20 Vektörler
20.1 Giriş
Bu kitapta şimdiye kadar tibble’lara ve onlarla çalışan paketlere odaklandık. Ama kendi fonksiyonlarınızı yazmaya başladıkça ve R’da daha derinlere indikçe tibble’ların altında yatan vektörleri öğrenmeniz gerekecek. R’ı daha geleneksel bir yoldan öğrendiyseniz muhtemelen vektörlere aşinasınızdır. Çünkü R kaynaklarının çoğu konuya vektörlerden başlar ve buradan tibble’lara doğru gelir. Bana kalırsa tibble’larla başlamak daha iyidir çünkü bunlar hemen kullanılmaktadır. Bunların altındaki bileşenlere daha sonra gelinebilir. Vektörler özellikle önemlidir çünkü yazacağınız çoğu fonksiyon vektörlerle çalışacaktır. tibble’larla çalışan fonksiyonlar yazmak da mümkündür (ggplot2, dplyr ve tidyr gibi) ancak bu tip fonksiyonları yazmak için gereken araçlar nevi şahsına münhasırdır ve tam olarak olgunlaşmamıştır. Daha iyi bir yaklaşım üzerinde çalışıyorum (https://github.com/hadley/lazyeval) ama bu kitabın yayınlanmasına yetişmeyecek. Tamamlandığında bile yine de hala vektörleri anlamanız gerekecek; bu sadece kullanıcı dostu bir yüz yazmayı kolaylaştıracak.
20.2 Vektörlere giriş
İki tip vektör bulunur:
Atomik vektörler. Bunun altı tipi vardır: mantıksal, tam sayı, gerçek sayı, karakter, kompleks, ve ham. Integer ve gerçek sayı vektörler birlikte nümerik vektörler olarak bilinir.
Listeler, bazen başka listeleri de içerebildiklerinden bazen yinelemeli vektörler olarak adlandırılır.
Atomik vektörlerle listeler arasındaki temel fark atomik vektörlerin homojen, listelerin ise heterojen olmasıdır. İlgili bir obje daha vardır: NULL. NULL genellikle bir vektörün olmadığını göstermek için kullanılır (NA ise bir vektörde bir değerin olmadığını göstermek için kullanılır). NULL uzunluğu 0 olan bir vektör gibi davranır. Şekil 20.1 vektörler arasındaki ilişkileri özetlemektedir.
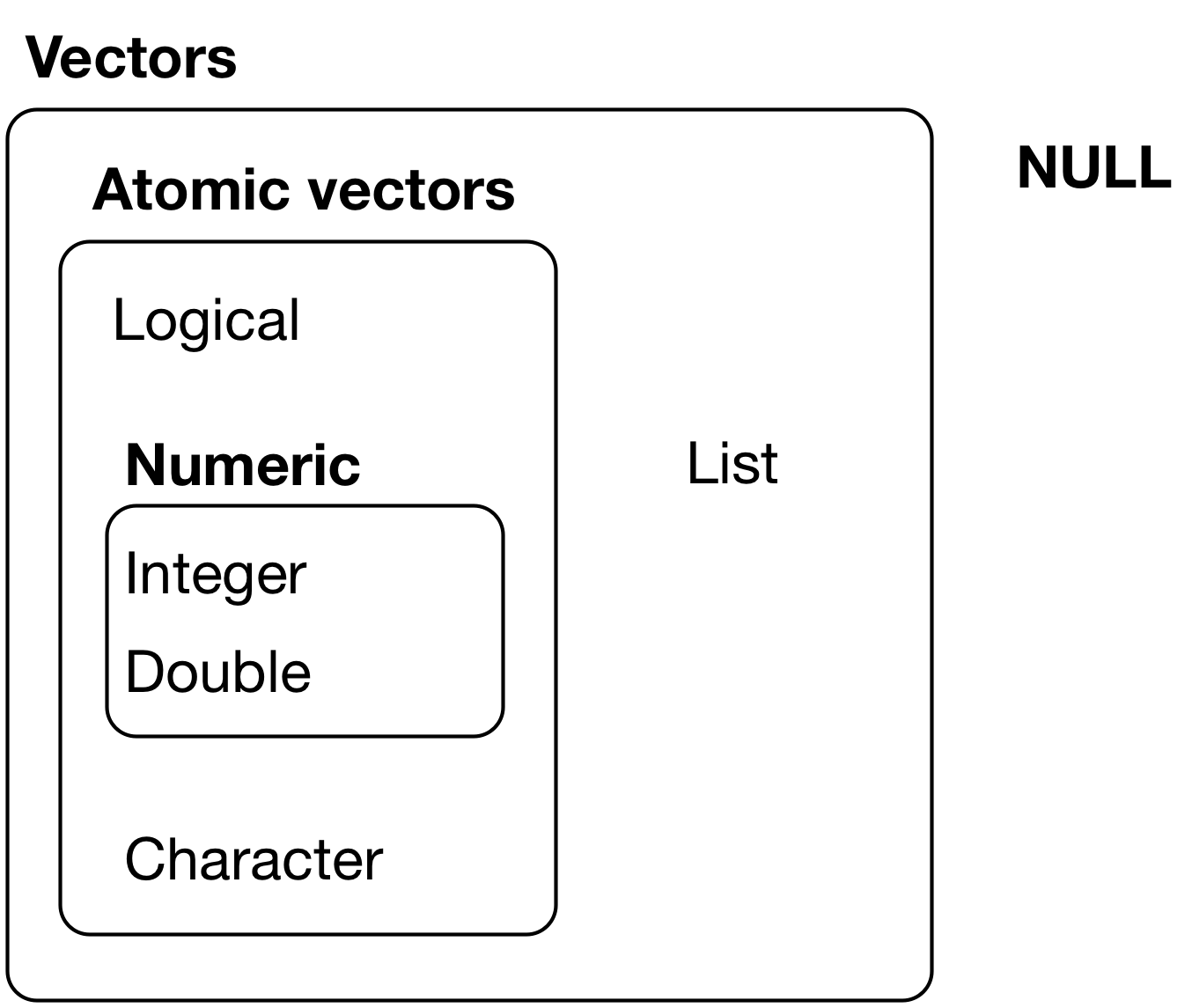
Figure 20.1: The hierarchy of R’s vector types
Her vektörün iki temel özelliği vardır:
tip,
typeof()ile belirlenir.typeof(letters) #> [1] "character" typeof(1:10) #> [1] "integer"uzunluk,
length()ile belirlenebilir.x <- list("a", "b", 1:10) length(x) #> [1] 3
Vektörler aynı zamanda ek meta veriler içerebilir. Bu özellikler ek davranışlara dayanan artırılmış vektör oluşturmak için kullanılır. Üç önemli artırılmış vektör türü vardır:
- Faktörler tamsayı vektörlerinin üstüne inşa edilir.
- Tarihler ve tarih-zamanlar sayısal vektörlerin üstüne inşa edilir.
