df)) {
df[[i]] <- rescale01(df[[i]])
}Genellikle bu tür bir döngü ile bir liste veya veri tablosunu düzenlersiniz, bu yüzden [[ kullanmayı unutmayın: [ değil.Tüm döngülerimde [[ kullandığımı fark etmiş olabilirsiniz : Bence atomik vektörler için bile [[ kullanmak daha iyi çünkü bu açıkça tek bir elemanla çalışmak istediğimizi gösteriyor.
21.3.2 Döngü örüntüleri
Bir vektör üzerinde döngü oluşturmanın üç temel yolu vardır. Şimdiye kadar size en genel olanı gösterdim: sayısal indislerin üzerinden for (i seq_along (xs)) ile döngü oluşturmak ve bir değeri x[[i]] ile elde etmek. Farkı iki form daha var:
Elemanlar üzerinden döngü oluşturmak:
for (x in xs). Bu, yalnızca yan etkilerle ilgileniyorsanız kullanışlı bir yöntemdir. Örneğin grafik çizmek ya da çıktıyı dosyaya kaydetmek; çünkü çıktıyı verimli bir şekilde kaydetmek çok zordur.İsimler üzerinden döngü oluşturmak:
for (nm in names(xs)). Bu size, bir değerex [[nm]]ile erişmek için kullanabileceğiniz bir isim verir. Bu, isimleri bir grafik başlığında ya da dosya isimlendirmede kullanacağınız zaman kullanışlıdır. İsimlerden oluşan bir çıktınız varsa, sonuç vektörünü şöyle adlandırdığınızdan emin olun:results <- vector("list", length(x)) names(results) <- names(x)
Sayısal indislerle yineleme en genel kullanılan formdur, çünkü bir pozisyon girdiğinizde (x[[i]] kullanarak), o pozisyonun hem ismini hem de sayısal değerini elde edebilirsiniz.
for (i in seq_along(x)) {
name <- names(x)[[i]]
value <- x[[i]]
}21.3.3 Bilinmeyen çıktı uzunluğı
Bazen çıktınızın uzunluğunun ne olacağını önceden bilemeyebilirsiniz. Örneğin, rastgele uzunluklardaki bazı rasgele vektörleri simüle etmek istediğinizi düşünün. Vektörleri giderek büyüterek bu sorunu çözme eğiliminde olabilirsiniz:
means <- c(0, 1, 2)
output <- double()
for (i in seq_along(means)) {
n <- sample(100, 1)
output <- c(output, rnorm(n, means[[i]]))
}
str(output)
#> num [1:138] 0.912 0.205 2.584 -0.789 0.588 ...Ancak bu çok verimli bir yol değildir; çünkü döngünün her bir adımında, R tüm verileri önceki adımlardan kopyalamak zorundadır.Teknik terimlerle “kuadratik” ($ O (n ^ 2) $) bir davranış elde edersiniz; bu, üç öğeye sahip bir döngünün hesaplama süresinin, bir öğeye sahip formundan dokuz (\(3^2\)) kat daha uzun süreceği anlamına gelir.
Daha iyi bir çözüm: sonuçları bir listeye kaydetmek ve daha sonra döngü tamamlandığında tek bir vektör halinde birleştirmek.
out <- vector("list", length(means))
for (i in seq_along(means)) {
n <- sample(100, 1)
out[[i]] <- rnorm(n, means[[i]])
}
str(out)
#> List of 3
#> $ : num [1:76] -0.3389 -0.0756 0.0402 0.1243 -0.9984 ...
#> $ : num [1:17] -0.11 1.149 0.614 0.77 1.392 ...
#> $ : num [1:41] 1.88 2.46 2.62 1.82 1.88 ...
str(unlist(out))
#> num [1:134] -0.3389 -0.0756 0.0402 0.1243 -0.9984 ...Burada bir vektör listesini tek bir vektöre çevirmek için unlist () kullandım. Daha kurallı bir kullanım: purrr::flatten_dbl() — eğer girdi “double” listesi değilse hata mesajı verecektir.
Bu örüntü başka yerlerde de oluşur:
Uzun bir “string” oluşturuyorsunuzdur. Her bir tekrarı öncekiyle birlikte bir araya getirmek için ‘paste ()’ kullanmak yerine, çıktıyı bir karakter vektörüne kaydedin ve ardından bu vektörü ’paste (output, collapse = ““) `ile tek bir”string”de birleştirin.
Büyük bir veri tablosu oluşturuyorsunuzdur. Her tekrarı sırayla
rbind ()ile birleştirmek yerine, çıktıyı bir listeye kaydedin, ardından çıktıyı tek bir veri tablosunda birleştirmek içindplyr :: bind_rows (output)kullanın.
Bu örüntüye dikkat edin. Gördüğünüz yerde, daha karmaşık bir sonuç nesnesine geçin ve sonunda nesneleri tek bir adımda birleştirin.
21.3.4 Bilinmeyen dizi uzunluğu
Bazen girdi dizisinin tamamlanmasının ne kadar zaman alacağını bilmezsiniz. Simülasyon uygulamalarında bu çok yaygındır. Örneğin, dizinizi art arda üç tura elde edene kadar tekrarlamak istersiniz. for döngüsü ile bu tip bir yineleme yapamazsınız. for yerine, while döngüsünü kullanabilirsiniz. while döngüsü for döngüsünden daha basittir çünkü yalnızca iki bileşeni vardır, koşul ve gövde:
while (kosul) {
# gövde
}Ayrıca, bir while döngüsü bir for döngüsünden daha geneldir, çünkü herhangi bir for döngüsünü bir while döngüsü olarak yeniden yazabilirsiniz, ancak her while döngüsünü for döngüsü olarak yeniden yazamazsınız:
for (i in seq_along(x)) {
# gövde
}
# while kullanarak aynı döngü
i <- 1
while (i <= length(x)) {
# gövde
i <- i + 1
}İşte üç kez art arda tura almak için bir seferde kaç deneme yapmamız gerektiğini bulmak için kullanabileceğimiz bir while döngüsü
flip <- function() sample(c("T", "H"), 1)
flips <- 0
nheads <- 0
while (nheads < 3) {
if (flip() == "H") {
nheads <- nheads + 1
} else {
nheads <- 0
}
flips <- flips + 1
}
flips
#> [1] 21while döngülerinden çok kısaca bahsettim, çünkü ben çok nadir kullanıyorum. En yaygın kullanımları simülasyonlardır, ve simülasyonlar da bu kitabın kapsamı dışında. Yine de, tekrarlama sayısı belli olmayan durumlara karşı önceden hazılıklı olmanız için varlıklarından haberdar olmak iyidir.
