12 Düzenli veri
12.1 Giriş
“Mutlu aileler birbirlerine benzerler, her mutsuz ailenin ise kendince bir mutsuzluğu vardır.” –– Leo Tolstoy
“Düzenli veri grupları birbirlerine benzerler ancak her düzensiz veri grubunun kendince bir düzensizliği vardır.” –– Hadley Wickham
Bu bölümde, R verilerinizi düzenli veri (tidy data) adı verilen yöntem ile nasıl tutarlı bir şekilde düzenleyebileceğinizi öğreneceksiniz. Verileri bu biçime getirmek biraz ön çalışma gerektiriyor ancak bu çalışma uzun vadede karşılığını verecektir. Düzenli veriniz ve tidyverse’deki paketler ile sizlere sunulmuş araçlar elinizin altında olduğunda, verilerinizi bir gösterimden diğer bir gösterime dönüştürmek için daha az zaman harcayacaksınız ve analitik sorgulamalarınız için daha fazla zamanınız olacak.
Bu bölüm, veri düzenlemeye ve tidyr paketi ile birlikte gelen araçlara ilişkin pratik bir giriş niteliğindedir. Eğer altında yatan teori ile ilgili daha fazla bilgi sahibi olmak isterseniz, Journal of Statistical Software’de yayımlanmış Düzenli Veri (Tidy Data) adlı makaleyi sevebilirsiniz. http://www.jstatsoft.org/v59/i10/paper.
12.2 Düzenli veri
Aynı veri birden fazla yöntem ile ifade edilebilir. Aşağıdaki 4 örnekte de görülebileceği gibi her bir veri grubu ülke (country), yıl (year), nüfus (population) ve vakalar (cases) olmak üzere 4 değişkeni gösteriyor ancak değerler her birinde farklı şekilde oluşturulmuş.
table1
#> # A tibble: 6 × 4
#> country year cases population
#> <chr> <int> <int> <int>
#> 1 Afghanistan 1999 745 19987071
#> 2 Afghanistan 2000 2666 20595360
#> 3 Brazil 1999 37737 172006362
#> 4 Brazil 2000 80488 174504898
#> 5 China 1999 212258 1272915272
#> 6 China 2000 213766 1280428583
table2
#> # A tibble: 12 × 4
#> country year type count
#> <chr> <int> <chr> <int>
#> 1 Afghanistan 1999 cases 745
#> 2 Afghanistan 1999 population 19987071
#> 3 Afghanistan 2000 cases 2666
#> 4 Afghanistan 2000 population 20595360
#> 5 Brazil 1999 cases 37737
#> 6 Brazil 1999 population 172006362
#> # … with 6 more rows
table3
#> # A tibble: 6 × 3
#> country year rate
#> * <chr> <int> <chr>
#> 1 Afghanistan 1999 745/19987071
#> 2 Afghanistan 2000 2666/20595360
#> 3 Brazil 1999 37737/172006362
#> 4 Brazil 2000 80488/174504898
#> 5 China 1999 212258/1272915272
#> 6 China 2000 213766/1280428583
# İki tibble boyunca dağıtılmış
table4a # cases
#> # A tibble: 3 × 3
#> country `1999` `2000`
#> * <chr> <int> <int>
#> 1 Afghanistan 745 2666
#> 2 Brazil 37737 80488
#> 3 China 212258 213766
table4b # population
#> # A tibble: 3 × 3
#> country `1999` `2000`
#> * <chr> <int> <int>
#> 1 Afghanistan 19987071 20595360
#> 2 Brazil 172006362 174504898
#> 3 China 1272915272 1280428583Aynı verinin sadece farklı şekildeki gösterimleri olsalar da kullanımları aynı derecede kolay değildir. Tek bir veri grubu yani düzenli veri ile tidyverse içinde çalışmak çok daha kolay olacaktır.
Bir veri grubunu düzenli hale getirmenin birbiri ile bağlantılı üç kuralı vardır:
- Her bir değişkenin kendine ait sütunu olmalı
- Her bir gözlemin kendine ait bir satırı olmalı
- Her bir değerin kendine ait bir hücresi olmalı
Bu kuralların gösterimi Figür 12.1 gibidir.

Figure 12.1: Değişkenler sütunlarda, gözlemler satırlarda ve her bir değer kendi hücresinde. Bu üç kural uygulandığında bir veri grubu düzenli olacaktır.
Bu üç kuraldan sadece ikisini yerine getirmek olanaksız olduğundan bu kurallar birbiri ile karşılıklı bir ilişki içindedirler. Bu ilişki daha da kolay ve pratik olan uygulamalara yol açar.
- Her bir veri grubunu bir tibble’a yerleştir.
- Her bir değişkeni bir sütuna yerleştir.
Bu örnekte sadece tablo1 düzenlidir çünkü her bir değişkenin kendine ait bir sütununun bulunduğu tek gösterimdir.
Neden verilerinizin düzenli olduğundan emin olmalısınız? İki ana faydası olacaktır:
Verileri saklarken tek bir tutarlı yol seçmenin genel bir faydası olacaktır. Tutarlı bir veri yapısının temelinde bir istikrar olacağından bu şekildeki veriler ile çalışan araçları öğrenmek daha kolay olacaktır.
Değişkenleri sütunlara yerleştirmenin bir avantajı da R’ın vektörel doğasının parlamasını sağlamasıdır. mutate ve summary fonksiyonlarında öğrendiğiniz gibi birçok dahili R fonksiyonu değerlerin vektörleri ile çalışır. Bu da düzenli verilerin dönüştürülmesini özellikle doğal hissettirir.
dplyr, ggplot2 ve tidyverse’deki tüm diğer paketler düzenli veri ile çalışmak üzere tasarlanmıştır. İşte tablo1 ile nasıl çalışabileceğinizi gösteren bir kaç ufak örnek.