- Veri çerçeveleri ve tibble’lar listelerin üzerine inşa edilir.
Bu bölümde bu önemli vektörler en basitten en karmaşığa tanıtılacaktır. Atomik vektörlerle başlayacağız; daha sonra listelere değineceğiz, çoğaltılmış vektörlerle de bitireceğiz.
20.3 Önemli atomik vektör tipleri
En önemli atomik vektör tipleri mantıksal, tamsayı, gerçek sayı ve karakter’dir. Ham ve kompleks vektörler genellikle veri analizinde kullanılır; o nedenle onları burada tartışmayacağız.
20.3.1 Mantıksal
Mantıksal vvektörler en basit atomik vektör tipidir çünkü sadece üç değer alabilir: FALSE, TRUE, ve NA. Mantıksal vektörler genelde karşılaştırma operatörleri ile yapılır. Bunlar karşılaştırmalar konusunda tartışılmaktadır. Bunları c() kullanarak el ile yapmanız da mümkündür:
1:10 %% 3 == 0
#> [1] FALSE FALSE TRUE FALSE FALSE TRUE FALSE FALSE TRUE FALSE
c(TRUE, TRUE, FALSE, NA)
#> [1] TRUE TRUE FALSE NA20.3.2 Nümerik
Tam sayı ve gerçek sayı vektörler birlikte sayısal vektörler olarak bilinir. R’da sayılar gerçek sayı vektör olarak yerleşiktir. Bir tam sayı yapmak için sayıdan sonra bir L ekleyin:
typeof(1)
#> [1] "double"
typeof(1L)
#> [1] "integer"
1.5L
#> [1] 1.5Tam sayı ve gerçek sayı arasındaki fark genellikle önemli değildir ama farkında olmanız gereken iki önemli fark bulunmaktadır:
Gerçek sayılar yaklaşık değerlerdir, her zaman tam olarak sabit miktarda bellekle temsil edilemeyen kayan nokta sayılarını (floating numbers) temsil eder. Bu da tüm gerçek sayıları yaklaşık değer olarak kabul etmeniz gerektiği anlamına gelir. Örneğin karekök ikinin karesi nedir?
x <- sqrt(2) ^ 2 x #> [1] 2 x - 2 #> [1] 4.44e-16Bu davranış kayan nokta sayıları ile çalışırken sıklıkla karşımıza çıkar: Hesaplamaların çoğu bir miktar tahmin hatası barındırır. Kayan nokta sayılarını
==kullanarak karşılaştırmak yerine, bir miktar sayısal hoşgörü sağlayan dplyr::near() kullanmalısınız.Tam sayıların özel bir değeri vardır:
NA. Gerçek sayılarda ise dört özel değer
bulunur:NA,NaN,Infand-Inf.NaN,Infve-Infdeğerlerinin üçü de bölme sırasında ortaya çıkar:c(-1, 0, 1) / 0 #> [1] -Inf NaN InfDiğer özel değerleri kontrol etmek için
==kullanmaktan kaçının. Bunun yerineis.finite()veis.nan()gibi yardımcı fonksiyonları kullanın.0 Inf NA NaN is.finite()x is.infinite()x is.na()x x is.nan()x
20.3.3 Karakter
Karakter vektörü en karmaşık atomik vektör tipidir çünkü bir karakter vektörünün her bir elemanı bir dizgedir (string) ve bir dizge istendiği kadar veri içerebilir.