21.3.5 Alıştırmalar
Bir dosyada okumak istediğiniz csv dosyalarının olduğunu düşünün. Bir vektörde de adresleri var,
files <- dir("data/", pattern = "\\.csv$", full.names = TRUE), ve siz her biriniread_csv()kullanarak okumak istiyorsunuz. tüm okuduğunuz csv dosyalarını bir veri tablosunda toplayan bir for döngüsü yazın.Eğer
xin ismleri yoksa vefor (nm in names(x))kullanırsanız ne olur? Ya sadece bazı elemanlar isimlendirilmişse? Ya isimler özgün değilse (aynı isimli dosyalar varsa)?Veri tablosundaki her sayısal sütunun ortalamasını yazdıran bir fonksiyon oluşturun. Örneğin,
show_mean(iris)şöyle yazdırır:show_mean(iris) #> Sepal.Length: 5.84 #> Sepal.Width: 3.06 #> Petal.Length: 3.76 #> Petal.Width: 1.20(Ekstra zorluk: değişken isimleri farklı uzunlukta olduğu halde, hangi fonksiyonu kullanırsam numaraların düzgün sıralandığından emin olabilirim?)
Bu kod ne yapar? Nasıl çalışır?
trans <- list( disp = function(x) x * 0.0163871, am = function(x) { factor(x, labels = c("auto", "manual")) } ) for (var in names(trans)) { mtcars[[var]] <- trans[[var]](mtcars[[var]]) }
21.4 for Döngüleri Fonksiyonlar’a karşı
for döngüleri R için, diğer programlama dillerinde olduğu kadar önemli değildir çünkü R fonksiyonel bir dildir. Bu, döngüleri fonksiyonlar içinde derlemenin ve döngüyü direkt olarak kullanmak yerine fonksiyonu çağırmanın mümkün olduğu anlamına gelir.
Bunun neden önemli olduğunu anlamak için (tekrar) bu basit veri tablosunu düşünün:
df <- tibble(
a = rnorm(10),
b = rnorm(10),
c = rnorm(10),
d = rnorm(10)
)Her sütunun ortalamasını hesaplamak istediğinizi düşünün. Bunu for döngüsü kullanarak yapabilirsiniz:
output <- vector("double", length(df))
for (i in seq_along(df)) {
output[[i]] <- mean(df[[i]])
}
output
#> [1] -0.326 0.136 0.429 -0.250Sonra, her sütunun ortalamasını hesaplama işlemini sık sık tekrar etmek isteyeceğinizi fark ediyorsunuz. Bu durumda, döngünüzü bir fonksiyonun içine yazın:
col_mean <- function(df) {
output <- vector("double", length(df))
for (i in seq_along(df)) {
output[i] <- mean(df[[i]])
}
output
}Daha sonra, medyan ve standart sapma hesaplayabilmenin de faydalı olabileceğini düşünüyorsunuz. Önceden yazdığınız col_mean() fonksiyonunu kopyalayıp yapıştırın ve mean() komutunu, median() ve sd() ile değiştirin:
col_median <- function(df) {
output <- vector("double", length(df))
for (i in seq_along(df)) {
output[i] <- median(df[[i]])
}
output
}
col_sd <- function(df) {
output <- vector("double", length(df))
for (i in seq_along(df)) {
output[i] <- sd(df[[i]])
}
output
}A, a! Bu kodu iki kez kopyala-yapıştır yaptınız, yani bu işlemleri nasıl genelleştirebileceğinizi düşünme zamanı! Bu kodun büyük bir kısmının for döngüsünün birbirinin aynı tekrarlı kısımları olduğuna dikkat edin. Burada, fonksiyonlar arasında farklı olan tek kısmı (mean(), median(), sd()) görmek zor olabilir.
Şöyle bir fonksiyon seti görseniz ne yapardınız:
f1 <- function(x) abs(x - mean(x)) ^ 1
f2 <- function(x) abs(x - mean(x)) ^ 2
f3 <- function(x) abs(x - mean(x)) ^ 3Umarım, çok fazla tekrarlama olduğunu ve hepsini tek bir argümanda toplamanın mümkün olduğunu fark etmişsinizdir:
f <- function(x, i) abs(x - mean(x)) ^ iYukarıdaki işlemin aynısını col_mean(), col_median() ve col_sd() ile de yapabiliriz. Fonksiyona, her sütuna uygulamasını sağlayacak bir argüman ekleyin:
col_summary <- function(df, fun) {
out <- vector("double", length(df))
for (i in seq_along(df)) {
out[i] <- fun(df[[i]])
}
out
}
col_summary(df, median)
#> [1] -0.5185 0.0278 0.1730 -0.6116
col_summary(df, mean)
#> [1] -0.326 0.136 0.429 -0.250Bir fonksiyonu başka fonksiyona aktarma fikri son derece etkili bir fikirdir ve R’ı işlevsel bir programlama dili yapan davranışlardan biridir. Bu fikre alışmanız biraz vaktinizi alabilir ama ayrıdığınız vaktin karşılığını alırsınız. Bölümün geri kalanında, purrr paketini nasıl kullanacağınızı öğreneceksiniz. Bu pakette, döngüler için birçok yaygın sorunu ortadan kaldıran fonksiyonlar vardır. Temel R’daki apply fonksiyon ailesi de (apply(), lapply(), tapply(), vb.) benzer sorunları çözer, fakar purr biraz daha tutarlıdır dolayısıyla öğrenmesi de daha kolaydır.
for döngüleri yerine purr fonksiyonlarını kullanmanın amacı yaygın liste manipülasyonu zorluklarını bağımsız parçalara bölmenize izin vermesidir.