# Compute rate per 10,000
table1 %>%
mutate(rate = cases / population * 10000)
#> # A tibble: 6 × 5
#> country year cases population rate
#> <chr> <int> <int> <int> <dbl>
#> 1 Afghanistan 1999 745 19987071 0.373
#> 2 Afghanistan 2000 2666 20595360 1.29
#> 3 Brazil 1999 37737 172006362 2.19
#> 4 Brazil 2000 80488 174504898 4.61
#> 5 China 1999 212258 1272915272 1.67
#> 6 China 2000 213766 1280428583 1.67
# Compute cases per year
table1 %>%
count(year, wt = cases)
#> # A tibble: 2 × 2
#> year n
#> <int> <int>
#> 1 1999 250740
#> 2 2000 296920
# Visualise changes over time
library(ggplot2)
ggplot(table1, aes(year, cases)) +
geom_line(aes(group = country), colour = "grey50") +
geom_point(aes(colour = country))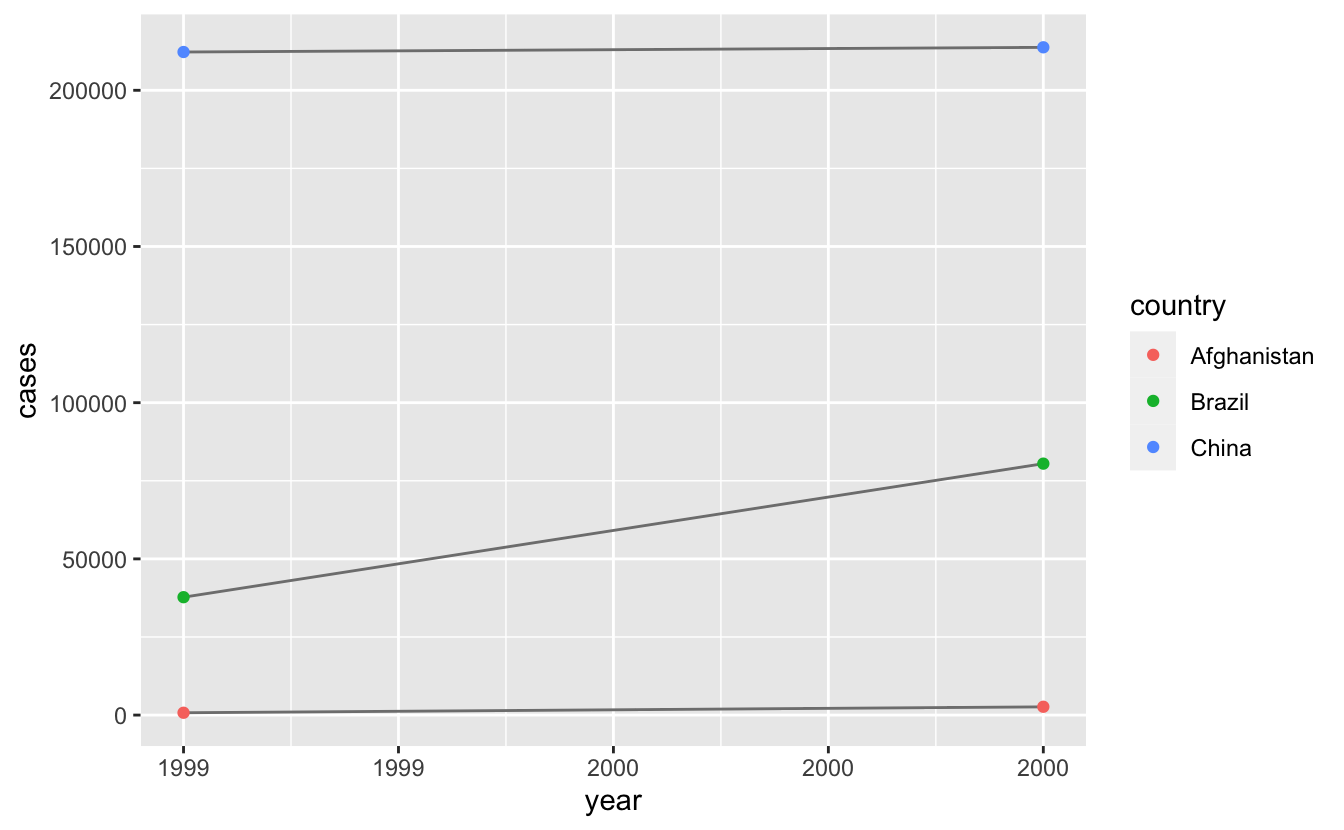
12.2.1 Alıştırmalar
Kesir kullanarak değişkenlerin ve gözlemlerin her bir örnek tabloda nasıl organize edildiğini tarif ediniz.
tablo2,tablo4avetablo4biçinoranı(rate) hesaplayınız. 4 işlem gerçekleştirmeniz gerekecektir:- TB vakalarının sayısını her bir ülke ve yıl için çekiniz.
- Buna karşılık gelen nüfusu her bir ülke ve yıl için çekiniz.
- Vakaları nüfusa bölüp 10000 ile çarpınız.
- Uygun bir yerde bu hesaplamayı depolayınız.
Üzerinde çalışması en kolay gösterim hangisi? En zoru hangisi? Neden?
Tablo1yerinetablo2’yi kullanarak vaka sayısının zaman içindeki değişimini gösteren grafiği tekrar çiziniz. Yapmanız gereken ilk şey nedir?
12.3 Yayma ve toparlama
Düzenli verinin prensipleri o kadar aşikar ki acaba düzenli olmayan bir veri grubu ile karşılaşacak mıyım diye düşünebilirsiniz. Ancak maalesef karşılaşacağınız birçok veri düzensiz olacaktır. Bunun iki temel nedeni:
Birçok kişi düzenli verinin prensiplerine aşina olmamakla birlikte, uzun bir süre veriler üstünde çalışmadığınız takdirde düzenli veriyi çıkarsamak sizin için zor olacaktır.
Veriler genellikle analizdense başka bir kullanımı kolaylaştırmak için, mesela veri girişinin en kolay şekilde gerçekleştirilebilmesi için düzenlenmiştir.
Bu demek oluyor ki birçok analiz için biraz düzenleme yapmanız gerekecektir. İlk aşama her zaman değişkenlerin ve gözlemlerin neler olduğunu anlamaktır. Bazen bu kolay olsa da, kimi zaman veriyi en başta oluşturan kişilere danışmanız gerekir.