Dizgeler kısmında dizge ile nasıl çalışılacağını öğrendiniz. Burada temel dizge uygulamasının önemli bir özelliğinden bahsetmek istiyorum: R küresel bir dizge havuzu kullanır. Bunun anlamı şudur: Her bir özgün dizge noktası bellekte sadece bir kez depolanır ve dizge her kullanıldığında o gösterime işaret edilir. Bu dizgeleri çoğaltmak için gereken bellek miktarını azaltır. Bu davranışı bir uygulama yaparak görebilirsiniz:
Dizgeler bölümünde, dizgelerle çalışma üzerine zaten çok şey öğrendiniz. Burada, dizge uygulamasının önemli bir özelliğinden bahsetmek istedim: R, global bir dizge havuzu kullanır. Bu, her benzersiz dizgenin bellekte yalnızca bir kez depolandığı ve dizgenin her kullanımının bu gösterime işaret ettiği anlamına gelir. Bu, yinelenen dizgelerin ihtiyaç duyduğu bellek miktarını azaltır. Bu davranışı pratikte pryr::object_size() ile görebilirsiniz:
x <- "Bu görece uzun bir dizgedir."
pryr::object_size(x)
#> 136 B
y <- rep(x, 1000)
pryr::object_size(y)
#> 8.13 kBy bellekte x’in 1000 katı kadar yer kaplamaz, çünkü y’nin her öğesi aynı dizgenin bir yalnızca bir göstergesidir. Bir gösterge 8 Byte’tır, yani 136 B dizgesine 1000 gösterge 8 * 1000 + 136 = 8.13 kB’dir.
20.3.4 Eksik değerler
Her atomik vektör tipinin kendi eksik değeri olduğunu unutmayın:
NA # mantıksal
#> [1] NA
NA_integer_ # tam sayı
#> [1] NA
NA_real_ # gerçek sayı
#> [1] NA
NA_character_ # karakter
#> [1] NANormalde bu farklı tipleri bilmeniz gerekmez çünkü her zaman NA kullanabilir ve aşağıda tartışılan örtülü zorlama (coercion) kurallarını kullanarak doğru tipe çevirebilirsiniz. Bununla birlikte girdileri konusunda katı olan bazı fonksiyonlar vardır. Bu bilgiyi arka cebinizde tutmanız iyi olur; böylece gerektiğinde spesifik olabilirsiniz.
20.3.5 Alıştırmalar
is.finite(x)ve!is.infinite(x)arasındaki farkı açıklayın.dplyr::near()’nin kaynak kodunu okuyun (İpucu: kaynak kodu görmek için ()’i atın). Bu nasıl çalışıyor?Mantıksal bir vektör üç değer alabilir. Bir tam sayı vektörü kaç değer alabilir? Bir gerçek sayı kaç değer alabilir? İhtiyacınız olan araştırmayı yapmak için Google’ı kullanın.
Bir gerçek sayıyı tam sayıya dönüştürmenizi sağlayacak en az dört fonksiyon bulun. Bunların farkı nedir? Net olun.
readr paketindeki hangi fonksiyonlar bir dizgeyi mantıksal, tam sayı ve gerçek sayı vektöre dönüştürmenizi sağlar?
20.4 Atomik vektörleri kullanmak
Farklı atomik vektör tiplerini öğrendiğinize göre kullanabileceğiniz önemli bazı araçlara bir göz atmak faydalı olacaktır. Bunlar şu soruların cevaplandırılmasını sağlar:
Bir tipten diğerine nasıl dönüşüm yapılır ve bu ne zaman kendiliğinden olur?
Bir objenin spesifik bir vektör tipi olduğu nasıl söylenir?
Farklı uzunluklara sahip vektörlerle çalışırsanız ne olur?
Bir vektörün elemanları nasıl isimlendirilir?
İstenen elemanlar nasıl çekilir?
20.4.1 Zorlama
Bir vektörü diğerine dönüştürmenin ya da dönüşmeye zorlamanın iki yolu vardır:
Açık zorlama
as.logical(),as.integer(),as.double()ya daas.character()gibi bir fonksiyon kullandığınızda olur. Açık zorlama kullandığınız her zaman, düzeltmeyi yukarı yönlü olarak yapıp yapamayacağınıza bakın; böylece daha başlangıçta vektörün yanlış tipte olmasını engellemiş olursunuz. Örneğin readrcol_typesözelliklerine ince ayar yapmanız gerekebilir.Örtülü zorlama bir vektörü belli bir vektör tipinin kullanılmasının öngörüldüğü özel bir bağlamda kullandığınızda olur. Örneğin nümerik özet fonksiyonuna sahip bir logical vektör kullandığınızda ya da bir integer vektörünün kullanılmasının beklendiği bir gerçek sayı vektör kullandığınızda…
Açık zorlama görece daha seyrek kullanıldığından ve örtülü zorlamanın anlaşılması kolay olduğundan burada bu ikincisine odaklanacağız.
Örtülü zorlamanın en önemli tipini görmüş durumdasınız: Mantıksal bir vektörün sayısal bir bağlamda kullanımı. Bu durumda TRUE, 1’e; , 0’a dönüştürülür. Bu da şu anlama gelir: mantıksal bir vektörün toplamı TRUE’ların sayısıdır ve bu vektörün ortalaması TRUE’ların oranıdır:
x <- sample(20, 100, replace = TRUE)
y <- x > 10
sum(y) # kaç tanesi 10dan büyüktür?