Bir listenin tek bir elemanına ait bir problemi nasıl çözersiniz? Elemanın problemini çözdüğünüzde purr çözümünüzü listedeki tüm elemanlara uygular.
Karmaşık bir problemi çözerken, çözümü küçük bir adımı çözüme doğru ilerletmenize izin veren bayt (bite) büyüklüğünde parçalara nasıl ayırabilirsiniz?? purr, pipe’ınızla birlikte kullanabileceğiniz birçok küçük parça elde edersiniz.
Bu yaklaşım birçok yeni problemi çözmenizi kolaylaştırır. Ayrıca, eski kodunuzu sonradan okuduğunuzda eski sorunlarınızda uyguladığınız çözümlerini anlamanızı da kolaylaştırır.
21.4.1 Alıştırmalar
apply()için yazılmış dökümanı okuyun. 2. durumda hangi iki döngü genelleştirme yapar?col_summary()’yi sadece nümerik sütunlarda çalışacak şekilde uyarlayın. Verinizdeki her sayısal sütunu TRUE mantıksal (logical) vektörüne dönüştürenis_numeric()fonksiyonu ile başlayabilirsiniz.
21.5 Map fonksiyonları
Vektörler üzerindeki döngü işlemlerinde, vektörün her elemanına bir işlem uygulayıp sonuçları kaydetmek o kadar yaygın kullanılır ki, purr paketinde bunları sizin için yapan bir fonskiyon ailesi vardır. Her tür çıktı için bir fonksiyon bulunur:
map()liste oluşturur.map_lgl()mantıksal vektör oluşturur.map_int()tamsayı vektör oluşturur.map_dbl()“double” vektör oluşturur.map_chr()karakter vektörü oluşturur.
Her fonskiyon bir vektörü girdi olarak alır, fonksiyonu her elemana uygular ve aynı uzunluğa ve aynı isimlere sahip yeni bir vektöre dönüştürür. Vektörün türü de kullandığınız map fonksiyonundaki son-ek ile belirlenir.
Bu fonksiyonları kullanmaya alıştığınızda, yineleme problemlerini çözmenin çok daha kısa zamanlar aldığını göreceksiniz. Fakat map fonksiyonu yerine for loop kullanırken kendinizi kötü hissetmemelisiniz. map fonksiyonları soyutlaştırma kulesinin bir basamağıdır, ve nasıl çalıştkıklarını anlamanız uzun süre alabilir. Önemli olan üzerinde çalıştığınız problemi çözmenizdir; en kısa, özlü ve zarif kodu yazmanız değil (kesinlikle ulaşmak istediğiniz nokta olsa da!).
Bazı insanlar size, çok yavaş oldukları için for döngülerinden kaçınmanızı söyleyecekler. Yanılıyorlar! (Ya da en azından eskide kalmışlar, for döngüleri yıllardır yavaş değil). map() gibi fonksiyonları kullanmanın başlıca faydası netliktir, hız değil: kodunuzu yazmayı ve okumayı kolaylaştırırlar.
Bu fonksiyonları son for döngüsündeki hesaplamaların aynısını yapmak için kullanabiliriz. Bu fonksiyonlar “double” olarak çıktı verirler, o yüzden map_dbl() kullanmalıyız:
map_dbl(df, mean)
#> a b c d
#> -0.326 0.136 0.429 -0.250
map_dbl(df, median)
#> a b c d
#> -0.5185 0.0278 0.1730 -0.6116
map_dbl(df, sd)
#> a b c d
#> 0.921 0.485 0.982 1.156for loop ile karşılaştırıldığında burada odak, gerçekleştirilen işlemdedir (örneğin mean(), median(), sd()), her elemanı depolamak için gerekli döngü işlemleri değil. pipe kullandığımızda bunu açıkça görürüz: :
df %>% map_dbl(mean)
#> a b c d
#> -0.326 0.136 0.429 -0.250
df %>% map_dbl(median)
#> a b c d
#> -0.5185 0.0278 0.1730 -0.6116
df %>% map_dbl(sd)
#> a b c d
#> 0.921 0.485 0.982 1.156map_*() ve col_summary() arasında bazı farklar vardır:
Tüm purrr fonksiyonları C temellidir. Bu, okunabilirlik açısından fonksiyonları daha hızlı hale getirir.