İkinci aşama ise yaygın iki sorundan birini çözmek olacaktır:
Bir değişken birden fazla sütuna yayılmış olabilir.
Bir gözlem birden fazla satıra dağılmış olabilir.
Genellikle bir veri grubunda bu sorunlardan sadece biri olur. Eğer her iki sorundan da muzdarip ise gerçekten şanssızsınız demektir! Bu sorunları çözmek için tidyr’daki en önemli fonksiyonlardan gather() ve spread() fonskiyonlarına ihtiyacınız olacak.
12.3.1 Toparlama
Bir veri grubunda bazı sütun adlarının değişken isimleri yerine değişkenin değerleri olması yaygın bir problemdir. Tablo4a’yı ele alalım: 1999 ve 2000 sütun adları yıl (year) değişkeninin değerlerini temsilen kullanılmıştır ve her bir satır bir yerine iki gözlemi belirtmektedir.
table4a
#> # A tibble: 3 × 3
#> country `1999` `2000`
#> * <chr> <int> <int>
#> 1 Afghanistan 745 2666
#> 2 Brazil 37737 80488
#> 3 China 212258 213766Böyle bir veri grubunu düzenlemek için bu sütunları yeni bir çift değişken altında toparlamalıyız. Bu işlemi açıklamak için üç parametreye ihtiyacımız var:
Değişkenleri göstermek yerine değerleri gösteren sütunlar. Bu örnekte
1999ve2000sütunlarıdır.Sütun adlarını ortaya çıkaran değişkenin ismi. Ben buna
anahtardiyorum ve bu örnekteyıldeğişkenidir.Değerleri birçok hücreye dağılmış olan değişkenin ismi. Ben buna
değerdiyorum ve bu örnektevakalarınsayısıdır.
Bu parametreler ile gather() fonksiyonunu çağırabiliriz.
table4a %>%
gather(`1999`, `2000`, key = "year", value = "cases")
#> # A tibble: 6 × 3
#> country year cases
#> <chr> <chr> <int>
#> 1 Afghanistan 1999 745
#> 2 Brazil 1999 37737
#> 3 China 1999 212258
#> 4 Afghanistan 2000 2666
#> 5 Brazil 2000 80488
#> 6 China 2000 213766Bir araya getireceğimiz sütunları belirtmek için dplyr::select() stilinde gösterim yapacağız. Burada sadece iki kolon olduğundan onları ayrı ayrı listeleyeceğiz. “1999” ve “2000” sözdizimsel adlar olmadığından (çünkü bir harf ile başlamıyorlar) üst tırnak içine almamız gerektiğini not edelim. Sütunları seçmenin diğer yolları hakkında hafızanızı tazelemek için select bölümüne gidiniz.

Figure 12.2: Tablo4’u düzenli bir biçime toparlamak.
Sonuç olarak toparladığımız sütunlar düşerken anahtar ve değer olan yeni sütunlar elde ediyoruz. Ancak orjinal değişkenler arasındaki ilişki korunmuş oluyor. Bunun gösterimi Figür 12.2’de görülebilir. Tablo4b’yi düzenlemek için de benzer bir şekilde gather() fonksiyonunu kullanabiliriz.
Tek fark değişkenlerin hücrelerdeki değerleri olacaktır:
table4b %>%
gather(`1999`, `2000`, key = "year", value = "population")
#> # A tibble: 6 × 3
#> country year population
#> <chr> <chr> <int>
#> 1 Afghanistan 1999 19987071
#> 2 Brazil 1999 172006362
#> 3 China 1999 1272915272
#> 4 Afghanistan 2000 20595360
#> 5 Brazil 2000 174504898
#> 6 China 2000 1280428583Tablo4a ve tablo4b’nin düzenli hallerini tek bir tibble’da birleştirmek için ilişkisel veri bölümünde öğreneceğiniz üzere dplyr::left_join() kullanmamız gerekir.
tidy4a <- table4a %>%
gather(`1999`, `2000`, key = "year", value = "cases")
tidy4b <- table4b %>%
gather(`1999`, `2000`, key = "year", value = "population")
left_join(tidy4a, tidy4b)
#> Joining, by = c("country", "year")
#> # A tibble: 6 × 4
#> country year cases population
#> <chr> <chr> <int> <int>
#> 1 Afghanistan 1999 745 19987071
#> 2 Brazil 1999 37737 172006362
#> 3 China 1999 212258 1272915272
#> 4 Afghanistan 2000 2666 20595360
#> 5 Brazil 2000 80488 174504898
#> 6 China 2000 213766 128042858312.3.2 Yayma
Yayma toparlamanın tam tersidir. Bir gözlem birden fazla satıra dağılmış ise kullanılır. Tablo2’yi örnek alalım: her bir yıl için bir ülkeye ait gözlemler iki satıra dağılmış durumdalar.
table2
#> # A tibble: 12 × 4
#> country year type count
#> <chr> <int> <chr> <int>
#> 1 Afghanistan 1999 cases 745
#> 2 Afghanistan 1999 population 19987071
#> 3 Afghanistan 2000 cases 2666
#> 4 Afghanistan 2000 population 20595360
#> 5 Brazil 1999 cases 37737
#> 6 Brazil 1999 population 172006362
#> # … with 6 more rowsBunu düzenlemek için öncelikle gösterimi gather()’da yaptığımıza benzer bir şekilde analiz etmeliyiz. Ancak bu sefer sadece iki parametreye ihtiyacımız var:
Anahtar(key) sütunu, yani değişkenlerin isimlerinin bulunduğu sütun. Bu örnektetype.Değer(value) sütunu, yani birden fazla değişkenin değerlerinin bulunduğu sütun. Bu örnektecount.