#> [1] 38
mean(y) # yüzde kaçı 10dan büyüktür?
#> [1] 0.38Bazı kodlarda (özellikle eski olanlarda) örtülü zorlamanın tam sayıdan mantıksala, zıt yönde kullanıldığını görebilirsiniz:
if (length(x)) {
# bir şey yap
}Bu durumda 0, FALSE’a ve diğer her şey TRUE’ya dönüştürülür. Bence bu kodunuzun anlaşılmasını zorlaştırır; bu nedenle ben bunu tavsiye etmem. Bunun yerine açık olmanızı öneririm: length(x) > 0.
c() kullanarak birden fazla tip içeren bir vektörü deneyip oluşturduğunuzda ne olduğunu anlamak da önemlidir: En karmaşık olan tip her zaman kazanır.
typeof(c(TRUE, 1L))
#> [1] "integer"
typeof(c(1L, 1.5))
#> [1] "double"
typeof(c(1.5, "a"))
#> [1] "character"Atomik bir vektör farklı tiplerin karışımından oluşamaz çünkü tip tam vektörün bir özelliğidir; tek tek elemanların değil. Birden çok tipi aynı vektörde karıştırmanız gerekiyorsa, bir liste kullanmalısınız. Bu konuya daha sonra kısaca değineceğiz.
20.4.2 Test fonksiyonları
Bazen vektörün tipine bağlı olarak farklı şeyler yapmak istersiniz. Seçeneklerden biri typeof() kullanmaktır. Diğeri ise TRUE ya da FALSE veren bir test fonksiyonu kullanmaktır. Temel R is.vector() ve is.atomic() gibi pek çok fonksiyona sahiptir. Ancak bunlar sıklıkla şaşırtıcı sonuçlar verir. Bunların yerine purr tarafından sağlanan ve aşağıdaki tabloda özetlenen is_* fonksiyonlarını kullanmak daha güvenlidir.
| lgl | int | dbl | chr | list | |
|---|---|---|---|---|---|
is_logical() |
x | ||||
is_integer() |
x | ||||
is_double() |
x | ||||
is_numeric() |
x | x | |||
is_character() |
x | ||||
is_atomic() |
x | x | x | x | |
is_list() |
x | ||||
is_vector() |
x | x | x | x | x |
Her bir fonksiyon is_scalar_atomic() gibi bir skaler versiyonu ile birlikte gelir. Bu uzunluğun 1 olduğunu kontrol eder. Örneğin fonksiyonunuzun bir argümanının tek bir mantıksal değer olduğunu kontrol etmek isterseniz bu faydalıdır.
20.4.3 Skalerler ve geri dönüşüm kuralları
R uyumlu olmak için vektör tiplerini zorlamanın yanı sıra, vektör uzunluklarını da örtülü olarak zorlar. Buna vektör geri dönüşümü denir çünkü kısa vektör, uzun vektör ile aynı uzunlukta tekrarlanır veya geri dönüştürülür.
Bu genellikle vektörleri ve skalerleri karıştırırken kullanışlıdır. Skalerleri tırnak içine alırım çünkü R’de aslında skaler bulunmaz. Bunun yerine tek bir sayı 1 uzunluğuna sahip bir vektördür. Skaler olmadığından yerleşik işlevlerin çoğu vektörelleştirilir, yani bir sayı vektöründe çalışırlar. Bu nedenle, örneğin şu kod çalışıyor:
sample(10) + 100
#> [1] 107 104 103 109 102 101 106 110 105 108
runif(10) > 0.5
#> [1] FALSE TRUE FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUER’da temel matematiksel işlemler vektörlerle çalışır. Yani basit matematiksel hesaplamalar yaparken hiçbir zaman açık bir yineleme gerçekleştirmeniz gerekmez.
Aynı uzunlukta iki vektör veya bir vektör ve bir skaler eklerseniz ne olacağı sezgiseldir, ancak farklı uzunluklarda iki vektör eklerseniz ne olur?
1:10 + 1:2
#> [1] 2 4 4 6 6 8 8 10 10 12R burada en kısa olan vektörü en uzun olanla aynı uzunluğa getirecektir ki buna geri dönüşüm denir. Bu, daha uzun olanın, kısa olanın uzunluğunun tam katı olmadığı durumlar haricinde sessizdir:
1:10 + 1:3
#> Warning in 1:10 + 1:3: longer object length is not a multiple of shorter object
#> length
#> [1] 2 4 6 5 7 9 8 10 12 11Vektör geri dönüşümü çok kısa ve zekice kodlar oluşturmak için kullanılabilir ama aynı zamanda problemlerin sessizce gizlenmesine de yol açabilir. Bu nedenle vektörelleştirilmiş fonksiyonlar düzenli olarak bir skaler dışında herhangi bir şeyi geri dönüştürdüğünüzde hata verecektir. Geri dönüştürmek istiyorsanız,rep() ile kendiniz yapmanız gerekir::
tibble(x = 1:4, y = 1:2)
#> Error:
#> ! Tibble columns must have compatible sizes.
#> • Size 4: Existing data.
#> • Size 2: Column `y`.