İkinci argüman, .f, uygulanacak işlev, bir formül, bir karakter vektörü veya bir tamsayı vektörü olabilir. Bir sonraki bölümde bu kullanışlı kısayolları öğreneceksiniz.
map _ * (), her bir seferinde .f`ye ek argümanları iletmek için … ([nokta nokta nokta]) kullanır:map_dbl(df, mean, trim = 0.5) #> a b c d #> -0.5185 0.0278 0.1730 -0.6116map fonksiyonları ayrıca isimleri de korur:
z <- list(x = 1:3, y = 4:5) map_int(z, length) #> x y #> 3 2
21.5.1 Kısayollar
.f ile, kod yazmaktan biraz zaman kazanmanız için kullanabileceğiniz birkaç kısayol vardır. Bir veri setindeki her gruba uygulamak istediğiniz bir lineer model olduğunu düşünün. Aşağıdaki kolay örnek, ‘mtcars’ veri setini üç parçaya ayırır (her bir silindir değeri için bir tane) ve her bir parçaya aynı lineer modele uyar:
models <- mtcars %>%
split(.$cyl) %>%
map(function(df) lm(mpg ~ wt, data = df))R’da anonim bir fonksiyon yazmak için gerekli kod oldukça kalabalık. purr bunun için uygun bir kısayol sağlar: tek-taraflı formül.
models <- mtcars %>%
split(.$cyl) %>%
map(~lm(mpg ~ wt, data = .))Burada . ’yı tanımlayıcı olarak kullandım: nokta, o anda geçerli olan liste elemanını belirtir, aynı for döngüsünde i’nin yaptığı gibi.
Birçok modele aynı anda bakarsınız ve \(R^2\) gibi özet istatistik görmek istersiniz. Bunun için önce summary()’yi çalıştırmamız ve daha sonra r.squared isimli bileşenini çekmemiz gerekir.
models %>%
map(summary) %>%
map_dbl(~.$r.squared)
#> 4 6 8
#> 0.509 0.465 0.423Veriden ismi olan bileşenleri çekmek çok yaygın bir işlemdir, bu yüzden purr daha da kısa bir kısayol sağlar:“string” kullanabilirsiniz.
models %>%
map(summary) %>%
map_dbl("r.squared")
#> 4 6 8
#> 0.509 0.465 0.423Ayrıca, belirli bir pozisyondaki elemanları seçmek için sayı da kullanabilirsiniz.
x <- list(list(1, 2, 3), list(4, 5, 6), list(7, 8, 9))
x %>% map_dbl(2)
#> [1] 2 5 821.5.2 Temel R
Temel R’da apply fonksiyon ailesini kullanmaya alışkınsanız, purr fonksiyonlarındaki bazı benzerlikleri fark etmişsinizdir.
lapply()temeldemap()ile aynıdır, yalnızcamap()purr’daki diğer tüm fonksiyonlarla daha uyumludur, ve.fiçin kısayollar kullanabilirsiniz.Temel
sapply(),lapply()’ın sonuçlarını otomatik olarak basitleştirir. Bu interaktif işler için önemlidir fakat sorunlu bir fonksiyondur çünkü ne tip bir çıktı alacağınızı asla bilemezsiniz.x1 <- list( c(0.27, 0.37, 0.57, 0.91, 0.20), c(0.90, 0.94, 0.66, 0.63, 0.06), c(0.21, 0.18, 0.69, 0.38, 0.77) ) x2 <- list( c(0.50, 0.72, 0.99, 0.38, 0.78), c(0.93, 0.21, 0.65, 0.13, 0.27), c(0.39, 0.01, 0.38, 0.87, 0.34) ) threshold <- function(x, cutoff = 0.8) x[x > cutoff] x1 %>% sapply(threshold) %>% str() #> List of 3 #> $ : num 0.91 #> $ : num [1:2] 0.9 0.94 #> $ : num(0) x2 %>% sapply(threshold) %>% str() #> num [1:3] 0.99 0.93 0.87vapply(),sapply()’ın güvenli alternatifidir çünkü tipi tanımlayan bir argüman eklersiniz.vapply()ile ilgili tek problem çok fazla yazı gerektirmesidir:vapply(df, is.numeric, logical(1)),map_lgl(df, is.numeric)ile denktir.vapply()’ın purr’un map fonksiyonlarına göre bir avantajı matrisler de üretebilmesidir, map fonksiyonları yalnızca vektör üretir.
Burada purrr fonksiyonlarına odaklandım çünkü daha tutarlı isimleri ve argümanları, faydalı kısayolları var ve ???in the future will provide easy parallelism and progress bars.?? ?
21.5.3 Alıştırmalar
Aşağıdaki işlemleri yapacak map fonksiyonları kullanın:
mtcarsverisinde her sütunun ortalamasını hesaplayın.nycflights13::flightsverisindeki her sütunun veri tipini bulun.irisverisinin her sütunundaki eşsiz değerlerin (uniq values) sayısını hesaplayın.- Hepsi için 10 Generate 10 random normals for each of \(\mu = -10\), \(0\), \(10\), and \(100\).
Bir veri tablosunun her sütunu için, o sütunun faktör olup olmadığını belirten tek bir vektörü nasıl oluşturursunuz?
map fonksiyonlarını liste olmayan vektörler üzerinde kullandığınızda ne olur?
map(1:5, runif)ne yapar? Niçin?map(-2:2, rnorm, n = 5)ne yapar? Niçin?map_dbl(-2:2, rnorm, n = 5)ne yapar? Niçin?map(x, function(df) lm(mpg ~ wt, data = df))’i anonim fonksiyondan arındırarak yeniden yazın.
21.6 Başarısızlıkla baş etmek
Birden fazla işlemi tekrar etmek için map fonksyonları kullanırken, bu işlemlerden birinin yanlış olma ihtimali çok yüksektir. Bu durumlarda, bir hata mesajı alırsınız fakat çıktı alamazsınız. Bu sinir bozucudur: neden tek bir yanlış diğer tüm doğru sonuçlara erişmenize engel olur? Tek bir çürük elmanın bütün çuvalı mahvetmeyeceğinden nasıl emin olursunuz?
Bu bölümde, yanlışlarla baş etmek için kullanabileceğiniz yen bir fonksiyon öğreneceksiniz: safely(). safely() bir adıldır: yani bir fonksiyonu (bir adı) alır ve modifiye bir versiyonunu çıktı olarak verir. Bu durumda, modifiye fonksiyon asla hata vermez. Onun yerine her zaman iki elemanlı bir liste çıktısı oluşturur:
resultorjinal sonucunuzdur. Eğer hata varsaNULLolur.errorhata objesidr. Eğer işlemleriniz başarılıysaNULLolur.
