25 Birçok model
25.1 Giriş
Bu bölümde çok sayıda model ile kolaylıkla çalışmanıza yardımcı olacak üç etkili fikri öğreneceksiniz:
Karmaşık veri setlerini daha iyi anlamak için çok sayıda basit model kullanmak.
Rastgele veri yapılarını bir veri tablosunda depolamak için liste-sütunlarını kullanmak. Örneğin, bu, doğrusal modeller içeren bir sütuna sahip olmanızı sağlar.
Modelleri düzenli verilere dönüştürmek için David robinson tarafından oluşturulan broom paketini kullanmak. Bu, çok sayıda modelle çalışmak için güçlü bir tekniktir çünkü verileriniz düzenli olduğunda kitapta daha önce öğrendiğiniz tüm teknikleri uygulayabilirsiniz.
Dünyanın çeşitli yerlerinden ortalama yaşam sürelerini içeren bir veriyi kullanan motive edici bir örneğe girişerek başlayacağız. Bu küçük bir veri tablosu ancak görselleştirmelerinizi geliştirmek için modellemenin ne kadar önemli olabileceğini gösterecektir. En güçlü sinyallerden bazılarını ayırmak için çok sayıda basit model kullanacağız. Böylece geriye kalan daha zayıf sinyalleri görebiliriz. Ayrıca model özetlerinin uç değer ve sıra dışı eğilimleri seçmemize nasıl yardımcı olabileceğini de göreceğiz.
Aşağıdaki bölümler bu bireysel teknikleri daha detaylı olarak ele alacaktır:
Liste-sütunlar bölümünde, liste-sütun veri yapısı ve listeleri veri tablolarına yerleştirmenin neden mantıklı olduğu hakkında daha fazla bilgi edineceksiniz.
[Liste-sütunları oluşturma] bölümünde liste-sütunları oluşturmanın üç ana yolun öğreneceksiniz.
Liste-sütunları sadeleştirme bölümünde liste-sütunlarını normal atomik vektörlere (ya d atomik vektör setlerine) nasıl dönüştüreceğimizi öğreneceksiniz, böylece onlarla daha kolay çalışabilirsiniz.
broom ile düzenli veri oluşturma bölümünde broom tarafından sağlanan tüm araçlar hakkında bilgi edineceksiniz ve ve diğer veri yapı tiplerine nasıl uygulanabileceklerini göreceksiniz.
Bu bölüm biraz ilham verici: eğer bu kitap sizin R’la ilk tanışmanız ise bu bölüm size biraz zorlayıcı gelebilir. Modelleme, veri yapıları ve tekrarlamalar hakkında derinlemesine içselleştirilmiş bilgiye sahip olmanızı gerektiriyor. Bu nedenle eğer anlamıyorsanız endişelenmeyin — sadece bu bölümü birkaç aylığına bir kenara koyun ve beyin jimnastiği yapmanız gerektiğinde geri dönün.
25.2 gapminder
Bazı basit modellerin gücünü göstermek için “gapminder” verisini gözden geçireceğiz. Bu veri İsveçli bir doktor ve istatistikçi olan Hans Rosling tarafından popüler hale getirildi. Eğer adını hiç duymadıysanız bu bölümü okumayı hemen bırakın ve videolarından birini izleyin! O harika bir veri sunucusu ve zorlu bir hikaye sunmak için verileri nasıl kullanabileceğinizi gösteriyor. BBC ile birlikte çekilen bu kısa video başlamak için iyi bir yer: https://www.youtube.com/watch?v=jbkSRLYSojo.
Gapminder verisi ortalama yaşam süresi ve GSYİH gibi istatistiklere bakarak ülkelerin zaman içindeki gelişimini özetlemektedir. gapminder paketini hazırlayıp R’da kolay ulaşımı sağladığı için Jenny Bryan’a teşekkürler.
library(gapminder)
gapminder
#> # A tibble: 1,704 × 6
#> country continent year lifeExp pop gdpPercap
#> <fct> <fct> <int> <dbl> <int> <dbl>
#> 1 Afghanistan Asia 1952 28.8 8425333 779.
#> 2 Afghanistan Asia 1957 30.3 9240934 821.
#> 3 Afghanistan Asia 1962 32.0 10267083 853.
#> 4 Afghanistan Asia 1967 34.0 11537966 836.
#> 5 Afghanistan Asia 1972 36.1 13079460 740.
#> 6 Afghanistan Asia 1977 38.4 14880372 786.
#> # … with 1,698 more rowsBu örnek olayda “ortalama yaşam süresi(lifeExp) zaman içerisinde (year) her ülke için (country) nasıl değişir?” sorusunu cevaplamak için sadece üç değişkene odaklanacağız. Bir grafik başlamak için iyi bir yerdir:
gapminder %>%
ggplot(aes(year, lifeExp, group = country)) +
geom_line(alpha = 1/3)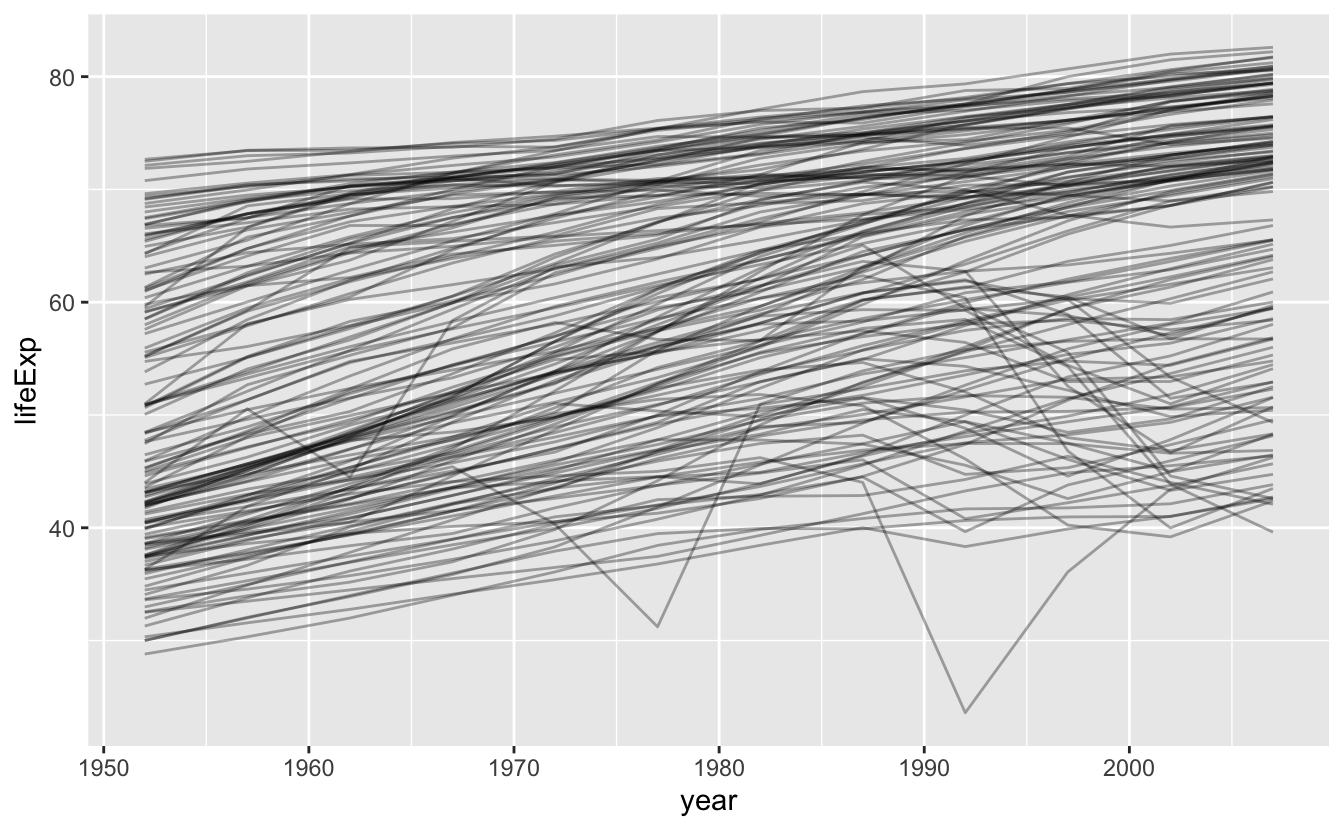
Bu küçük bir veri seti: sadece ~1,700 gözlem ve 3 değişkene sahip. Fakat neler olup bittiğini görmek hala zor! Genel olarak ortalama yaşam süresi istikrarlı bir şekilde iyileşiyor gibi görünüyor. Ancak daha yakından bakarsak bazı ülkelerin bu örüntüyü takip etmediğinin farkına varabiliriz. Peki bu ülkelerin daha kolay görünmesini nasıl sağlayabiliriz?