#> ℹ Only values of size one are recycled.
tibble(x = 1:4, y = rep(1:2, 2))
#> # A tibble: 4 × 2
#> x y
#> <int> <int>
#> 1 1 1
#> 2 2 2
#> 3 3 1
#> 4 4 2
tibble(x = 1:4, y = rep(1:2, each = 2))
#> # A tibble: 4 × 2
#> x y
#> <int> <int>
#> 1 1 1
#> 2 2 1
#> 3 3 2
#> 4 4 220.4.4 Vektörlerin isimlendirilmesi
Tüm vektör tipleri isimlendirilebilir. İsimlendirmeyi vektörleri c() ile oluştururken yapabilirsiniz:
c(x = 1, y = 2, z = 4)
#> x y z
#> 1 2 4Ya da purrr::set_names() yaptıktan sonra:
set_names(1:3, c("a", "b", "c"))
#> a b c
#> 1 2 3İsimlendirilmiş vektörler, biraz sonra tanımlanacak olan altkümeleme için çok kullanışlıdır.
20.4.5 Alt kümeleme
Şimdiye kadar bir tibble’daki satırları dplyr::filter() kullanarak filtreledik. filter() sadece tibble ile çalışır; bu nedenle vektörler için yeni bir araca ihtiyacımız var ki o da şudur: [. Bu bir altkümeleme fonksiyonudur ve x[a]’da olduğu gibi kullanılır. Bir vektörü alt kümeleyebileceğiniz dört şey vardır:
Sadece tam sayılardan oluşan nümerik bir vektör. Tam sayıların hepsi ya pozitif ya negatif ya da sıfır olmalıdır.
Pozitif tam sayılarla alt kümeleme yapmak elemanları o konumlarında tutar:
x <- c("one", "two", "three", "four", "five") x[c(3, 2, 5)] #> [1] "three" "two" "five"Bir konumu tekrar ederek daha uzun bir girdi ya da çıktı yapabilirsiniz:
x[c(1, 1, 5, 5, 5, 2)] #> [1] "one" "one" "five" "five" "five" "two"Negatif değerler elemanları belirlenen noktalara bırakır:
x[c(-1, -3, -5)] #> [1] "two" "four"Pozitif ve negatif değerleri karışık olarak kullanmak bir hatadır:
x[c(1, -1)] #> Error in x[c(1, -1)]: only 0's may be mixed with negative subscriptsHata mesajı sıfır ile alt kümelemeyi hatırlatmaktadır ki sonuçta bu bir değer vermez:
x[0] #> character(0)Bu genelde çok kullanışlı değildir ama fonksiyonunuzu test etmek için yaygın olmayan veri yapıları oluşturmak istediğinizde yardımı dokunacaktır.
Mantıksal bir vektör ile alt kümeleme bütün değerleri
TRUEdeğerine karşılık gelen tüm değerleri tutar. Bu genelde karşılaştırma fonksiyonları ile birlikte kullanıldığında yararlıdır.x <- c(10, 3, NA, 5, 8, 1, NA) # x’in bütün eksik olmayan değerleri x[!is.na(x)] #> [1] 10 3 5 8 1 # x’in bütün gerçek sayı (ya da eksik) değerleri x[x %% 2 == 0] #> [1] 10 NA 8 NABir vektörü isimlendirdiyseniz bunu bir karakter vektörü ile alt kümeleyebilirsiniz:
x <- c(abc = 1, def = 2, xyz = 5) x[c("xyz", "def")] #> xyz def #> 5 2Pozitif tam sayılarda olduğu gibi, bireysel girişleri çoğaltmak için karakter vektörünü de kullanabilirsiniz..
Alt kümelemenin en basit tipi hiçbir şey yapmamaktır.
x[], x’in tamamını verir. Bu vektörleri alt kümelemede kullanışlı değildir ama matrisleri (ve diğer çok boyutlu yapıları) alt kümelemede işe yarar çünkü indeksi boş bırakarak bütün satır ve sütunları seçmenize olanak verir. Örneğinx2d isex[1, ]ilk satırı ve bütün sütunları seçerken,x[, -1]bütün satırları ve birincisi hariç bütün sütunları seçer.
Alt kümeleme uygulamaları hakkında daha fazla şey öğrenmek için Advanced_R’ın [Subsetting] bölümünü okuyabilirsiniz: http://adv-r.had.co.nz/Subsetting.html#applications
[’nin [[ şeklinde önemli bir çeşidi vardır. [[ sadece tek bir elemanı çıkarır ve her zaman isimleri atar. Tıpkı bir döngüde (loop) olduğu gibi tek bir parçayı çıkardığınızı açık bir şekilde belirtmek istediğinizde bunu kullanabilirsiniz. [ ile [[ arasındaki ayrım listelerde büyük önem kazanır. Bunu kısaca göreceğiz.
20.4.6 Alıştırmalar
mean(is.na(x))sizexvektörü ile ilgili ne söylüyor? Peki yasum(!is.finite(x))?is.vector()’ün belgesini dikkatlice okuyun. Bu neyi test ediyor? Nedenis.atomic()atomik vektörlerin yukarıdaki tanımıyla uyuşmuyor?setNames()ilepurrr::set_names()’i karşılaştırın.Girdi olarak bir vektörü alan ve çıktı olarak aşağıdakileri veren fonksiyonlar yazınız:
En son değer.