(Temel R’daki try() fonksiyonuna aşina olabilirsiniz. Benzerdirler, ancak çıktı olarak bazen orijinal sonucu ve bazen de bir hata nesnesi verdiği için üzerinde çalışmak daha zordur.)
Basit bir örnekle inceleyelim: log():
safe_log <- safely(log)
str(safe_log(10))
#> List of 2
#> $ result: num 2.3
#> $ error : NULL
str(safe_log("a"))
#> List of 2
#> $ result: NULL
#> $ error :List of 2
#> ..$ message: chr "non-numeric argument to mathematical function"
#> ..$ call : language .Primitive("log")(x, base)
#> ..- attr(*, "class")= chr [1:3] "simpleError" "error" "condition"Fonksiyon başarılı bir şekilde çalıştığında, result elemanı sonuçları içerir ve hata elemanı olan error , NULL olarak gözükür. Fonksiyon başarısız olduğunda ise; sonuçları içeren eleman result, NULL olur ve error elemanı, hataları içeren bir obje içerir.
safely() map ile birlikte çalışmak üzere tasarlanmıştır:
x <- list(1, 10, "a")
y <- x %>% map(safely(log))
str(y)
#> List of 3
#> $ :List of 2
#> ..$ result: num 0
#> ..$ error : NULL
#> $ :List of 2
#> ..$ result: num 2.3
#> ..$ error : NULL
#> $ :List of 2
#> ..$ result: NULL
#> ..$ error :List of 2
#> .. ..$ message: chr "non-numeric argument to mathematical function"
#> .. ..$ call : language .Primitive("log")(x, base)
#> .. ..- attr(*, "class")= chr [1:3] "simpleError" "error" "condition"İki listeyle çalışırsak bu daha kolay olur: biri tüm hatalar için, diğeri tüm çıktılar için. purrr::transpose() ile bunu elde etmek kolaydır:
y <- y %>% transpose()
str(y)
#> List of 2
#> $ result:List of 3
#> ..$ : num 0
#> ..$ : num 2.3
#> ..$ : NULL
#> $ error :List of 3
#> ..$ : NULL
#> ..$ : NULL
#> ..$ :List of 2
#> .. ..$ message: chr "non-numeric argument to mathematical function"
#> .. ..$ call : language .Primitive("log")(x, base)
#> .. ..- attr(*, "class")= chr [1:3] "simpleError" "error" "condition"Hatalarla nasıl baş edeceğiniz size kalmış, fakat genellikle ya y’nin hata olduğu durumda x’in değerine bakacaksınız, ya da y’nin değerleri ile çalışacaksınız:
is_ok <- y$error %>% map_lgl(is_null)
x[!is_ok]
#> [[1]]
#> [1] "a"
y$result[is_ok] %>% flatten_dbl()
#> [1] 0.0 2.3Purrr iki kullanışlı argüman daha sunar:
safely()gibi,possibly()de her zaman çalışır.safely()’den daha sadedir, çünkü bir hata olduğunda geri dönmesi için varsayılan bir değer atarsınız.x <- list(1, 10, "a") x %>% map_dbl(possibly(log, NA_real_)) #> [1] 0.0 2.3 NAquietly(),safely()’ye benzer bir performansla çalışır, fakat hataları göstermek yerine yazdırılan sonucu, mesajları ve uyarıları gösterir.x <- list(1, -1) x %>% map(quietly(log)) %>% str() #> List of 2 #> $ :List of 4 #> ..$ result : num 0 #> ..$ output : chr "" #> ..$ warnings: chr(0) #> ..$ messages: chr(0) #> $ :List of 4 #> ..$ result : num NaN #> ..$ output : chr "" #> ..$ warnings: chr "NaNs produced" #> ..$ messages: chr(0)
21.7 Çoklu argümanlarla çalışmak
Şimdiye kadar, tekli girdilerle çalıştık. Fakat sıklıkla paralel olarak itere etmek istediğiniz çoklu-ilişkili girdileriniz olur. Bu map2() ve pmap() fonksiyonlarının görevidir. Örneğin, farklı ortalama değerlere sahip (mean) rasgele normal dağılımlar (random normals) simüle etmek istiyorsunuz. Bunu map() ile nasıl yapacağınızı biliyorsunuz:
mu <- list(5, 10, -3)
mu %>%
map(rnorm, n = 5) %>%
str()
#> List of 3
#> $ : num [1:5] 5.63 7.1 4.39 3.37 4.99
#> $ : num [1:5] 9.34 9.33 9.52 11.32 10.64
#> $ : num [1:5] -2.49 -4.75 -2.11 -2.78 -2.42Ya standart sapmaları da farklı olsun isterseniz? Bunu yapmanın bir yolu indisler üzerinde itere edip, sonuçları ortalamaların ve standart sapmaların vektörüne atamak:
sigma <- list(1, 5, 10)
seq_along(mu) %>%
map(~rnorm(5, mu[[.]], sigma[[.]])) %>%
str()
#> List of 3
#> $ : num [1:5] 4.82 5.74 4 2.06 5.72
#> $ : num [1:5] 6.51 0.529 10.381 14.377 12.269
#> $ : num [1:5] -11.51 2.66 8.52 -10.56 -7.89Fakat bu, kodunuzun niyetini bulanıklaştırır. Bunun yerine, iki vektör üzerinde paralel olarak yineleme yapan map2()’yi kullanabiliriz:
map2(mu, sigma, rnorm, n = 5) %>% str()
#> List of 3
#> $ : num [1:5] 3.83 4.52 5.12 3.23 3.59
#> $ : num [1:5] 13.55 3.8 8.16 12.31 8.39
#> $ : num [1:5] -15.872 -13.3 12.141 0.469 14.794map2() bu fonksiyon çağrıları serisini oluşturur:
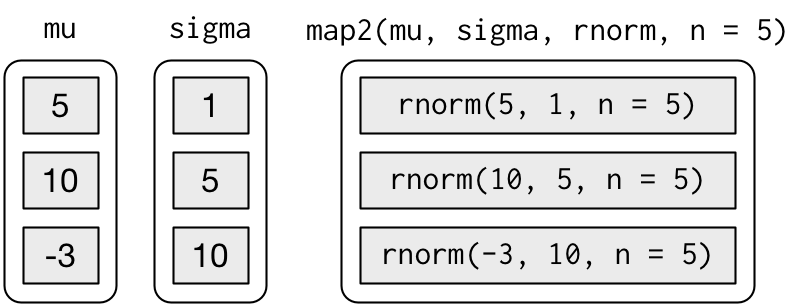
Her fonksiyon çağrısında değişen argümanların fonksiyondan önce geldiğine, her fonksiyonda aynı olan argümanların ise fonksiyondan sonra geldiğine dikkat edin.