Bir yol son bölümle aynı yaklaşımı kullanmaktır: daha ince eğilimleri görmeyi zorlaştıran güçlü bir sinyal (genel doğrusal büyüme) var. Doğrusal eğilime sahip bir modele uyarak bu faktörleri ayıracağız. Model zamanla istikrarlı bir şekilde büyür ve artıklar bize geriye kalanları gösterecektir.
Eğer elimizde tek bir ülke var ise bunu nasıl yapacağımızı zaten biliyoruz:
nz <- filter(gapminder, country == "New Zealand")
nz %>%
ggplot(aes(year, lifeExp)) +
geom_line() +
ggtitle("Full data = ")
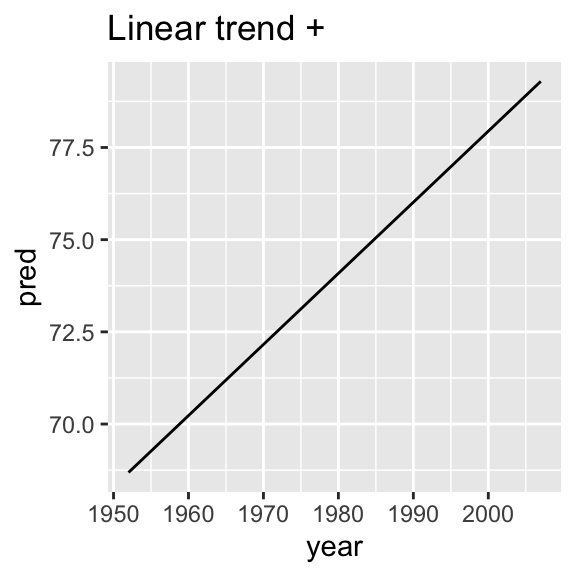
nz_mod <- lm(lifeExp ~ year, data = nz)
nz %>%
add_predictions(nz_mod) %>%
ggplot(aes(year, pred)) +
geom_line() +
ggtitle("Linear trend + ")
nz %>%
add_residuals(nz_mod) %>%
ggplot(aes(year, resid)) +
geom_hline(yintercept = 0, colour = "white", size = 3) +
geom_line() +
ggtitle("Remaining pattern")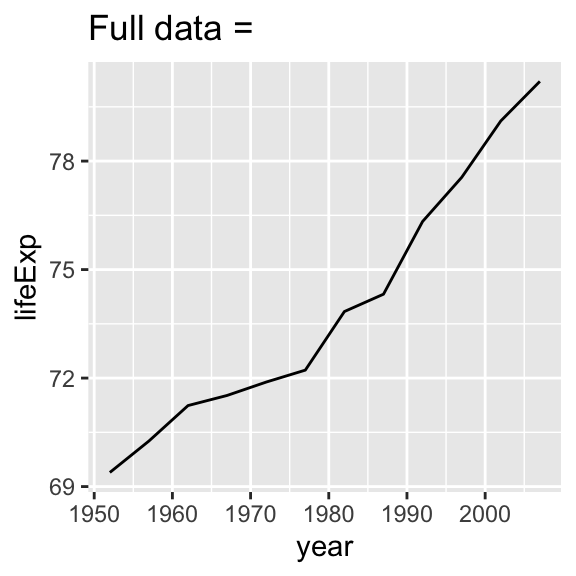
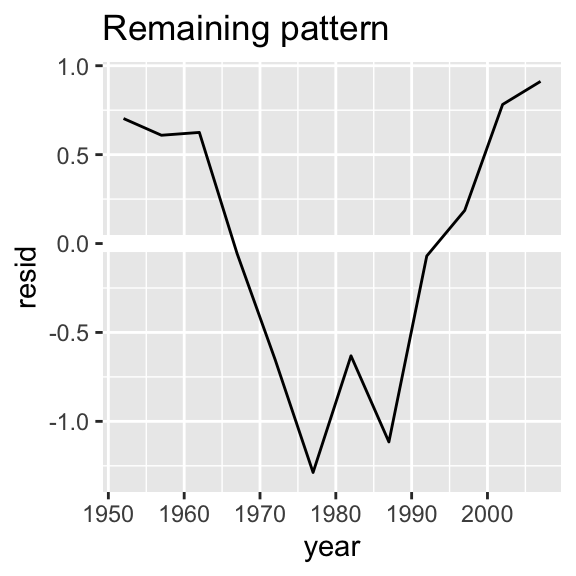
Bu modeli her ülkeye kolayca nasıl uydurabiliriz?
25.2.1 İç içe veri
Bu kodu birden çok defa kopyalayıp yapıştırmayı düşünebilirsiniz; ama çoktan daha iyi bir yol öğrendiniz! Ortak kodu bir fonksiyon ile çıkarın ve purrr’deki harita işlevini kullanarak tekrarlayın. Bu problem daha önce gördüğünüzden biraz farklı şekilde yapılandırılmıştır. Her değişken için bir işlemi tekrarlamak yerine her ülke için bir işlemi tekrarlamak istiyoruz, yani bir satır alt kümesi için. Bunu yapmak için yeni bir veri yapısına ihtiyacımız var: iç içe veri tablosu. İç içe veri tablosu oluşturmak için bir gruplanmış veri tablosu ile başlıyoruz ve daha sonra onu iç içe hale getiriyoruz:
by_country <- gapminder %>%
group_by(country, continent) %>%
nest()
by_country
#> # A tibble: 142 × 3
#> # Groups: country, continent [142]
#> country continent data
#> <fct> <fct> <list>
#> 1 Afghanistan Asia <tibble [12 × 4]>
#> 2 Albania Europe <tibble [12 × 4]>
#> 3 Algeria Africa <tibble [12 × 4]>
#> 4 Angola Africa <tibble [12 × 4]>
#> 5 Argentina Americas <tibble [12 × 4]>
#> 6 Australia Oceania <tibble [12 × 4]>
#> # … with 136 more rows(continent ve country’yi birlikte gruplayarak biraz hile yapıyorum. Verilen continent, country sabit olduğu için daha fazla grup eklenmiyor fakat işlem boyunca bir ekstra değişken taşımak kolay bir yol.)
Bu, grup başına bir satır (ülke başına) ve sıra dışı bir sütuna data (veri tablosu) sahip bir veri tablosu oluşturur. data veri tablolarının (kesin konuşmak gerekirse tibble) bir listesidir. Bu çılgın bir fikir gibi görünüyor: bir sütunu veri tablolarından oluşan bir listeye sahip bir veri tablosuna sahibiz! Bunun neden iyi bir fikir olduğunu kısaca açıklayacağım.
data sütunu bakmak için biraz aldatıcıdır çünkü kısmen karmaşık bir liste ve hala bu nesneleri keşfetmek için iyi araçlar üzerinde çalışıyoruz. Ne yazık ki str()’yi kullanmak çoğunlukla çok uzun çıktılar meydana getireceği için önerilmez. Ancak data sütunundan tek bir öğe çıkarırsanız o ülke için tüm verilerini içerdiğini göreceksiniz (bu örnekte Afganistan).
by_country$data[[1]]
#> # A tibble: 12 × 4
#> year lifeExp pop gdpPercap
#> <int> <dbl> <int> <dbl>
#> 1 1952 28.8 8425333 779.
#> 2 1957 30.3 9240934 821.
#> 3 1962 32.0 10267083 853.
#> 4 1967 34.0 11537966 836.