[mi, yoksa[[mi kullanmalısınız?Çift sayılı konumlardaki elemanlar.
Son değer hariç her eleman.
Sadece çift sayılar (eksik değerler de yok).
x[-which(x > 0)] ile x[x <= 0] neden aynı değildir?
Vektörün uzunluğundan daha büyük pozitif bir tam sayı ile alt kümeleme yaparsanız ne olur? Var olmayan bir isimle alt kümeleme yaparsanız ne olur?
20.5 Yinelemeli vektörler (listeler)
Listeler diğer listeleri içerebildiğinden karmaşıklıkta atomik vektörlerden bir adım ötededir. Bu onları hiyerarşik ya da ağaç benzeri yapıları temsil için daha uygun kılar. Listeleri list() ile oluşturabilirsiniz:
x <- list(1, 2, 3)
x
#> [[1]]
#> [1] 1
#>
#> [[2]]
#> [1] 2
#>
#> [[3]]
#> [1] 3Listelerle çalışırken çok işe yarayan araçlardan biri str()’dir çünkü bu içerikten ziyade yapıya odaklanmaktadır.
str(x)
#> List of 3
#> $ : num 1
#> $ : num 2
#> $ : num 3
x_named <- list(a = 1, b = 2, c = 3)
str(x_named)
#> List of 3
#> $ a: num 1
#> $ b: num 2
#> $ c: num 3Atomik vektölerin aksine list() çeşitli objelerden oluşabilir::
y <- list("a", 1L, 1.5, TRUE)
str(y)
#> List of 4
#> $ : chr "a"
#> $ : int 1
#> $ : num 1.5
#> $ : logi TRUEListeler diğer listeleri bile içerebilir!
z <- list(list(1, 2), list(3, 4))
str(z)
#> List of 2
#> $ :List of 2
#> ..$ : num 1
#> ..$ : num 2
#> $ :List of 2
#> ..$ : num 3
#> ..$ : num 420.5.1 Listeleri görselleştirme
Daha karmaşık liste manipülasyon fonksiyonlarını açıklamak için listeleri görselleştirmek faydalı olacaktır. Örneğin şu üç listeyi ele alalım:
x1 <- list(c(1, 2), c(3, 4))
x2 <- list(list(1, 2), list(3, 4))
x3 <- list(1, list(2, list(3)))Bunları şöyle çizeceğim:
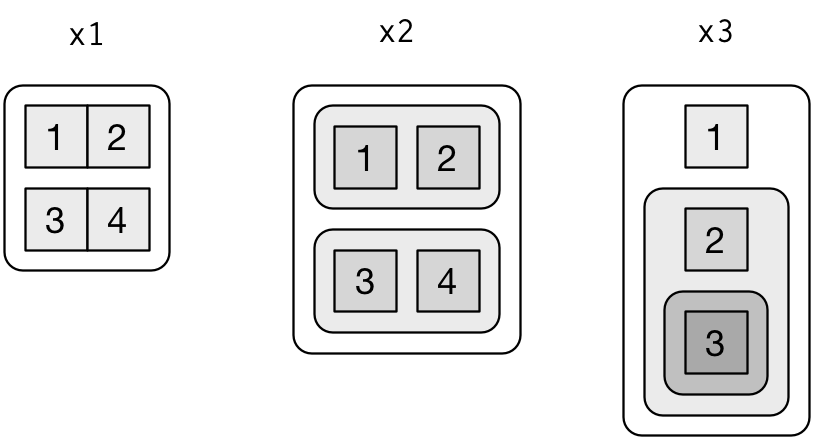
Burada üç kural vardır:
Listelerin köşeleri yuvarlaktır. Atomik vektörler ise köşelidir.
Yavrular ebeveynlerinin içine çizilir ve hiyerarşiyi daha kolay görmek için biraz daha koyu renge boyanır.
Yavruların yerleşimi (satır ve sütunları) önemli değildir. Bu nedenle bu nedenle, yer kazanmak veya örnekte önemli bir özellik göstermek için bir satır veya sütun yerleşimi seçeceğim.
20.5.2 Alt kümeleme
Bir listeyi alt kümelemenin üç yolu vardır. Bunları a isimli bir liste ile göstereceğim:
a <- list(a = 1:3, b = "a string", c = pi, d = list(-1, -5))[bir alt liste çıkarır. Sonuç daima bir listedir.str(a[1:2]) #> List of 2 #> $ a: int [1:3] 1 2 3 #> $ b: chr "a string" str(a[4]) #> List of 1 #> $ d:List of 2 #> ..$ : num -1 #> ..$ : num -5Vektörlerde olduğu gibi mantıksal, tam sayı ya da karakter vektörü ile alt kümeleme yapabilirsiniz..
[[bir listeden tek bir bileşeni çıkarır. Listeden bir hiyerarşi seviyesini kaldırır.str(a[[1]]) #> int [1:3] 1 2 3 str(a[[4]]) #> List of 2 #> $ : num -1 #> $ : num -5$bir listenin isimli elemanlarını çıkarmanın kısa yoludur. Tırnak işareti kullanmanız gerekmedikçe[[’e benzer bir şekilde çalışır.a$a #> [1] 1 2 3 a[["a"]] #> [1] 1 2 3
[ ile [[ arasındaki fark listeler için gerçekten önemlidir çünkü [[ bir listenin içine girerken, [ yeni ve daha küçük bir liste verir. Yukarıdaki kod ve çıktı ile Şekil 20.2’deki gösterimi karşılaştırın.