Bunu anladığımızda Figür 12.3’de gösterimini bulabileceğiniz ve aşağıda programlanabilir bir şekilde gösterilmiş olan spread() fonksiyonunu kullanabiliriz.
table2 %>%
spread(key = type, value = count)
#> # A tibble: 6 × 4
#> country year cases population
#> <chr> <int> <int> <int>
#> 1 Afghanistan 1999 745 19987071
#> 2 Afghanistan 2000 2666 20595360
#> 3 Brazil 1999 37737 172006362
#> 4 Brazil 2000 80488 174504898
#> 5 China 1999 212258 1272915272
#> 6 China 2000 213766 1280428583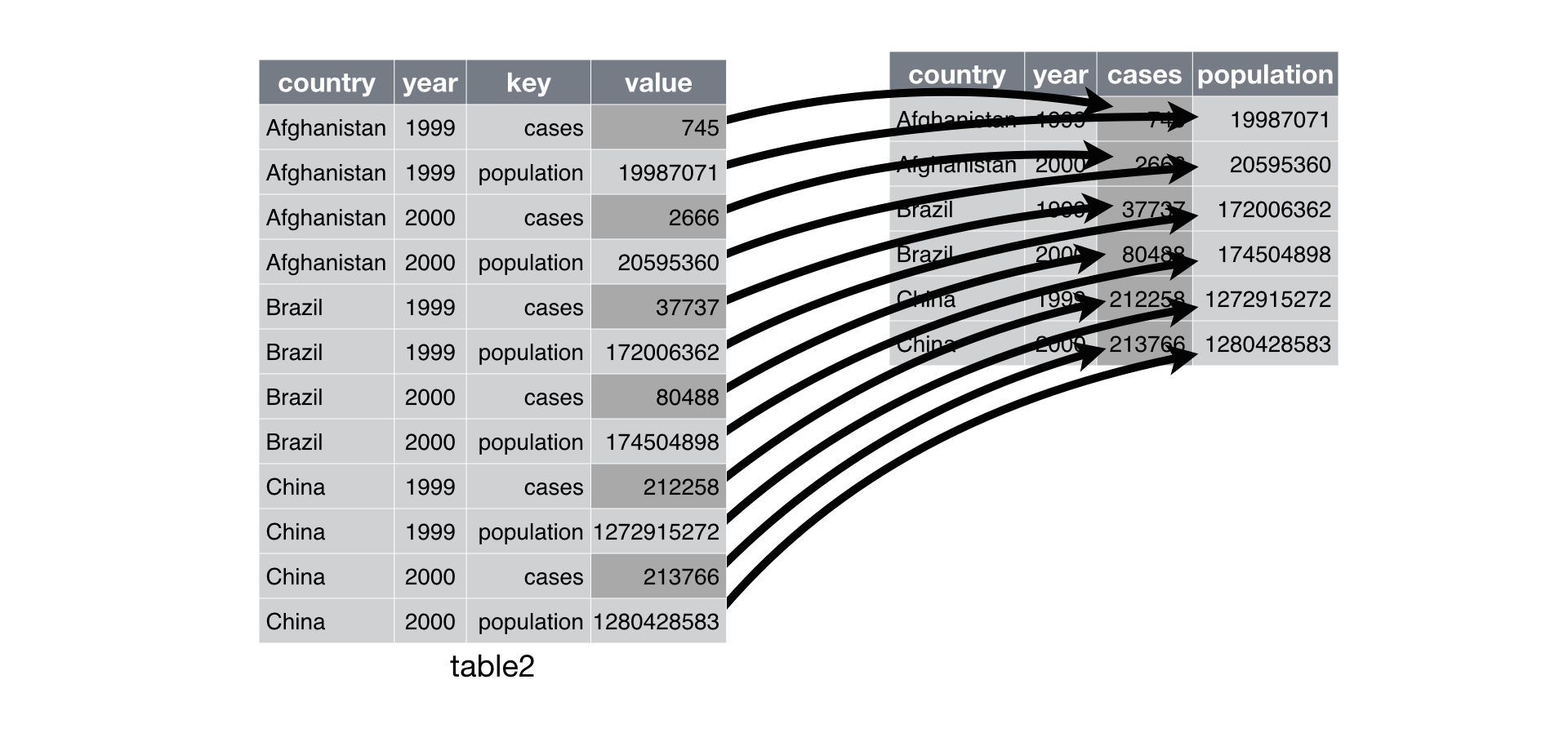
Figure 12.3: Tablo2’yi yaymak onu düzenli hale getirir
Ortak anahtar ve değer parametrelerinden de tahmin edilebileceği üzere spread() ve
gather() birbirini tamamlayıcı niteliktedirler. gather() geniş tabloları daraltıp uzatırken, spread() uzun tabloları kısaltıp genişletir.
12.3.3 Alıştırmalar
Neden
gather()vespread()mükemmel bir simetriye sahip değildirler? Aşağıdaki örneği dikkatlice inceleyiniz:stocks <- tibble( year = c(2015, 2015, 2016, 2016), half = c( 1, 2, 1, 2), return = c(1.88, 0.59, 0.92, 0.17) ) stocks %>% spread(year, return) %>% gather("year", "return", `2015`:`2016`)(İpucu: değişkenlerin türlerine dikkat ediniz ve sütun isimlerini düşününüz.)
Hem
spread()hem degather()’inconvertparametreleri vardır. Bu ne işe yarar?Bu kod neden sonuç vermiyor?
table4a %>% gather(1999, 2000, key = "year", value = "cases") #> Error in `loc_validate()`: #> ! Can't subset columns past the end. #> ℹ Locations 1999 and 2000 don't exist. #> ℹ There are only 3 columns.Bu tibble’ı yayma işlemi neden başarısızlıkla sonuçlanıyor? Bu problemi düzeltmek için nasıl bir sütun eklemelisiniz?
```r
people <- tribble(
~name, ~key, ~value,
#-----------------|--------|------
"Phillip Woods", "age", 45,
"Phillip Woods", "height", 186,
"Phillip Woods", "age", 50,
"Jessica Cordero", "age", 37,
"Jessica Cordero", "height", 156
)
```Aşağıdaki basit tibble’ı düzenleyiniz. Verileri yaymaya veya toparlamaya ihtiyaç var mı? Değişkenler nelerdir?
preg <- tribble( ~pregnant, ~male, ~female, "yes", NA, 10, "no", 20, 12 )
12.4 Ayırma ve birleştirme
Şu ana kadar tablo2 ve tablo4’ü nasıl düzenleyebileceğinizi öğrendiniz ancak tablo3’ü öğrenmediniz. Tablo3’ün farklı bir sorunu var: elimizde iki değişkeni (cases ve population) içeren bir sütun (rate) var. Bu sorunu çözmek için separate() fonksiyonuna ihtiyacımız olacak. Ayrıca tek bir değişken birden fazla sütuna dağılmış ise kullanacağınız separate() fonksiyonunun tamamlayıcısı olan unite() fonksiyonunu da öğreneceksiniz.