#> 5 1972 36.1 13079460 740.
#> 6 1977 38.4 14880372 786.
#> # … with 6 more rowsStandart bir gruplanmış veri tablosu ve bir iç içe veri tablosu arasındaki farkı not edin: gruplanmış bir veri tablosunda her satır bir gözlemdir, iç içe veri tablosunda her satır ise bir gruptur. İç içe bir veri seti hakkında düşünmenin bir başka yolu artık bir meta-gözlemimizin olduğunu düşünmektir: satır, bir ülke için zaman içinde bir noktadan ziyade tüm süreci temsil eder.
25.2.2 Liste-sütunlar
Şimdi iç içe geçmiş veri tablomuza sahip olduğumuza göre, bazı modelleri uygulayabilecek konumdayız. Modele uygun bir fonksiyonumuz var:
country_model <- function(df) {
lm(lifeExp ~ year, data = df)
}Ve bunu her veri tablosuna uygulamak istiyoruz. Veri tabloları listenin içinde, o yüzden country_model’i her elemente uygulamak için purrr::map() kullanabiliriz.
models <- map(by_country$data, country_model)Ancak, modeller listesini serbest dolaşan bir obje olarak bırakmak yerine, by_country veri tablosunda bir sütun olarak saklamanın daha iyi olacağını düşünüyorum. İlgili nesneleri sütunlarda saklamak veri tablolarının önemli bir özelliğidir. Bu yüzden liste-sütunlarının çok iyi bir fikir olduğunu düşünüyorum. Bu ülkelerle çalışırken her ülkede bir elementin bulunduğu birçok listemiz olacak. Peki neden hepsini bir veri tablosunda saklamıyoruz?
Başka bir deyişle, küresel ortamda yeni bir nesne oluşturmak yerine by_country veri tablosunda yeni bir değişken yaratacağız. Bu dplyr::mutate()’in işi:
by_country <- by_country %>%
mutate(model = map(data, country_model))
by_country
#> # A tibble: 142 × 4
#> # Groups: country, continent [142]
#> country continent data model
#> <fct> <fct> <list> <list>
#> 1 Afghanistan Asia <tibble [12 × 4]> <lm>
#> 2 Albania Europe <tibble [12 × 4]> <lm>
#> 3 Algeria Africa <tibble [12 × 4]> <lm>
#> 4 Angola Africa <tibble [12 × 4]> <lm>
#> 5 Argentina Americas <tibble [12 × 4]> <lm>
#> 6 Australia Oceania <tibble [12 × 4]> <lm>
#> # … with 136 more rowsBunun büyük bir avantajı var: çünkü ilgili tüm nesneler bir arada saklandığından filtrelerken veya düzenlerken bunları el ile senkronize etmenize gerek kalmaz. Veri tablosunun anlambilimi bunu sizin için önemser:
by_country %>%
filter(continent == "Europe")
#> # A tibble: 30 × 4
#> # Groups: country, continent [30]
#> country continent data model
#> <fct> <fct> <list> <list>
#> 1 Albania Europe <tibble [12 × 4]> <lm>
#> 2 Austria Europe <tibble [12 × 4]> <lm>
#> 3 Belgium Europe <tibble [12 × 4]> <lm>
#> 4 Bosnia and Herzegovina Europe <tibble [12 × 4]> <lm>
#> 5 Bulgaria Europe <tibble [12 × 4]> <lm>
#> 6 Croatia Europe <tibble [12 × 4]> <lm>
#> # … with 24 more rows
by_country %>%
arrange(continent, country)
#> # A tibble: 142 × 4
#> # Groups: country, continent [142]
#> country continent data model
#> <fct> <fct> <list> <list>
#> 1 Algeria Africa <tibble [12 × 4]> <lm>
#> 2 Angola Africa <tibble [12 × 4]> <lm>
#> 3 Benin Africa <tibble [12 × 4]> <lm>
#> 4 Botswana Africa <tibble [12 × 4]> <lm>
#> 5 Burkina Faso Africa <tibble [12 × 4]> <lm>
#> 6 Burundi Africa <tibble [12 × 4]> <lm>
#> # … with 136 more rowsVeri tablosu listeniz ve model listeniz ayrı nesneler ise bir vektörü ne zaman yeniden sıralar ya da alt küme ayarlarsanız bunları senkronize tutmak yerine diğerlerini tekrar sıralamanız ya da alt kümelemeniz gerektiğini unutmayın. Eğer bunu unutursanız kodunuz çalışmaya devam edecek ama yanlış sonuçlar verecektir.
25.2.3 İç içelikten kurtarma
Daha önce tek bir modelin kalıntılarını tek bir veri setiyle hesapladık. Şimdi 142 veri tablomuz ve 142 modelimiz var. Artıkları hesaplamak için her model-veri çifti ile birlikte ’add_residuals () `’ı çağırmamız gerekir:
by_country <- by_country %>%
mutate(
resids = map2(data, model, add_residuals)
)
by_country
#> # A tibble: 142 × 5
#> # Groups: country, continent [142]
#> country continent data model resids
#> <fct> <fct> <list> <list> <list>
#> 1 Afghanistan Asia <tibble [12 × 4]> <lm> <tibble [12 × 5]>
#> 2 Albania Europe <tibble [12 × 4]> <lm> <tibble [12 × 5]>
#> 3 Algeria Africa <tibble [12 × 4]> <lm> <tibble [12 × 5]>
#> 4 Angola Africa <tibble [12 × 4]> <lm> <tibble [12 × 5]>
#> 5 Argentina Americas <tibble [12 × 4]> <lm> <tibble [12 × 5]>
#> 6 Australia Oceania <tibble [12 × 4]> <lm> <tibble [12 × 5]>
#> # … with 136 more rowsPeki veri tablolarının bir listesini nasıl çizebilirsiniz? Bu soruyu cevaplamak ile uğraşmak yerine veri tablosu listesini sıradan bir veri tablosuna geri dönüştürelim. Daha önce sıradan bir veri tablosunu iç içe bir veri tablosuna dönüştürmek için nest ()’i kullanıyorduk ve şimdi tam tersini unnest() ile yapıyoruz.
resids <- unnest(by_country, resids)
resids
#> # A tibble: 1,704 × 9
#> # Groups: country, continent [142]
#> country continent data model year lifeExp pop gdpPercap resid
#> <fct> <fct> <list> <list> <int> <dbl> <int> <dbl> <dbl>
#> 1 Afghanistan Asia <tibble> <lm> 1952 28.8 8425333 779. -1.11
#> 2 Afghanistan Asia <tibble> <lm> 1957 30.3 9240934 821. -0.952
#> 3 Afghanistan Asia <tibble> <lm> 1962 32.0 10267083 853. -0.664
#> 4 Afghanistan Asia <tibble> <lm> 1967 34.0 11537966 836. -0.0172
#> 5 Afghanistan Asia <tibble> <lm> 1972 36.1 13079460 740. 0.674
#> 6 Afghanistan Asia <tibble> <lm> 1977 38.4 14880372 786. 1.65
#> # … with 1,698 more rowsHer normal sütunun iç içe sütundaki her satır için bir kez tekrarlandığını unutmayın.