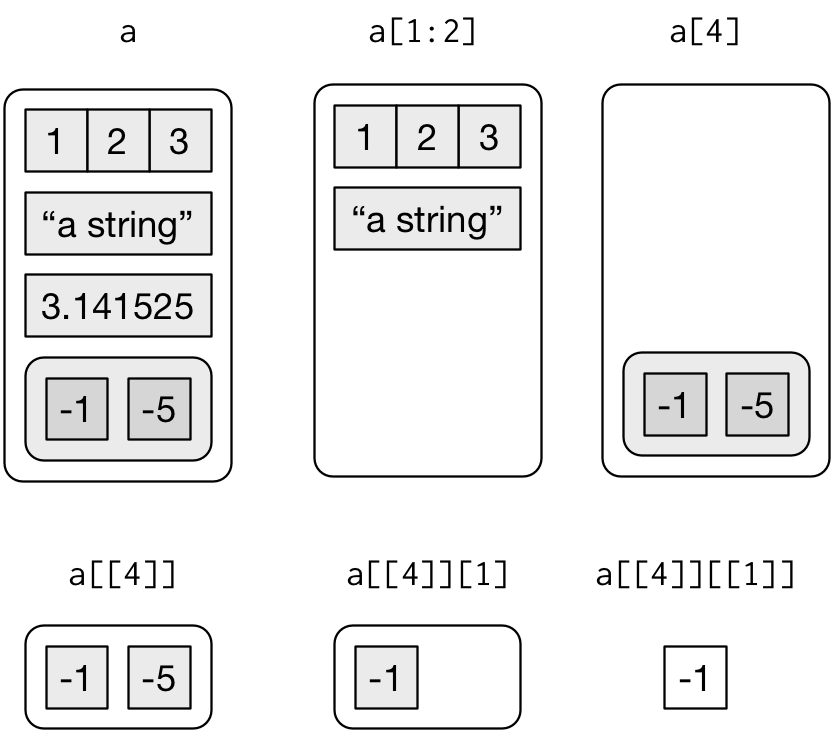
Figure 20.2: Subsetting a list, visually.
20.5.3 Baharat listeleri
[ ile [[ arasındaki fark çok önemlidir ama kolaylıkla karıştırılır. Hatırlamanıza yardımcı olmak için size sıra dışı bir karabiberlik göstereceğim.
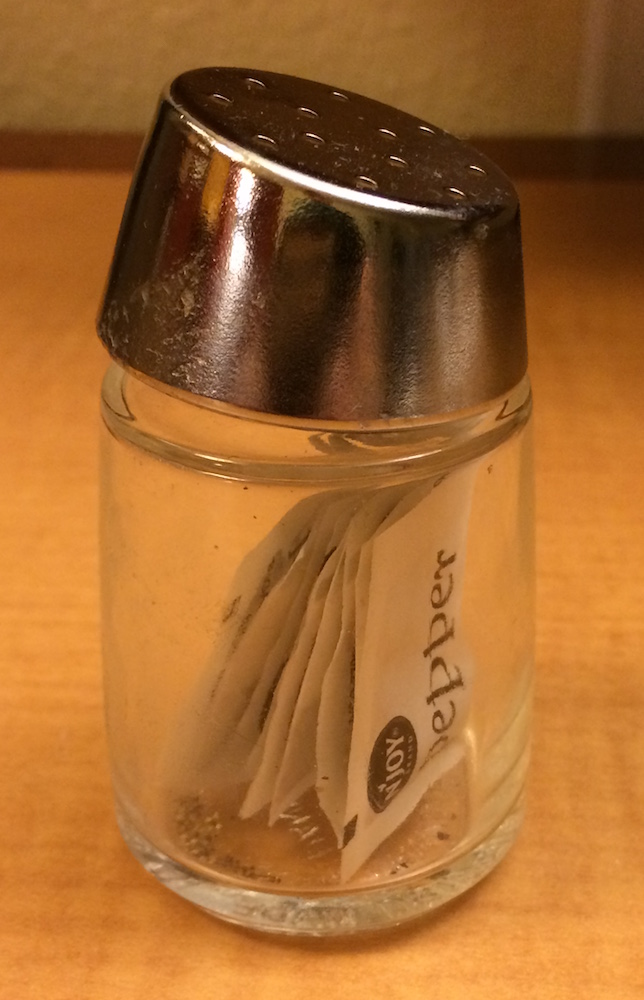
Bu karabiberlik sizin x listenizse x[1] tek bir karabiber paketi içeren bir karabiberliktir:
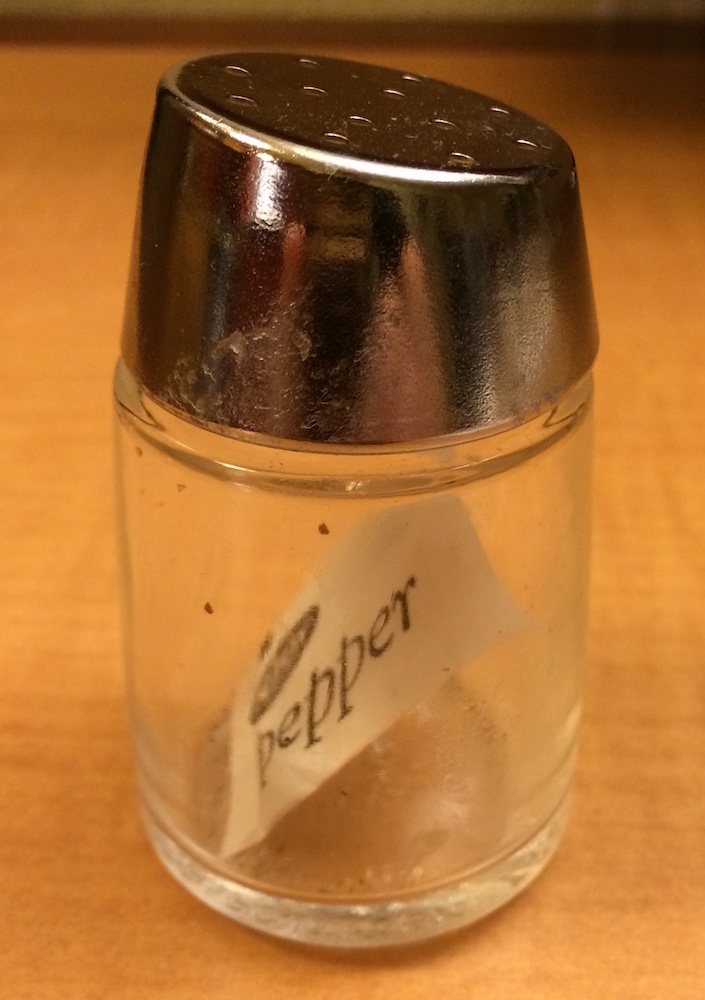
x[2] de aynı görünür ama ikinci paketi içerir. x[1:2] ise iki karabiber paketi içerir. x[[1]] ise şudur:
x[[1]] şudur:

Karabiber paketinin içeriğini çıkarmak istiyorsanız şuna ihtiyacınız var: x[[1]][[1]]

20.6 Özellikler
Herhangi bir vektör özellikleri aracılığıyla istenen ek metaveriyi içerebilir. Özellikleri herhangi bir nesneye eklenebilecek vektörlerin isimli listesi olarak düşünebilirsiniz.
Özelliklik değerlerini attr() ile alabilir ve ayarlayabilirsiniz. Hepsini bir kerede görmek için ise attributes()’i kullanabilirsiniz.
x <- 1:10
attr(x, "selamlasma")
#> NULL
attr(x, "selamlasma") <- "Merhaba!"
attr(x, "vedalasma") <- "Hoscakal!"
attributes(x)
#> $selamlasma
#> [1] "Merhaba!"
#>
#> $vedalasma
#> [1] "Hoscakal!"R’ın temel kısımlarında kullanılan çok önemli üç özellik bulunmaktadır:
- İsimler bir vektörün elemanlarını isimlendirmek için kullanılır.
- Boyutlar bir vektörün matriks ya da sıra gibi davranmasını sağlar.
- Sınıflar S3 nesne yönelimli sistemi uygulamak için kullanılır.