12.4.1 Ayırma
separate() nerede bir ayırıcı karakter kullanılmış ise oradan ayırmak koşulu ile tek bir sütunu birden fazla sütuna böler. Tablo3’ü ele alalım:
table3
#> # A tibble: 6 × 3
#> country year rate
#> * <chr> <int> <chr>
#> 1 Afghanistan 1999 745/19987071
#> 2 Afghanistan 2000 2666/20595360
#> 3 Brazil 1999 37737/172006362
#> 4 Brazil 2000 80488/174504898
#> 5 China 1999 212258/1272915272
#> 6 China 2000 213766/1280428583Oran (rate) sütunu hem vaka (cases) hem de nüfus (population) değişkenlerini içeriyor ve onu iki farklı değişkene ayırmamız gerekiyor. Figür 12.4 ve aşağıdaki kodda gösterildiği üzere separate() fonksiyonu ayrılması istenen sütunun ismini ve ayrılacağında alacağı sütun isimlerini içerir.
table3 %>%
separate(rate, into = c("cases", "population"))
#> # A tibble: 6 × 4
#> country year cases population
#> <chr> <int> <chr> <chr>
#> 1 Afghanistan 1999 745 19987071
#> 2 Afghanistan 2000 2666 20595360
#> 3 Brazil 1999 37737 172006362
#> 4 Brazil 2000 80488 174504898
#> 5 China 1999 212258 1272915272
#> 6 China 2000 213766 1280428583
Figure 12.4: Tablo3’ü ayırmak onu düzenli hale getirir.
Aksi belirtilmediği takdirde separate() alfanumerik bir karakter (rakam veya harf harici bir karakter) ile karşılaştığında değerleri ayırır. Örneğin yukarıdaki kodda separate() oran (rate) sütünündaki değerleri taksim işaretinin olduğu yerden ayıracaktır. Eğer sütunu ayırmak istediğiniz belirli bir karakter varsa bu karakteri sep parametresinde onaylayabilirsiniz. Mesela yukarıdaki kod aşağıdaki gibi tekrar yazılabilir:
table3 %>%
separate(rate, into = c("cases", "population"), sep = "/")(sep daha sonra dizgeler bölümünde öğreneceğiniz kurallı bir ifadedir.)
Sütunların türüne dikkatlice bakıltığınızda vakalar’ın (cases) ve populasyon’un (population) karakter cinsinden olduklarını fark edeceksiniz. separate() fonksiyonunun olağan davranışı sütunun türünü değiştirmemesidir. Ancak bu örnekte sütunların içerikleri rakam olduklarından bu davranış pek işimize yaramaz. separate() fonksiyonundan convert = TRUE’yu kullanarak türleri çevirmesini isteyebiliriz:
table3 %>%
separate(rate, into = c("cases", "population"), convert = TRUE)
#> # A tibble: 6 × 4
#> country year cases population
#> <chr> <int> <int> <int>
#> 1 Afghanistan 1999 745 19987071
#> 2 Afghanistan 2000 2666 20595360
#> 3 Brazil 1999 37737 172006362
#> 4 Brazil 2000 80488 174504898
#> 5 China 1999 212258 1272915272
#> 6 China 2000 213766 1280428583Ayrıca sep parametresine tam sayı vektörü de atayabilirsiniz. separate() bu tamsayı ile hangi pozisyondan bölmesi gerektiğini çıkaracaktır. 1’den başlayan pozitif değerler dizinin en solundan, -1’den başlayan negatif değerler ise dizinin en sağından başlayacaktır. Dizileri ayırmak için tam sayı kullanıldığında sep’in uzunluğu into’nun içindeki isimlerin sayısından bir eksik olmalıdır.
Bu ayarlamayı her bir yılın (year) son iki hanesini ayırmak için kullanabilirsiniz. Veriyi daha düzensiz bir hale getirmekle birlikte, az sonra sizin de göreceğiniz gibi bazı durumlarda işe yarayabilir.
table3 %>%
separate(year, into = c("century", "year"), sep = 2)
#> # A tibble: 6 × 4
#> country century year rate
#> <chr> <chr> <chr> <chr>
#> 1 Afghanistan 19 99 745/19987071
#> 2 Afghanistan 20 00 2666/20595360
#> 3 Brazil 19 99 37737/172006362
#> 4 Brazil 20 00 80488/174504898
#> 5 China 19 99 212258/1272915272
#> 6 China 20 00 213766/128042858312.4.2 Birleştirme
unite(), separate() fonksiyonunun tersidir: birden fazla sütunu tek bir sütunda toplar. separate()’den daha az ihtiyacınız olacaktır ancak aklınızın bir köşesinde bulunması işinize yarayacaktır.