Şimdi sıradan bir veri tablosuna sahibiz, artıkları çizebiliriz:
resids %>%
ggplot(aes(year, resid)) +
geom_line(aes(group = country), alpha = 1 / 3) +
geom_smooth(se = FALSE)
#> `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'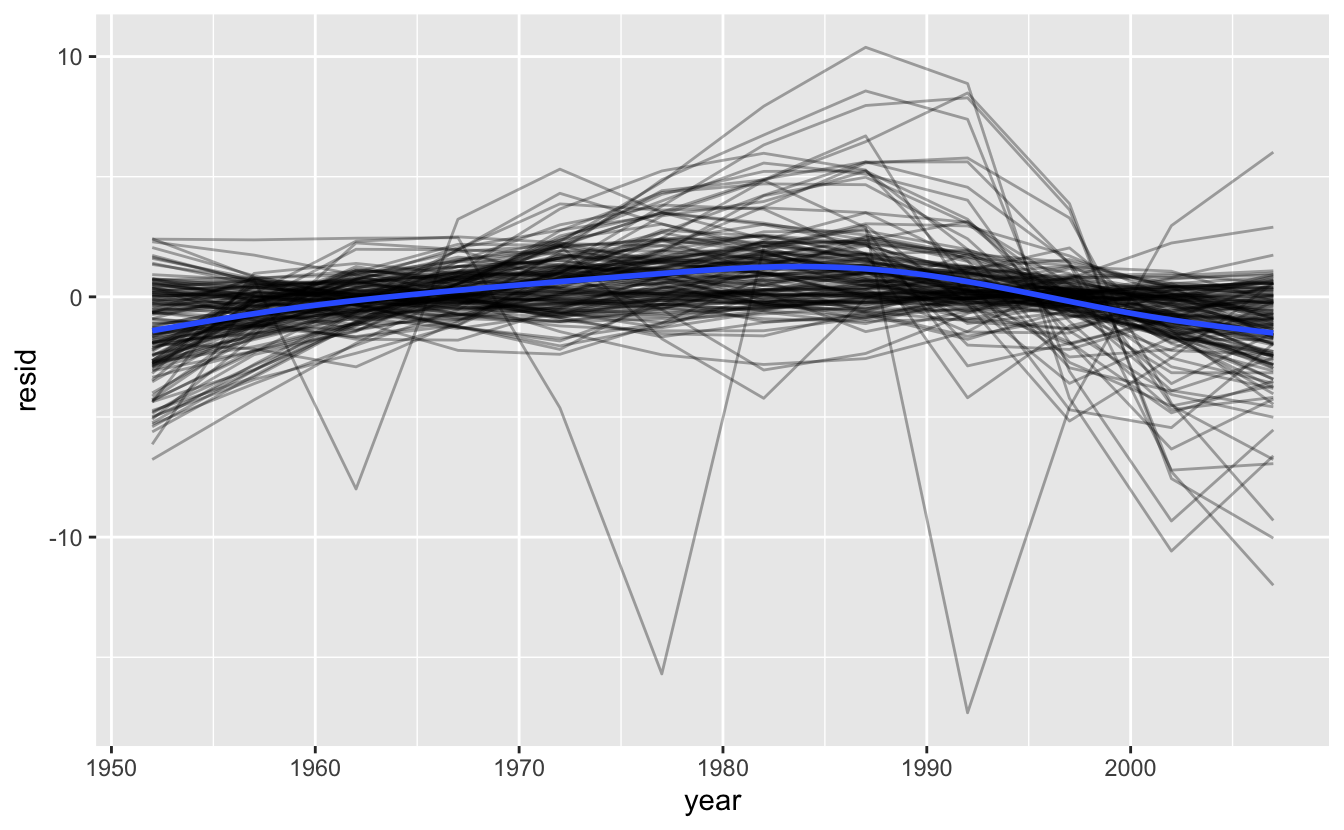
Kıtaya göre ayırmak özellikle açıklayıcı:
resids %>%
ggplot(aes(year, resid, group = country)) +
geom_line(alpha = 1 / 3) +
facet_wrap(~continent)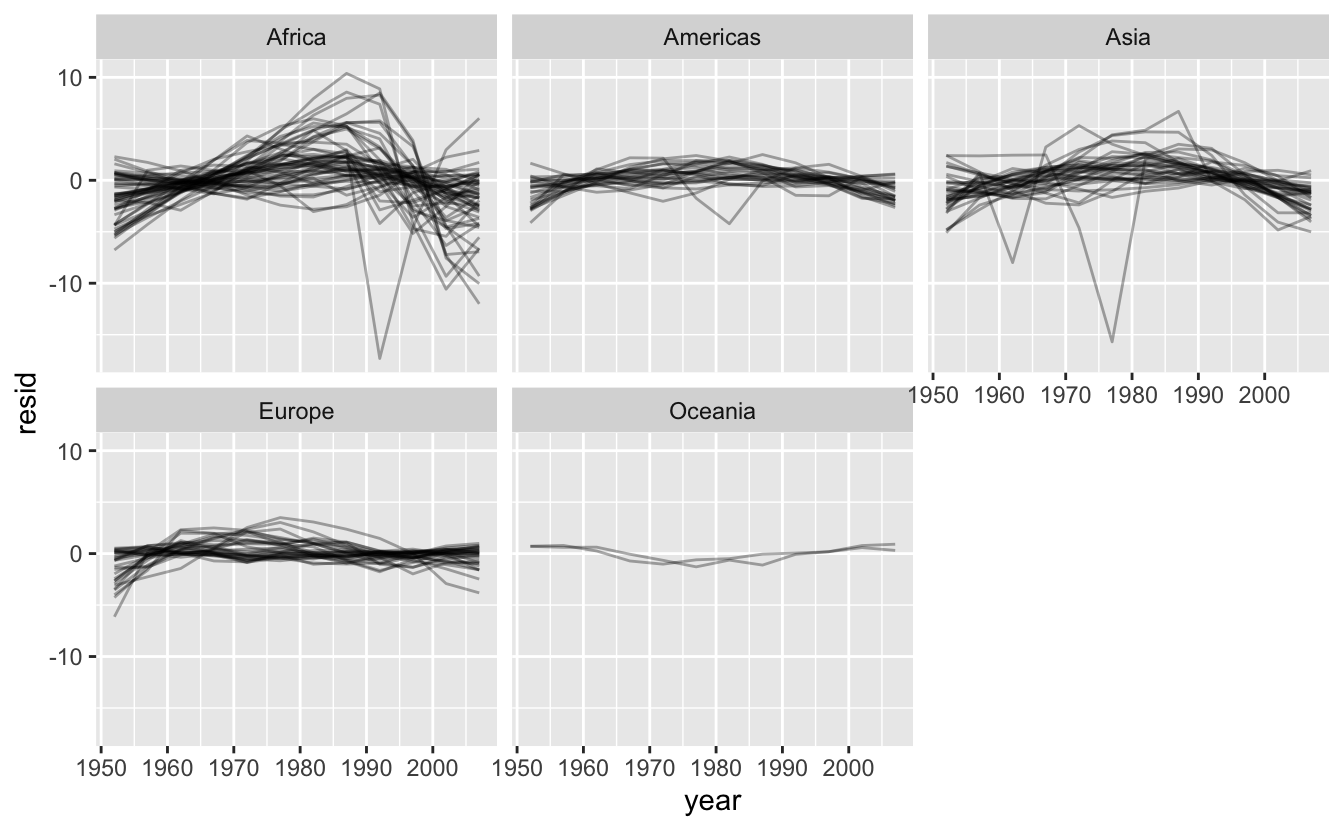
Görünüşe göre bazı hafif örüntüleri kaçırdık. Afrika’da da ilginç şeyler oluyor: modelimizin o kadar iyi uymadığını gösteren çok büyük bazı kalıntıları görüyoruz. Bunu bir sonraki bölümde biraz daha farklı bir açıdan atağa geçerek keşfedeceğiz.