map(), map2() aynı map()gibi, for döngülerinin derleyicisidir:
map2 <- function(x, y, f, ...) {
out <- vector("list", length(x))
for (i in seq_along(x)) {
out[[i]] <- f(x[[i]], y[[i]], ...)
}
out
}map3(), map4(), map5(), map6() vb. fonksiyonlar da düşünebilirsiniz, fakat işler çabucak can sıkıcı bir hal alabilir. Bunun yerine, purrr bir argüman listesini girdi olarak alan pmap() fonksiyonunu sunar. Bu fonksiyonu hem ortalamanın hem standart sapmanın hem de örnek sayısının farklı olmasını istediğiniz durumlarda kullanabilirsiniz:
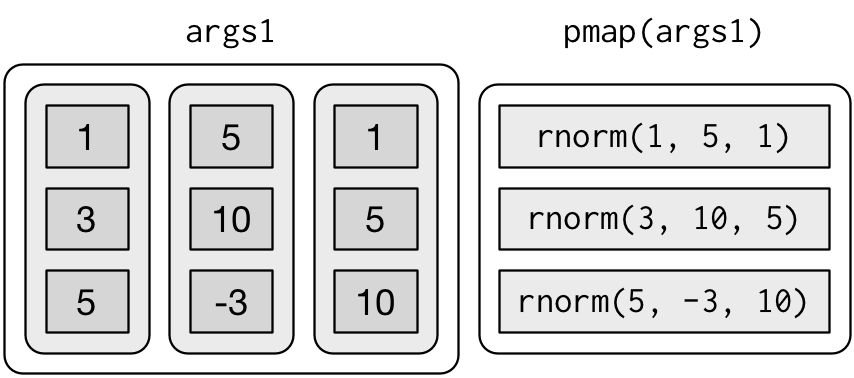
n <- list(1, 3, 5)
args1 <- list(n, mu, sigma)
args1 %>%
pmap(rnorm) %>%
str()
#> List of 3
#> $ : num 5.39
#> $ : num [1:3] 5.41 2.08 9.58
#> $ : num [1:5] -23.85 -2.96 -6.56 8.46 -5.21That looks like:
Eğer liste elemanlarını isimlendirmezseniz, pmap() konumsal eşleme yapacaktır. Bu biraz hassas bir durumdur, kodunuzun okunmasını zorlaştırır, bu yüzden argümanları isimlendirmek daha iyidir:
args2 <- list(mean = mu, sd = sigma, n = n)
args2 %>%
pmap(rnorm) %>%
str()Bu, daha uzun fakat daha güvenlidir:
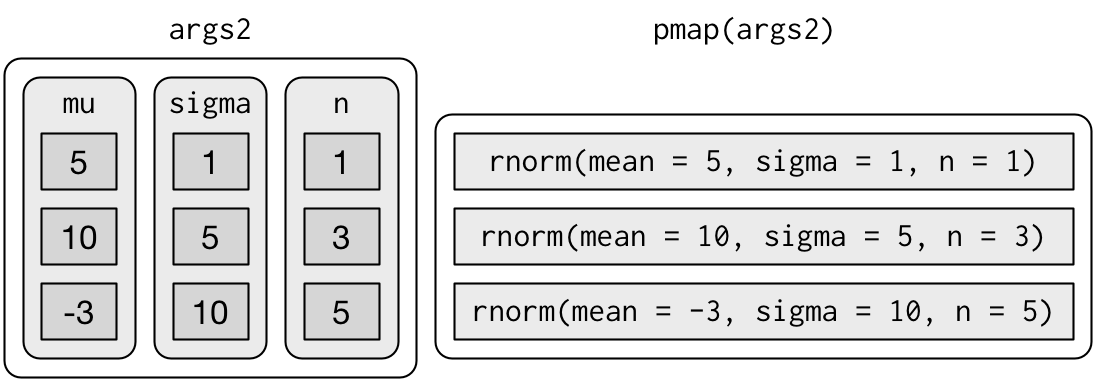
Argümanların hepsi aynı uzunluğa sahip olduğundan, hepsini bir veri tablosunda depolamak mantıklıdır:
params <- tribble(
~mean, ~sd, ~n,
5, 1, 1,
10, 5, 3,
-3, 10, 5
)
params %>%
pmap(rnorm)
#> [[1]]
#> [1] 6.02
#>
#> [[2]]
#> [1] 8.68 18.29 6.13
#>
#> [[3]]
#> [1] -12.24 -5.76 -8.93 -4.22 8.80Kodunuz karmaşıklaştığı anda veri tablosunun iyi bir yaklaşım olduğunu düşünüyorum çünkü her sütunun bir adının olmasını ve tüm sütunlarda aynı uzunlukta olmasını garantiler.