Figure 12.5: Tablo5’i birleştirmek onu düzenli hale getirir
Bir önceki örnekte oluşturduğumuz asır (century) ve yıl (year) sütunlarını tekrar birleştirmek için unite() fonksiyonunu kullanabiliriz. O verileri tidyr::table5’de kaydedilmiş olarak bulabilirsiniz. unite() bir veri çerçevesini, yaratılacak yeni değişkenin ismini ve birleştirilecek sütunları dplyr::select() biçiminde tanımlandığı gibi alır:
table5 %>%
unite(new, century, year)
#> # A tibble: 6 × 3
#> country new rate
#> <chr> <chr> <chr>
#> 1 Afghanistan 19_99 745/19987071
#> 2 Afghanistan 20_00 2666/20595360
#> 3 Brazil 19_99 37737/172006362
#> 4 Brazil 20_00 80488/174504898
#> 5 China 19_99 212258/1272915272
#> 6 China 20_00 213766/1280428583Bu durumda sep parametresini de kullanmalıyız. Aksi belirtilmediği takdirde ayrı sütunlardan gelen değerlerin arasına bir alt çizgi (_) koyulacaktır. Burada herhangi bir ayraç istemediğimiz için ““ kullanıyoruz:
table5 %>%
unite(new, century, year, sep = "")
#> # A tibble: 6 × 3
#> country new rate
#> <chr> <chr> <chr>
#> 1 Afghanistan 1999 745/19987071
#> 2 Afghanistan 2000 2666/20595360
#> 3 Brazil 1999 37737/172006362
#> 4 Brazil 2000 80488/174504898
#> 5 China 1999 212258/1272915272
#> 6 China 2000 213766/128042858312.4.3 Alıştırmalar
extravefillparametreleriseparate()fonksiyonunda ne işe yararlar? Aşağıdaki iki veri grubu ile farklı seçenekleri deneyiniz.tibble(x = c("a,b,c", "d,e,f,g", "h,i,j")) %>% separate(x, c("one", "two", "three")) tibble(x = c("a,b,c", "d,e", "f,g,i")) %>% separate(x, c("one", "two", "three"))Hem
unite()hem deseparate()’in remove parametresi vardır. Ne işe yarar? Neden onaFALSEkoyarsınız?separate()veextract()fonksiyonlarını kıyaslayıp karşılaştırınız. Neden ayırmanın 3 farklı çeşidi (pozisyona göre ayırmak, ayraca göre ayırmak ve gruplara ayırmak) varken birleştirmenin tek bir çeşidi vardır?
12.5 Eksik değerler
Bir veri grubunun gösterimini değiştirmek eksik değerler ile ilgili ince bir tarafı ortaya çıkarır. Şaşırtıcı bir şekilde, bir değer iki olası şekilde eksik olabilir.
- Belirgin, yani
NAişaretli. - Gizli, yani veride bulunmayarak.
Bu fikri basit bir veri grubu ile örneklendirelim:
stocks <- tibble(
year = c(2015, 2015, 2015, 2015, 2016, 2016, 2016),
qtr = c( 1, 2, 3, 4, 2, 3, 4),
return = c(1.88, 0.59, 0.35, NA, 0.92, 0.17, 2.66)
)Bu veri grubunda eksik olan iki değer vardır:
2015’in dördüncü çeyreğinin hasılatı (return) belirgin bir şekilde eksiktir çünkü o değerin olması gereken hücre
NAibaresini içermektedir.2016’nın ilk çeyreğinin hasılatı gizli bir seilde eksiktir çünkü bu veri gurubunda böyle bir veriye rastlanmamaktadır.
Bir Zen deyişi ile aradaki farkı anlamaya çalışalım: eksikliği belirgin olan bir değerin yokluğu mevcuttur, gizli bir eksik değerin ise varlığı yoktur.
Bir veri grubunun gösterim şekli gizli eksik bir değeri belirgin yapabilir. Mesela sütunlara yılları koyarak gizli eksik değeri belirgin hale getirebiliriz:
stocks %>%
spread(year, return)
#> # A tibble: 4 × 3
#> qtr `2015` `2016`
#> <dbl> <dbl> <dbl>
#> 1 1 1.88 NA
#> 2 2 0.59 0.92
#> 3 3 0.35 0.17
#> 4 4 NA 2.66Verinin farklı gösterimlerinde belirgin şekilde eksik olan değerler önemli değil iseler gather() fonksiyonunana.rm = TRUE koyarak belirgin eksik değerleri gizleyebilirsiniz.
stocks %>%
spread(year, return) %>%
gather(year, return, `2015`:`2016`, na.rm = TRUE)
#> # A tibble: 6 × 3
#> qtr year return
#> <dbl> <chr> <dbl>
#> 1 1 2015 1.88
#> 2 2 2015 0.59
#> 3 3 2015 0.35
#> 4 2 2016 0.92
#> 5 3 2016 0.17
#> 6 4 2016 2.66Düzenli veride eksik değerleri belirgin hale getirmeye yarayan bir başka önemli araç ise complete() fonksiyonudur:
stocks %>%
complete(year, qtr)
#> # A tibble: 8 × 3
#> year qtr return
#> <dbl> <dbl> <dbl>
#> 1 2015 1 1.88
#> 2 2015 2 0.59
#> 3 2015 3 0.35
#> 4 2015 4 NA
#> 5 2016 1 NA
#> 6 2016 2 0.92
#> # … with 2 more rowscomplete() sütunları alır ve benzersiz tüm kombinasyonları bulur ve gerekli gördüğü yerleri belirgin NA ile doldurarak orjinal veri grubunun tüm değerleri içermesini garantiler.
Eksik değerler ile çalışırken bilmeniz gereken önemli başka bir araç daha vardır. Bazen bir veri kaynağının başlıca amacı veri girişi ise eksik değerler bir önceki değerin devrettiğinin göstergesidir:
treatment <- tribble(
~ person, ~ treatment, ~response,
"Derrick Whitmore", 1, 7,
NA, 2, 10,
NA, 3, 9,
"Katherine Burke", 1, 4
)fill() ile eksik değerleri doldurabilirsiniz. Bir sütundaki eksik değerlerin yerine eksik olmayan en son değeri yerleştirir (buna son gözlemin devretmesi de denir).
treatment %>%
fill(person)
#> # A tibble: 4 × 3
#> person treatment response
#> <chr> <dbl> <dbl>
#> 1 Derrick Whitmore 1 7
#> 2 Derrick Whitmore 2 10
#> 3 Derrick Whitmore 3 9
#> 4 Katherine Burke 1 412.6 Vaka analizi
Bölümü bitirirken öğrendiğiniz her şeyi toparlayıp gerçekçi bir veri düzenleme sorununu ele alalım. tidyr::who veri grubu yıla (year), ülkeye (country), yaşa (age), cinsiyete (gender) ve teşhis metoduna (diagnosis) göre ayrılmış tüberküloz (TB) vakalarını (cases) içermektedir. Veri 2014 Dünya Sağlık Örgütü Küresel Tüberküloz Raporu’ndan (2014 World Health Organization Global Tuberculosis Report) alınmıştır. Veriye http://www.who.int/tb/country/data/download/en/ linkinden ulaşabilirsiniz.