25.2.4 Model kalitesi
Modelden kalanlara bakmak yerine, model kalitesinin bazı genel ölçümlerine bakabiliriz. Önceki bölümde bazı özel ölçümlerin nasıl hesaplanacağını öğrendiniz. Burada broom paketini kullanarak farklı bir yaklaşım göstereceğiz. broom paketi, modelleri düzenli veriye dönüştürmek için genel bir fonksiyon kümesi sağlar. Burada bazı model kalitesi ölçümlerini çıkarmak için broom :: glance ()’i kullanacağız. Eğer bunu bir modele uygularsak tek satırlı bir veri tablosu elde ederiz:
broom::glance(nz_mod)
#> # A tibble: 1 × 12
#> r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0.954 0.949 0.804 205. 0.0000000541 1 -13.3 32.6 34.1
#> # … with 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>Her ülke için bir satır ile veri tablosu oluşturmak için mutate () ve unnest ()’i kullanabiliriz:
by_country %>%
mutate(glance = map(model, broom::glance)) %>%
unnest(glance)
#> # A tibble: 142 × 17
#> # Groups: country, continent [142]
#> country continent data model resids r.squared adj.r.squared sigma
#> <fct> <fct> <list> <list> <list> <dbl> <dbl> <dbl>
#> 1 Afghanistan Asia <tibble> <lm> <tibble> 0.948 0.942 1.22
#> 2 Albania Europe <tibble> <lm> <tibble> 0.911 0.902 1.98
#> 3 Algeria Africa <tibble> <lm> <tibble> 0.985 0.984 1.32
#> 4 Angola Africa <tibble> <lm> <tibble> 0.888 0.877 1.41
#> 5 Argentina Americas <tibble> <lm> <tibble> 0.996 0.995 0.292
#> 6 Australia Oceania <tibble> <lm> <tibble> 0.980 0.978 0.621
#> # … with 136 more rows, and 9 more variables: statistic <dbl>, p.value <dbl>,
#> # df <dbl>, logLik <dbl>, AIC <dbl>, BIC <dbl>, deviance <dbl>,
#> # df.residual <int>, nobs <int>Bu tam olarak istediğimiz çıktı değil çünkü hala tüm liste sütunlarını içeriyor. Bu, unnest()’in tek satır veri tabloları üzerinde çalıştığı zamanki varsayılan davranışıdır. Bu sütunları gizlemek için .drop = TRUE kullanıyoruz:
glance <- by_country %>%
mutate(glance = map(model, broom::glance)) %>%
unnest(glance, .drop = TRUE)
#> Warning: The `.drop` argument of `unnest()` is deprecated as of tidyr 1.0.0.
#> All list-columns are now preserved.
#> This warning is displayed once every 8 hours.
#> Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.
glance
#> # A tibble: 142 × 17
#> # Groups: country, continent [142]
#> country continent data model resids r.squared adj.r.squared sigma
#> <fct> <fct> <list> <list> <list> <dbl> <dbl> <dbl>
#> 1 Afghanistan Asia <tibble> <lm> <tibble> 0.948 0.942 1.22
#> 2 Albania Europe <tibble> <lm> <tibble> 0.911 0.902 1.98
#> 3 Algeria Africa <tibble> <lm> <tibble> 0.985 0.984 1.32
#> 4 Angola Africa <tibble> <lm> <tibble> 0.888 0.877 1.41
#> 5 Argentina Americas <tibble> <lm> <tibble> 0.996 0.995 0.292
#> 6 Australia Oceania <tibble> <lm> <tibble> 0.980 0.978 0.621
#> # … with 136 more rows, and 9 more variables: statistic <dbl>, p.value <dbl>,
#> # df <dbl>, logLik <dbl>, AIC <dbl>, BIC <dbl>, deviance <dbl>,
#> # df.residual <int>, nobs <int>(Basılmayan değişkenlere dikkat edin: orada birçok faydalı şey var.)
Elimizdeki bu veri tablosu ile uygun olmayan modelleri aramaya başlayabiliriz:
glance %>%
arrange(r.squared)
#> # A tibble: 142 × 17
#> # Groups: country, continent [142]
#> country continent data model resids r.squared adj.r.squared sigma
#> <fct> <fct> <list> <list> <list> <dbl> <dbl> <dbl>
#> 1 Rwanda Africa <tibble> <lm> <tibble> 0.0172 -0.0811 6.56
#> 2 Botswana Africa <tibble> <lm> <tibble> 0.0340 -0.0626 6.11
#> 3 Zimbabwe Africa <tibble> <lm> <tibble> 0.0562 -0.0381 7.21
#> 4 Zambia Africa <tibble> <lm> <tibble> 0.0598 -0.0342 4.53
#> 5 Swaziland Africa <tibble> <lm> <tibble> 0.0682 -0.0250 6.64
#> 6 Lesotho Africa <tibble> <lm> <tibble> 0.0849 -0.00666 5.93
#> # … with 136 more rows, and 9 more variables: statistic <dbl>, p.value <dbl>,