21.7.1 Diğer fonksiyonları çağırmak
Karmaşıklığı artırmak için bir adım daha var - fonksiyonun argümanlarını değiştirebildiğiniz gibi, fonksiyonun kendisini de değiştirebilirsiniz:
f <- c("runif", "rnorm", "rpois")
param <- list(
list(min = -1, max = 1),
list(sd = 5),
list(lambda = 10)
)Bununla başa çıkabilmek için invoke_map()’i kullanabilirsiniz:
invoke_map(f, param, n = 5) %>% str()
#> List of 3
#> $ : num [1:5] 0.479 0.439 -0.471 0.348 -0.581
#> $ : num [1:5] 2.48 3.9 7.54 -9.12 3.94
#> $ : int [1:5] 6 11 5 8 9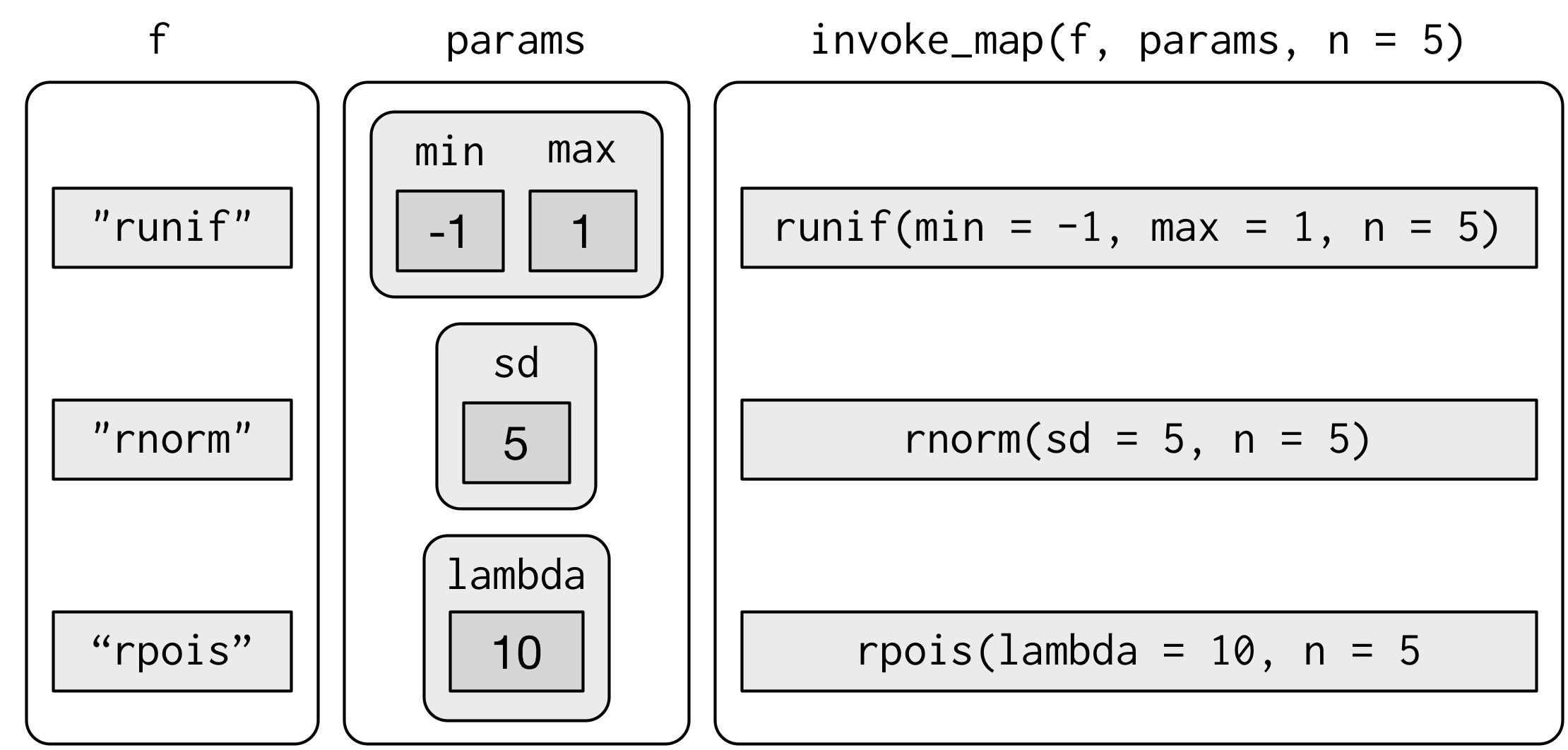
İlk argüman bir fonksiyon listesi ya da fonksiyonların isimlerinin karakter vektörüdür. İkinci argüman her fonksiyon için değişen argümanların listesinin listesidir. Sonraki argümanlar her fonksiyona aktarılır.