Bir epidemiolojik bilgi zenginliği olmasına rağmen bu verinin üzerinde çalışmak sağlanmış olduğu şekliyle zor olacaktır:
who
#> # A tibble: 7,240 × 60
#> country iso2 iso3 year new_sp_m014 new_sp_m1524 new_sp_m2534 new_sp_m3544
#> <chr> <chr> <chr> <int> <int> <int> <int> <int>
#> 1 Afghanis… AF AFG 1980 NA NA NA NA
#> 2 Afghanis… AF AFG 1981 NA NA NA NA
#> 3 Afghanis… AF AFG 1982 NA NA NA NA
#> 4 Afghanis… AF AFG 1983 NA NA NA NA
#> 5 Afghanis… AF AFG 1984 NA NA NA NA
#> 6 Afghanis… AF AFG 1985 NA NA NA NA
#> # … with 7,234 more rows, and 52 more variables: new_sp_m4554 <int>,
#> # new_sp_m5564 <int>, new_sp_m65 <int>, new_sp_f014 <int>,
#> # new_sp_f1524 <int>, new_sp_f2534 <int>, new_sp_f3544 <int>,
#> # new_sp_f4554 <int>, new_sp_f5564 <int>, new_sp_f65 <int>,
#> # new_sn_m014 <int>, new_sn_m1524 <int>, new_sn_m2534 <int>,
#> # new_sn_m3544 <int>, new_sn_m4554 <int>, new_sn_m5564 <int>,
#> # new_sn_m65 <int>, new_sn_f014 <int>, new_sn_f1524 <int>, …Bu veri grubu gerçek hayatta karşımıza çıkabilecek tipik bir örnektir. Lüzumsuz sütunlar, garip değişken kodları ve birçok eksik değer içerir. Uzun lafın kısası who darmadağındır ve düzenlemek için birden fazla adıma ihtiyacımız olacak. dplyr gibi tidyr da her bir fonksiyonun bir tek şeyi iyi yapması üzerine tasarlanmıştır. Bu da demektir ki gerçek hayatta karşılaştığınız durumlarda genellikle birden fazla eylemi bir veri hattında dizmelisiniz.
Çoğu zaman en iyi başlangıç noktası değişken olmayan sütunları bir araya getirmektir. Bakalım elimizde neler var:
Görünen o ki
country,iso2veiso3ülkeyi belirten gereksiz yere kullanılmış üç farklı değişken.Açıkça görülüyor ki
yearda bir değişken.Şu an için diğer sütunların neler olduğunu bilemiyoruz ancak değişken adlarının yapılarına bakıldığında (
new_sp_m014,new_ep_m014,new_ep_f014) bunların büyük ihtimalle değişken değil, değer oldukları düşünülebilir.
new_sp_m014 başlayarak newrel_f65’e kadar tüm sütunları toplamamız gerekiyor. Bu değerlerin neyi temsil ettiklerini daha bilmiyoruz, o nedenle onlara key gibi genel bir ad verelim. Vakaların sayısını gösteren hücreleri bildiğimiz için cases değişkenini kullanalım. Güncel gösterimde eksik olan bir çok değer olduğundan şimdilik na.rm kullanalım ki mevcut değerlere odaklanabilelim.
who1 <- who %>%
gather(new_sp_m014:newrel_f65, key = "key", value = "cases", na.rm = TRUE)
who1
#> # A tibble: 76,046 × 6
#> country iso2 iso3 year key cases
#> <chr> <chr> <chr> <int> <chr> <int>
#> 1 Afghanistan AF AFG 1997 new_sp_m014 0
#> 2 Afghanistan AF AFG 1998 new_sp_m014 30
#> 3 Afghanistan AF AFG 1999 new_sp_m014 8
#> 4 Afghanistan AF AFG 2000 new_sp_m014 52
#> 5 Afghanistan AF AFG 2001 new_sp_m014 129
#> 6 Afghanistan AF AFG 2002 new_sp_m014 90
#> # … with 76,040 more rowsYeni yarattığımız key sütunundaki değerleri sayarak bu değerlerin yapılarına ilişkin bazı ipuçları elde edebiliriz:
who1 %>%
count(key)
#> # A tibble: 56 × 2
#> key n
#> <chr> <int>
#> 1 new_ep_f014 1032
#> 2 new_ep_f1524 1021
#> 3 new_ep_f2534 1021
#> 4 new_ep_f3544 1021
#> 5 new_ep_f4554 1017
#> 6 new_ep_f5564 1017
#> # … with 50 more rowsKuşkusuz ki biraz kafa yorarak ve deneme yanılma ile bunu kendiniz de çözümleyebilirdiniz ama neyse ki veri sözlüğü elimizde ve bize şunları söylüyor:
Her sütunun ilk üç harfi o sütunda yeni bir TB vakası mı yoksa eski bir TB vakası mı olduğunu belirtir. Bu veri grubunda her sütun yeni vakaları içeriyor.
Sonraki iki harf TB’un cinsini tanımlar:
relnükseden vakaları temsilenepakciğer dışı tüberküloz vakalarını temsilensnakciğer simiri ile teşhis edilemeyen akciğer tüberkülozu vakalarını temsilen (smear negative)spakciğer simiri ile teşhis edilebilen akciğer tüberkülozu vakalarını temsilen (smear positive)
Altıncı harf TB hastalarının cinsiyetini belirtir. Veri grubu, vakaları erkekler (
m) ve kadınlar (f) olarak gruplamıştır.Kalan rakamlar yaş gruplarını belirtirler. Veri grubu, vakaları 7 farklı yaş grubuna ayırmıştır:
* 014 = 0 – 14 yaşları arasında
* 1524 = 15 – 24 yaşları arasında
* 2534 = 25 – 34 yaşları arasında
* 3544 = 35 – 44 yaşları arasında
* 4554 = 45 – 54 yaşları arasında
* 5564 = 55 – 64 yaşları arasında
* 65 = 65 ve üstüSütun isimlerinde ufak bir düzeltme yapmamız gerekiyor: ne yazık ki isimler biraz tutarsız çünkü elimizde new_rel yerine newrel var (bunu fark etmek biraz zor ama düzeltmezseniz takip eden aşamalarda hata uyarısı alırız). str_replace() komutunu “Dizgeler” bölümünde öğreneceksiniz ancak temel fikir oldukça basit: “newrel” karakterini “new_rel” ile değiştir. Böylece tüm değişkenlerin isimleri tutarlı olacaktır.