#> # df <dbl>, logLik <dbl>, AIC <dbl>, BIC <dbl>, deviance <dbl>,
#> # df.residual <int>, nobs <int>En kötü modellerin hepsi Afrika’da görünüyor. Bunu bir çizim ile iki kez kontrol edelim. Burada nispeten az sayıda gözlem ve ayrık değişken var, bu nedenle `geom_jitter () ’etkilidir:
glance %>%
ggplot(aes(continent, r.squared)) +
geom_jitter(width = 0.5)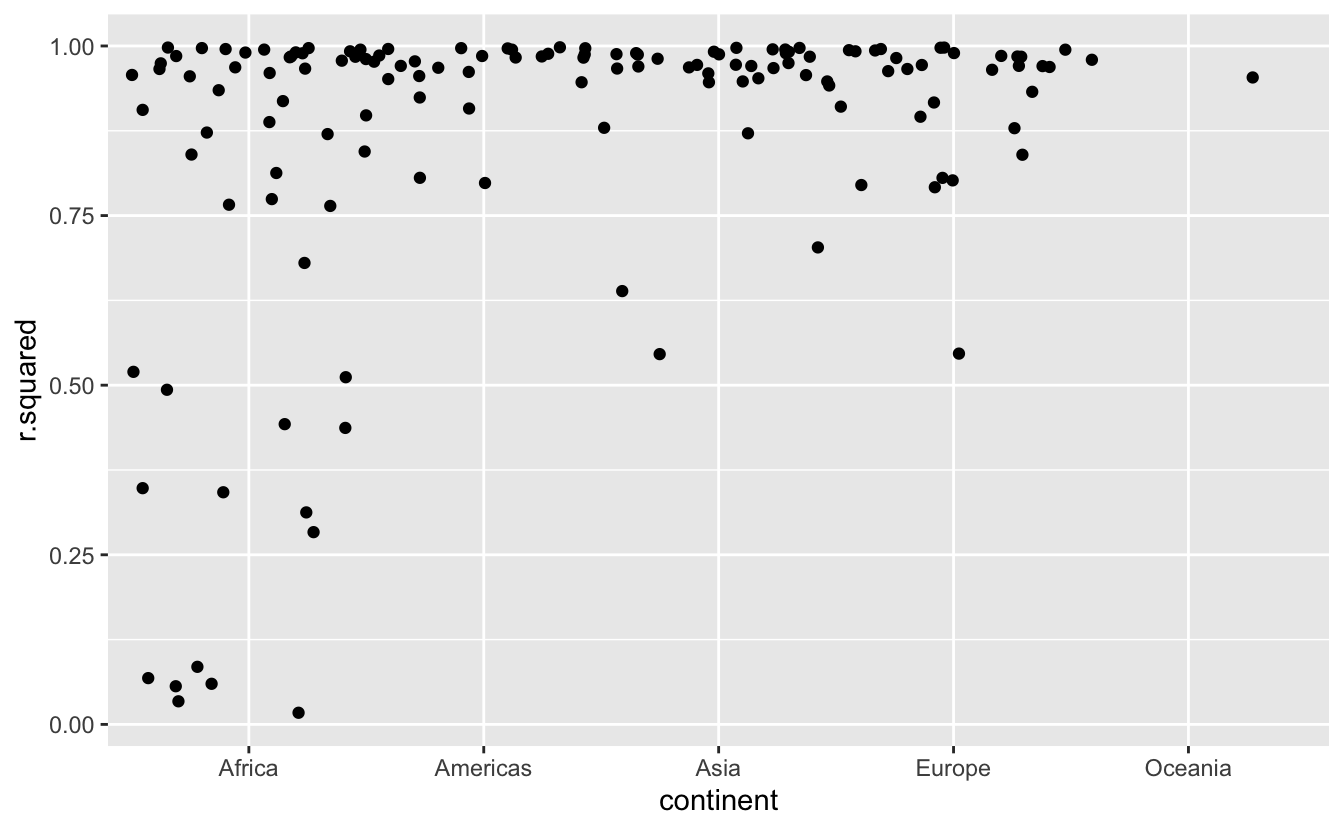
Özellikle \(R^2\)’si kötü ülkeleri çekip veriyi grafikleştirebiliriz:
bad_fit <- filter(glance, r.squared < 0.25)
gapminder %>%
semi_join(bad_fit, by = "country") %>%
ggplot(aes(year, lifeExp, colour = country)) +
geom_line()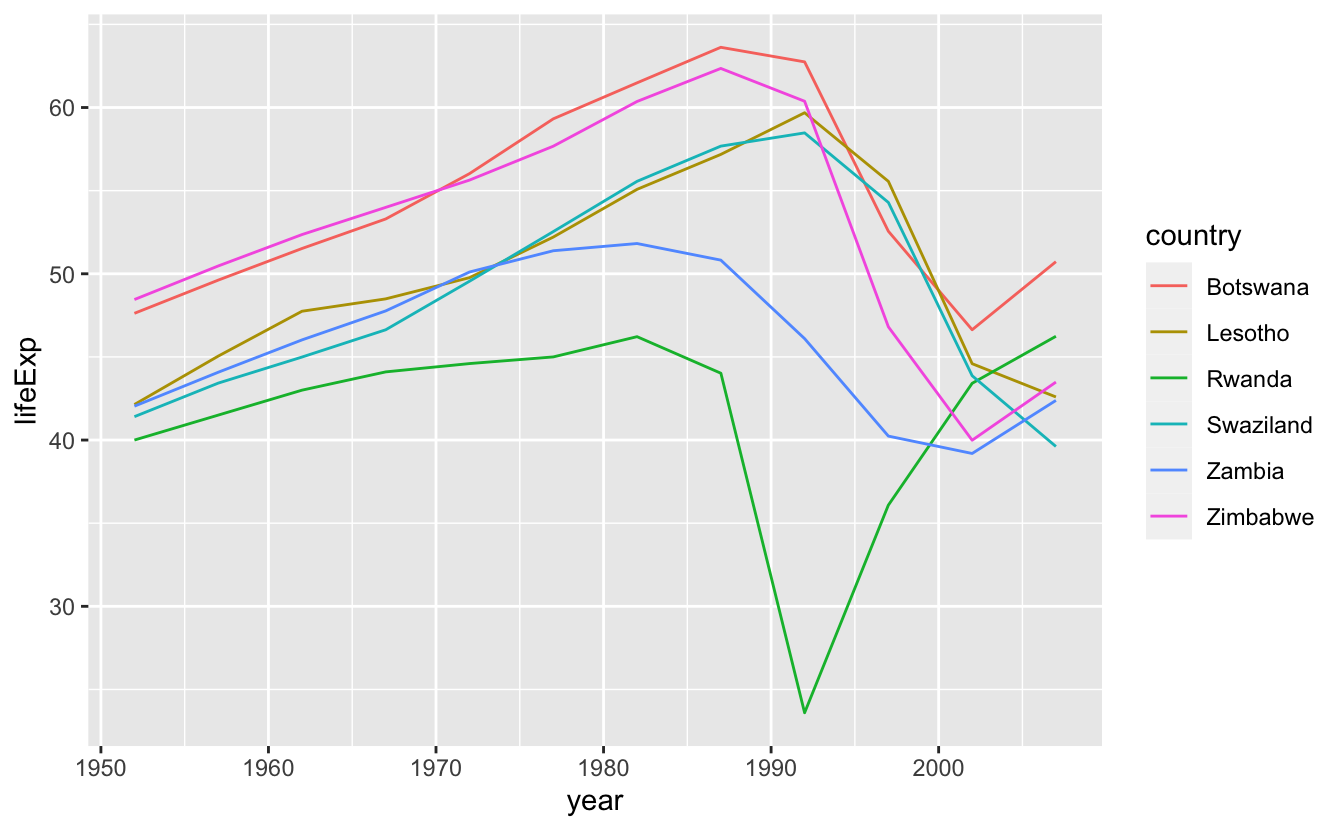
Burada iki ana etki görüyoruz: HIV / AIDS salgını trajedileri ve Ruanda soykırımı.
25.2.5 Alıştırmalar
Doğrusal bir eğilim genel eğilim için biraz fazla basit görünüyor. İkinci dereceden bir polinomla daha iyisini yapabilir misiniz? Kuadratik katsayıları nasıl yorumlayabilirsiniz? (İpucu:
year’ı değiştirmek isteyebilirsiniz böylece bu sıfır ortalaması olur.)Kıta başına \(R^2\) dağılımını görselleştirmek için diğer yöntemleri keşfedin. Çakışmalardan kaçınmak için jitter gibi benzer yöntemler sağlayan ancak belirleyici yöntemler kullanan ggbeeswarm paketini denemek isteyebilirsiniz.
Son grafiği oluşturmak için (en kötü modele uyan ülkelerin verilerini gösteren) iki adıma ihtiyacımız var: Ülke başına bir satır ile bir veri tablosu oluşturduk ve daha sonra orijinal veriyle yarı-birleştirme yaptık. Eğer
unnest(.drop = TRUE)yerineunnest()kullanırsak bunu önlemek mümkündür. Nasıl?
25.3 Liste-sütunlar
Artık birçok modeli yönetmek için temel iş akışını gördüğünüze göre, ayrıntılardan bazılarına geri dönelim. Bu bölümde, liste-sütun veri yapısını biraz daha detaylıca inceleyeceğiz. Ben ancak yakın zamanlarda liste-sütun fikrini gerçekten takdir etmeye başladım. Liste sütunlar veri tablosu tanımında gizlidir: bir veri tablosu eşit uzunluklu vektörlerin adlandırılmış bir listesidir. Bir liste bir vektördür, bu yüzden bir listeyi veri tablosunun bir sütunu olarak kullanmak her zaman mantıklı olmuştur. Bununla birlikte, temel R liste-sütunlar oluşturmayı kolaylaştırmaz ve data.frame () bir listeyi bir sütun listesi olarak değerlendirir.
data.frame(x = list(1:3, 3:5))
#> x.1.3 x.3.5
#> 1 1 3
#> 2 2 4
#> 3 3 5Data.frame ()’in bunu yapmasını I() ile engelleyebilirsiniz ancak sonuç pek de iyi yazdırılmaz:
data.frame(
x = I(list(1:3, 3:5)),
y = c("1, 2", "3, 4, 5")
)
#> x y
#> 1 1, 2, 3 1, 2
#> 2 3, 4, 5 3, 4, 5Tibble bu sorunu tembellikle (tibble () girdileri değiştirmez) ve daha iyi bir yazdırma yöntemi sağlayarak azaltır:
tibble(
x = list(1:3, 3:5),
y = c("1, 2", "3, 4, 5")
)
#> # A tibble: 2 × 2
#> x y
#> <list> <chr>
#> 1 <int [3]> 1, 2
#> 2 <int [3]> 3, 4, 5Tribble () `ile daha da kolay çünkü bir listeye ihtiyacınız olduğunu otomatik olarak anlayabilir:
tribble(
~x, ~y,
1:3, "1, 2",
3:5, "3, 4, 5"
)
#> # A tibble: 2 × 2
#> x y
#> <list> <chr>
#> 1 <int [3]> 1, 2
#> 2 <int [3]> 3, 4, 5Liste-sütunlar genellikle ara veri yapısı olarak en kullanışlıdır. Doğrudan çalışmak zordur çünkü çoğu R fonksiyonu atomik vektörler veya veri tabloları ile çalışır, ancak ilgili öğeleri veri tablosunda bir arada tutmanın avantajı biraz zahmete değer.
Genellikle etkili bir liste-sütun veri hattının üç bölümü vardır:
Liste-sütunlar oluşturma bölümünde açıklandığı gibi nest ()
,summarize ()+list ()veyamutate () `+ bir map fonksiyonunu kullanarak liste-sütun oluşturmak.Mevcut liste-sütunları
map (),map2 ()veyapmap ()ile dönüştürerek başka ara liste-sütunlar oluşturabilirsiniz. Örneğin, yukarıdaki örnekte veri tablolarından oluşan bir liste-sütununu dönüştürerek modellerden oluşan bir liste-sütun oluşturduk.Liste-sütunu [Liste-sütunlarını basitleştirme] bölümünde açıklandığı şekilde bir veri tablosuna veya atomik vektöre indirgemek.