Tekrar edelim, bu eşleşen çiftleri oluşturmayı biraz daha kolaylaştırmak için tribble () kullanabilirsiniz:
sim <- tribble(
~f, ~params,
"runif", list(min = -1, max = 1),
"rnorm", list(sd = 5),
"rpois", list(lambda = 10)
)
sim %>%
mutate(sim = invoke_map(f, params, n = 10))21.8 Walk
Walk, bir fonskiyonu sonuç değerlerinden ziyade yan etkileri için çağırmak istediğinizde kullanabileceğiniz bir map’dir. Bunu genellikle ekrandan çıktı almak veya dosyaları diske kaydetmek istediğiniz için yaparsınız - önemli olan, sonuç değeri değil eylemdir. İşte çok basit bir örnek:
x <- list(1, "a", 3)
x %>%
walk(print)
#> [1] 1
#> [1] "a"
#> [1] 3walk(), walk2() ya da pwalk() ile kıyaslandığında o kadar kullanışlı değildir. Örneğin, grafiklerden oluşan bir listeniz ve dosya isimlerinden oluşan bir vektörünüz varsa, her dosyayı diskte belirtilen konuma kaydetmek için pwalk() kullanabilirsiniz:
library(ggplot2)
plots <- mtcars %>%
split(.$cyl) %>%
map(~ggplot(., aes(mpg, wt)) + geom_point())
paths <- stringr::str_c(names(plots), ".pdf")
pwalk(list(paths, plots), ggsave, path = tempdir())walk(), walk2() ve pwalk() hepsi görünmez .x sonucu verir. Bu özellikleriyle kod hatlarının ortasında (pipeline) kullanılmaya uygundurlar.
21.9 for döngülerinin diğer örüntüleri
Purr, diğer for döngüsü tiplerini özetleyen bir dizi başka fonksiyon sağlar. Bunları map fonskiyonlarından daha seyrek kullanacaksınız, ama bilmekte fayda var. Buradaki amaç, her bir fonksiyonu kısaca açıklamaktır, böylelikle umarız ki gelecekte benzer bir sorunla karşılaştığınızda aklınıza gelecektirler. Ardından daha fazla ayrıntı için kullanım yönergelerine bakabilirsiniz.
21.9.1 Doğrulama fonksiyonları
Bazı fonksiyonlar tek bir TRUE ya da FALSE sonucu veren doğrulama (predicate) fonksiyonlarıyla çalışır..
keep() ve discard() girdide doğrulamanın sırasıyla TRUE ya da FALSE olduğu elemanlarını tutar:
iris %>%
keep(is.factor) %>%
str()
#> 'data.frame': 150 obs. of 1 variable:
#> $ Species: Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
iris %>%
discard(is.factor) %>%
str()
#> 'data.frame': 150 obs. of 4 variables:
#> $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
#> $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
#> $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
#> $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...some () ve every (), doğrulamanın tüm elemanlar veya bazı elemanlar için doğru olup olmadığını kontrol eder.
x <- list(1:5, letters, list(10))
x %>%
some(is_character)
#> [1] TRUE
x %>%
every(is_vector)
#> [1] TRUEdetect() doğrulamanın doğru olduğu ilk elemanı bulur; detect_index() elemanın pozisyonunu gösterir.
x <- sample(10)
x
#> [1] 10 6 1 3 2 4 5 8 9 7
x %>%
detect(~ . > 5)
#> [1] 10
x %>%
detect_index(~ . > 5)
#> [1] 1head_while() ve tail_while() doğrulamanın doğru olduğu durumlarda vektörün başından ve sonundan eleman alır.
x %>%
head_while(~ . > 5)
#> [1] 10 6
x %>%
tail_while(~ . > 5)
#> [1] 8 9 721.9.2 Azalt ve biriktir
Bazen kompleks bir listeniz olur ve bunu tekrar eden fonksiyonlar uygulayarak basit bir listeye dönüştürmek istersiniz. Birden çok tabloya iki-tablolu dplyr fiili uygulamak istiyorsanız bu faydalıdır. Örneğin, veri tablolarından oluşan bir listeniz vardır ve bunu elemanları birleştirerek tek bir veri tablosuna dönüştürmek istersiniz.
dfs <- list(
age = tibble(name = "John", age = 30),
sex = tibble(name = c("John", "Mary"), sex = c("M", "F")),
trt = tibble(name = "Mary", treatment = "A")
)
dfs %>% reduce(full_join)
#> Joining, by = "name"
#> Joining, by = "name"
#> # A tibble: 2 × 4
#> name age sex treatment
#> <chr> <dbl> <chr> <chr>
#> 1 John 30 M <NA>
#> 2 Mary NA F AYa da vektörlerden oluşan bir listeniz var, ve kesişimlerini bulmak istiyorsunuz:
vs <- list(
c(1, 3, 5, 6, 10),
c(1, 2, 3, 7, 8, 10),
c(1, 2, 3, 4, 8, 9, 10)
)
vs %>% reduce(intersect)
#> [1] 1 3 10Azaltma fonksiyonu “binary” (örn: iki girdisi olan bir fonksiyon) bir fonksiyonu alır , ve listede yalnızca bir eleman kalana kadar fonksiyonu listeye uygulamaya devam eder.
Biriktirmek de benzer şekilde çalışır fakat ara sonuçları da saklar. Kümülatif toplama işlemi yaparken kullanabilirsiniz:
x <- sample(10)
x
#> [1] 7 5 10 9 8 3 1 4 2 6
x %>% accumulate(`+`)
#> [1] 7 12 22 31 39 42 43 47 49 5521.9.3 Alıştırmalar
for döngüsü kullanarak kendi versiyonunuz olan
every()oluşturun.purrr::every()’dakievery()ile karşılaştırın. purr’un versiyonunda yapabilip de,kendi versiyonunuzda yapamadığınız ne var?col_summary()kullanarak, bir veri tablosunda sayısal olan tüm sütunların ortalamasını alan bir fonksiyon yazın.col_summary()’nin Temel R’daki eşleniği:col_sum3 <- function(df, f) { is_num <- sapply(df, is.numeric) df_num <- df[, is_num] sapply(df_num, f) }Aşağıdaki girdilerde gösterildiği gibi birkaç hatası var:
df <- tibble( x = 1:3, y = 3:1, z = c("a", "b", "c") ) # OK col_sum3(df, mean) # Sorunlu: her zaman nümerik vektör olarak sonuç vermiyor col_sum3(df[1:2], mean) col_sum3(df[1], mean) col_sum3(df[0], mean)Hatalara sebep olan nedir?