who2 <- who1 %>%
mutate(key = stringr::str_replace(key, "newrel", "new_rel"))
who2
#> # A tibble: 76,046 × 6
#> country iso2 iso3 year key cases
#> <chr> <chr> <chr> <int> <chr> <int>
#> 1 Afghanistan AF AFG 1997 new_sp_m014 0
#> 2 Afghanistan AF AFG 1998 new_sp_m014 30
#> 3 Afghanistan AF AFG 1999 new_sp_m014 8
#> 4 Afghanistan AF AFG 2000 new_sp_m014 52
#> 5 Afghanistan AF AFG 2001 new_sp_m014 129
#> 6 Afghanistan AF AFG 2002 new_sp_m014 90
#> # … with 76,040 more rowsseparate() komutunu kullanarak iki aşamada her koddaki değerleri ayırabiliriz. İlk aşama kodları her bir alt çizgiden bölecek.
who3 <- who2 %>%
separate(key, c("new", "type", "sexage"), sep = "_")
who3
#> # A tibble: 76,046 × 8
#> country iso2 iso3 year new type sexage cases
#> <chr> <chr> <chr> <int> <chr> <chr> <chr> <int>
#> 1 Afghanistan AF AFG 1997 new sp m014 0
#> 2 Afghanistan AF AFG 1998 new sp m014 30
#> 3 Afghanistan AF AFG 1999 new sp m014 8
#> 4 Afghanistan AF AFG 2000 new sp m014 52
#> 5 Afghanistan AF AFG 2001 new sp m014 129
#> 6 Afghanistan AF AFG 2002 new sp m014 90
#> # … with 76,040 more rowsAyrıca new sütununu sabit olduğu için bu veri grubundan çıkarabiliriz. Hazır sütun çıkarmaya başlamışken iso2 ve iso3’u de gereksiz oldukları için çıkarabiliriz.
who3 %>%
count(new)
#> # A tibble: 1 × 2
#> new n
#> <chr> <int>
#> 1 new 76046
who4 <- who3 %>%
select(-new, -iso2, -iso3)Sırada sexage’i sex ve age olarak ilk karakterden sonra bölmek geliyor:
who5 <- who4 %>%
separate(sexage, c("sex", "age"), sep = 1)
who5
#> # A tibble: 76,046 × 6
#> country year type sex age cases
#> <chr> <int> <chr> <chr> <chr> <int>
#> 1 Afghanistan 1997 sp m 014 0
#> 2 Afghanistan 1998 sp m 014 30
#> 3 Afghanistan 1999 sp m 014 8
#> 4 Afghanistan 2000 sp m 014 52
#> 5 Afghanistan 2001 sp m 014 129
#> 6 Afghanistan 2002 sp m 014 90
#> # … with 76,040 more rowswho veri grubu artık düzenli!
Size bu kodu her bir geçici sonucu yeni bir değişkene atayarak adım adım gösterdim. Genelde interaktif bir şekilde çalışırken böyle yapmak yerine aşama aşama karmaşık bir veri yolu kurarsınız.
who %>%
gather(key, value, new_sp_m014:newrel_f65, na.rm = TRUE) %>%
mutate(key = stringr::str_replace(key, "newrel", "new_rel")) %>%
separate(key, c("new", "var", "sexage")) %>%
select(-new, -iso2, -iso3) %>%
separate(sexage, c("sex", "age"), sep = 1)12.6.1 Alıştırmalar
Bu vaka analizinde doğru değerlere sahip olduğumuzu kontrol etmeyi kolaylaştırmak adına
na.rm = TRUEolarak belirledim. Bu akla yatkın mıdır? Bu veri grubunda eksik değerlerin nasıl gösterildiğini düşünün. Gizli eksik değerler var mıdır?NAve sıfır arasındaki fark nedir?mutate()adımını ihmal etseydiniz ne olurdu? (mutate(key = stringr::str_replace(key, "newrel", "new_rel")))iso2veiso3’üncountryile aynı olan gereksiz değişkenler olduklarını iddia ettim. Bu iddiayı doğrulayınız.Her bir ülke, yıl ve cinsiyet için toplam tüberküloz (TB) vakalarının sayısını hesaplayınız. Verinin bilgilendirici bir görselini yaratınız.
12.7 Düzensiz veri
Bir sonraki konuya geçmeden önce kısaca düzensiz veriden de bahsetmekte yarar var. Bu bölümde düzensiz veriye atıfta bulunurken alçaltıcı bir terim olan “darmadağın”ı kullanmıştım. Bu, durumu aşırı basitleştirmektir: düzenli olmayan ancak işe yarar ve sağlam zeminli birçok veri yapısı bulunmaktadır. Farklı veri yapılarını kullanmak için iki temel neden vardır:
Alternatif gösterimlerin performans ve boyut bakımından azımsanamayacak avantajları olabilir.
Özelleşmiş meslek dalları, verileri muhafaza etmek için düzenli verinin kurallarına aykırı olsa dahi kendilerine ait metotlar geliştirmiş olabilirler.
Bu iki nedenden dolayı tibble’dan veya veri çerçevesinden farklı bir şeye ihtiyacınız olabilir. Eğer veriniz gözlemlerden ve değişkenlerden oluşan bir dikdörtgenin içine doğal bir şekilde yerleşiyorsa, bence düzenli veri ilk seçeneğiniz olmalıdır. Ancak farklı yapılardaki verileri kullanmak için iyi nedenler olabilir ve dolayısıyla düzenli veri tek seçeneğiniz olmamalıdır.
Eğer düzensiz veri hakkında daha fazla bilgi sahibi olmak isterseniz Jeff Leek tarafından hazırlanmış bu düşünceli blog paylaşımını şiddetle tavsiye ederim: http://simplystatistics.org/2016/02/17/non-tidy-data/