25.4 Liste-sütunlar oluşturma
Genellikle, tibble () `ile liste-sütunlar oluşturmazsınız. Bunun yerine bu üç yöntemden birini kullanarak normal sütunlardan oluşturacaksınız:
tidyr :: nest ()ile gruplandırılmış bir veri tablosunu liste-sütun veri tablolarını içeren iç içe veri tablosuna dönüştürebilirsiniz.mutate ()ve bir liste veren vektörize fonksiyonlar ile.summarize ()ve birden fazla sonuç veren özet fonksiyonlar ile.
Alternatif olarak bunları tibble :: enframe () kullanarak isimlendirilmiş bir listeden oluşturabilirsiniz.
Genel olarak liste-sütunlar oluştururken homojen olduklarından emin olmalısınız: her öğe aynı türde bir şey içermelidir. Bunun doğru olduğundan emin olmak için herhangi bir kontrol yoktur, ancak purrr kullanıyorsanız ve tür-kararlı işlevler hakkında ne öğrendiğinizi hatırlıyorsanız bunun doğal olduğunu görmelisiniz.
25.4.1 İç içe koyarak
nest () veri tablolarının liste-sütunlarını içeren bir veri tablosu olan iç içe bir veri tablosu oluşturur. İç içe bir veri tablosunda her satır bir meta-gözlemdir: diğer sütunlar gözlemi tanımlayan değişkenleri (yukarıdaki ülke ve kıta gibi) verir ve veri tablolarının liste-sütunu meta-gözlemi oluşturan bireysel gözlemleri verir.
nest() kullanmak için iki yol vardır. Şimdiye kadar gruplandırılmış bir veri tablosu ile nasıl kullanılacağını gördünüz. Gruplandırılmış bir veri tablosuna uygulandığında nest() gruplama sütunlarını olduğu gibi tutar ve listedeki her şeyi bir araya getirir:
gapminder %>%
group_by(country, continent) %>%
nest()
#> # A tibble: 142 × 3
#> # Groups: country, continent [142]
#> country continent data
#> <fct> <fct> <list>
#> 1 Afghanistan Asia <tibble [12 × 4]>
#> 2 Albania Europe <tibble [12 × 4]>
#> 3 Algeria Africa <tibble [12 × 4]>
#> 4 Angola Africa <tibble [12 × 4]>
#> 5 Argentina Americas <tibble [12 × 4]>
#> 6 Australia Oceania <tibble [12 × 4]>
#> # … with 136 more rowsİç içe olmasını istediğiniz sütunları belirterek gruplandırılmamış bir veri çerçevesinde de kullanabilirsiniz:
gapminder %>%
nest(year:gdpPercap)
#> Warning: All elements of `...` must be named.
#> Did you want `data = year:gdpPercap`?
#> # A tibble: 142 × 3
#> country continent data
#> <fct> <fct> <list>
#> 1 Afghanistan Asia <tibble [12 × 4]>
#> 2 Albania Europe <tibble [12 × 4]>
#> 3 Algeria Africa <tibble [12 × 4]>
#> 4 Angola Africa <tibble [12 × 4]>
#> 5 Argentina Americas <tibble [12 × 4]>
#> 6 Australia Oceania <tibble [12 × 4]>
#> # … with 136 more rows25.4.2 Vektörize fonksiyonlardan
Bazı faydalı fonksiyonlar atomik bir vektörü alıp liste olarak verirler. Örneğin, dizgeler bölümünde bir karakter vektörünü alan ve karakter vektörlerinin bir listesini döndüren stringr :: str_split () hakkında bir şey öğrendiniz. Bunu mutate içinde kullanırsanız, bir liste-sütunu elde edersiniz:
df <- tribble(
~x1,
"a,b,c",
"d,e,f,g"
)
df %>%
mutate(x2 = stringr::str_split(x1, ","))
#> # A tibble: 2 × 2
#> x1 x2
#> <chr> <list>
#> 1 a,b,c <chr [3]>
#> 2 d,e,f,g <chr [4]>unnest() bu vektör listelerinin nasıl kullanılacağını bilir:
df %>%
mutate(x2 = stringr::str_split(x1, ",")) %>%
unnest()
#> Warning: `cols` is now required when using unnest().
#> Please use `cols = c(x2)`
#> # A tibble: 7 × 2
#> x1 x2
#> <chr> <chr>
#> 1 a,b,c a
#> 2 a,b,c b
#> 3 a,b,c c
#> 4 d,e,f,g d
#> 5 d,e,f,g e
#> 6 d,e,f,g f
#> # … with 1 more row(Kendinizi bu kalıbı çok kullanırken bulursanız, bu ortak örüntü etrafındaki bir örtü olan tidyr :: separa_rows () a baktığınızdan emin olun).
Bu kalıbın bir başka örneği purrr’den map (), map2 (), pmap () kullanmaktır. Örneğin, son örneği [farklı fonksiyonları uyarmak] ’tan alabilir ve mutate () kullanmak için yeniden yazabiliriz:
sim <- tribble(
~f, ~params,
"runif", list(min = -1, max = 1),
"rnorm", list(sd = 5),
"rpois", list(lambda = 10)
)
sim %>%
mutate(sims = invoke_map(f, params, n = 10))
#> # A tibble: 3 × 3
#> f params sims
#> <chr> <list> <list>
#> 1 runif <named list [2]> <dbl [10]>
#> 2 rnorm <named list [1]> <dbl [10]>
#> 3 rpois <named list [1]> <int [10]>Teknik olarak “sim”’in homojen olmadığını unutmayın, çünkü hem double hem de tam sayı vektörleri içerir. Bununla birlikte tam ve double sayıların her ikisinin de sayısal vektörler olması bunun birçok soruna yol açma olasılığını düşürüyor.
25.4.3 Birden fazla değerli özetlerden
Summarize () işlevinin bir kısıtlaması yalnızca tek bir değer döndüren özet işlevleriyle çalışmasıdır. Bu, değişken uzunluktaki bir vektör döndüren quantile () ’gibi fonksiyonlarla kullanamayacağınız anlamına gelir:
mtcars %>%
group_by(cyl) %>%
summarise(q = quantile(mpg))
#> `summarise()` has grouped output by 'cyl'. You can override using the `.groups`
#> argument.
#> # A tibble: 15 × 2
#> # Groups: cyl [3]
#> cyl q
#> <dbl> <dbl>
#> 1 4 21.4
#> 2 4 22.8
#> 3 4 26
#> 4 4 30.4
#> 5 4 33.9
#> 6 6 17.8
#> # … with 9 more rowsAncak sonucu bir listeye sarabilirsiniz! Bu, summarize ()’ın sözleşmesine uymaktadır çünkü her özet uzunluğu 1 olan bir listedir (bir vektör).
mtcars %>%
group_by(cyl) %>%
summarise(q = list(quantile(mpg)))
#> # A tibble: 3 × 2
#> cyl q
#> <dbl> <list>
#> 1 4 <dbl [5]>
#> 2 6 <dbl [5]>
#> 3 8 <dbl [5]>Unnest ile yararlı sonuçlar elde etmek için olasılıkları da yakalamanız gerekir:
probs <- c(0.01, 0.25, 0.5, 0.75, 0.99)
mtcars %>%
group_by(cyl) %>%
summarise(p = list(probs), q = list(quantile(mpg, probs))) %>%
unnest()
#> Warning: `cols` is now required when using unnest().
#> Please use `cols = c(p, q)`
#> # A tibble: 15 × 3
#> cyl p q
#> <dbl> <dbl> <dbl>
#> 1 4 0.01 21.4
#> 2 4 0.25 22.8
#> 3 4 0.5 26
#> 4 4 0.75 30.4
#> 5 4 0.99 33.8
#> 6 6 0.01 17.8
#> # … with 9 more rows25.4.4 Adlandırılmış bir listeden
Liste-sütunlara sahip veri tabloları ortak bir soruna çözüm sunar: Hem listenin içeriği hem de öğeleri üzerinde yineleme yapmak istiyorsanız ne yaparsınız? Her şeyi tek bir nesneye sıkıştırmaya çalışmak yerine veri tablosu oluşturmak genellikle daha kolaydır: bir sütun elemanları içerebilir ve bir sütun listeyi içerebilir. Listeden böyle bir veri tablosu oluşturmanın kolay bir yolu tibble :: enframe () dir.
x <- list(
a = 1:5,
b = 3:4,
c = 5:6
)
df <- enframe(x)
df
#> # A tibble: 3 × 2
#> name value
#> <chr> <list>
#> 1 a <int [5]>
#> 2 b <int [2]>
#> 3 c <int [2]>Bu yapının avantajı basit bir şekilde genelleşmesidir; isimler, meta veri karakter vektörüne sahipseniz kullanışlıdır ancak başka tür veri veya çoklu vektör varsa yardımcı olmaz.
Eğer isimler ve değerler üzerinde paralel bir şekilde yineleme yapmak istiyorsanız map2() kullanabilirsiniz.
df %>%
mutate(
smry = map2_chr(name, value, ~ stringr::str_c(.x, ": ", .y[1]))
)
#> # A tibble: 3 × 3
#> name value smry
#> <chr> <list> <chr>
#> 1 a <int [5]> a: 1
#> 2 b <int [2]> b: 3
#> 3 c <int [2]> c: 525.4.5 Alıştırmalar
Atomik bir vektörü girdi olarak alıp liste olarak geri veren fonksiyonlardan aklınıza gelenleri sıralayın.
‘quantile ()’ gibi birden fazla değer veren faydalı özet fonksiyonları üzerine beyin fırtınası yapın.
Aşağıdaki veri tablosunda eksik olan nedir?
quantile()bu eksik parçayı nasıl döndürür? Bu neden burada yardımcı olmuyor?mtcars %>% group_by(cyl) %>% summarise(q = list(quantile(mpg))) %>% unnest() #> Warning: `cols` is now required when using unnest(). #> Please use `cols = c(q)` #> # A tibble: 15 × 2 #> cyl q #> <dbl> <dbl> #> 1 4 21.4 #> 2 4 22.8 #> 3 4 26 #> 4 4 30.4 #> 5 4 33.9 #> 6 6 17.8 #> # … with 9 more rowsBu kod ne yapıyor? Neden faydalı olabilir?
mtcars %>% group_by(cyl) %>% summarise_each(funs(list))
25.5 Liste-sütunları sadeleştirme
Bu kitapta öğrendiğiniz veri manipülasyonu ve görselleştirme tekniklerini uygulamak için liste-sütununu normal bir sütuna (bir atomik vektör) veya sütunlar kümesine sadeleştirmeniz gerekir. Daha sade bir yapıya geri dönüştürmek için kullanacağınız teknik element başına tek bir değer mi yoksa birden çok değer mi istediğinize bağlıdır:
Tek bir değer istiyorsanız,
mutate ()’i,map_lgl ()kullanın, atomik bir vektör oluşturmak için map_int (), map_dbl (), ve map_chr ().Çok sayıda değer istiyorsanız liste-sütunları normal sütunlara geri dönüştürmek için
unnest ()kullanın ve satırları gerektiği kadar tekrarlayın.
Bunlar aşağıda daha ayrıntılı olarak açıklanmaktadır.
25.5.1 Listeden vektöre
Liste-sütununuzu bir atomik vektöre indirgeyebilirseniz normal bir sütun olacaktır. Örneğin, bir objeyi türüne ve uzunluğuna göre her zaman özetleyebilirsiniz; bu nedenle bu kod hangi tür liste-sütunu olduğuna bakılmaksızın çalışacaktır:
df <- tribble(
~x,
letters[1:5],
1:3,
runif(5)
)
df %>% mutate(
type = map_chr(x, typeof),
length = map_int(x, length)
)
#> # A tibble: 3 × 3
#> x type length
#> <list> <chr> <int>
#> 1 <chr [5]> character 5
#> 2 <int [3]> integer 3
#> 3 <dbl [5]> double 5Bu, varsayılan tbl yazdırma yönteminden edindiğiniz temel bilgi ile aynı ancak şimdi filtrelemek için kullanabilirsiniz. Heterojen bir listeniz varsa ve sizin için çalışmayan kısımları filtrelemek istiyorsanız bu yararlı bir tekniktir.
Map _ * () kısayollarını unutmayın - Her x elementi için apple içinde depolanan dizgeyi çıkarmak için map_chr (x," apple ") kullanabilirsiniz. Bu, iç içe listeleri sıradan sütunlara ayırmak için kullanışlıdır. Eğer öğe eksikse kullanılacak bir değer sağlamak için .null argümanını kullanın (NULL döndürmek yerine):
df <- tribble(
~x,
list(a = 1, b = 2),
list(a = 2, c = 4)
)
df %>% mutate(
a = map_dbl(x, "a"),
b = map_dbl(x, "b", .null = NA_real_)
)
#> # A tibble: 2 × 3
#> x a b
#> <list> <dbl> <dbl>
#> 1 <named list [2]> 1 2
#> 2 <named list [2]> 2 NA25.5.2 İç içelikten kurtarmak
unnest(), liste-sütununun her bir öğesi için normal sütunları bir kez tekrarlayarak çalışır. Örneğin, aşağıdaki çok basit örnekte ilk satırı 4 kez tekrar ediyoruz (çünkü y nin ilk öğesinin uzunluğu 4’dür) ve ikinci satırı bir kez:
tibble(x = 1:2, y = list(1:4, 1)) %>% unnest(y)
#> # A tibble: 5 × 2
#> x y
#> <int> <dbl>
#> 1 1 1
#> 2 1 2
#> 3 1 3
#> 4 1 4
#> 5 2 1Bu, farklı sayıda öğe içeren iki sütunu aynı anda iç içelikten kurtaramayacağımız anlamına geliyor:
# Tamam çünkü y ve z her satırda aynı sayıda elemente sahip
df1 <- tribble(
~x, ~y, ~z,
1, c("a", "b"), 1:2,
2, "c", 3
)
df1
#> # A tibble: 2 × 3
#> x y z
#> <dbl> <list> <list>
#> 1 1 <chr [2]> <int [2]>
#> 2 2 <chr [1]> <dbl [1]>
df1 %>% unnest(y, z)
#> Warning: unnest() has a new interface. See ?unnest for details.
#> Try `df %>% unnest(c(y, z))`, with `mutate()` if needed
#> # A tibble: 3 × 3
#> x y z
#> <dbl> <chr> <dbl>
#> 1 1 a 1
#> 2 1 b 2
#> 3 2 c 3
# Çalışmıyor çünkü y ve x farklı sayıda elementlere sahip
df2 <- tribble(
~x, ~y, ~z,
1, "a", 1:2,
2, c("b", "c"), 3
)
df2
#> # A tibble: 2 × 3
#> x y z
#> <dbl> <list> <list>
#> 1 1 <chr [1]> <int [2]>
#> 2 2 <chr [2]> <dbl [1]>
df2 %>% unnest(y, z)
#> Warning: unnest() has a new interface. See ?unnest for details.
#> Try `df %>% unnest(c(y, z))`, with `mutate()` if needed
#> # A tibble: 4 × 3
#> x y z
#> <dbl> <chr> <dbl>
#> 1 1 a 1
#> 2 1 a 2
#> 3 2 b 3
#> 4 2 c 3Bu prensip veri tablolarının liste-sütunlarını iç içelikten kurtarırken uygulanır. Her satırdaki tüm veri tabloları aynı sayıda satıra sahip olduğu sürece çoklu liste-sütunlarını iç içelikten kurtarabiliriz.
25.6 broom ile düzenli veri oluşturma
broom paketi, modelleri düzenli veri tablolarına dönüştürmek için üç genel araç sunar:
broom :: glance (model)her model için bir satır döndürür. Her sütun bir model özeti verir: bir model kalite ölçüsü veya karmaşıklık veya ikisinin bir kombinasyonu.broom :: tidy (model), modeldeki her katsayı için bir satır döndürür. Her sütun tahmin veya değişkenlik hakkında bilgi verir.broom::augment(model, data)veri içindeki her satır için bir satır döndürür, artıklar gibi ekstra değerler ekler ve istatistikleri ekler.