İsimleri yukarıda görmüştünüz. Boyutlara ise değinmeyeceğiz çünkü bu kitapta matris kullanmıyoruz. Bu durumda sadece sınıfları açıklamak kalıyor. Bunlar genel fonksiyonların işleyişini kontrol eder. Genel fonksiyonlar R’da nesne yönelimli programlama için kilit niteliğindedir çünkü fonksiyonların farklı girdi sınıfları için farklı davranmasını sağlarlar. Nesne yönelimli programlamaya ilişkin ayrıntılar bu kitabın kapsamı dışındadır ama Advanced R’da bu konu ile ilgili daha geniş bir bilgi bulabilirsiniz http://adv-r.had.co.nz/OO-essentials.html#s3.
Tipik bir genel fonksiyon şöyle görünür:
as.Date
#> function (x, ...)
#> UseMethod("as.Date")
#> <bytecode: 0x7ff0d55d05e8>
#> <environment: namespace:base>“UseMethod” çağrısı bunun bir genel fonksiyon olduğu anlamına gelir ve ilk argüman sınıfını baz alarak özgün bir metod, yani bir fonksiyon çağırır. (Bütün yöntemler fonksiyondur ama bütün fonksiyonlar yöntem değildir). bir genel fonksiyon ile ilgili tüm yöntemleri methods() ile listeleyebilirsiniz:
methods("as.Date")
#> [1] as.Date.character as.Date.default as.Date.factor
#> [4] as.Date.numeric as.Date.POSIXct as.Date.POSIXlt
#> [7] as.Date.vctrs_sclr* as.Date.vctrs_vctr*
#> see '?methods' for accessing help and source codeÖrneğin eğer x bir karakter vektörü ise as.Date() şunu çağırır: as.Date.character(). Ama eğer bir faktörse şunu çağırır: as.Date.factor()
Bir yöntemin özel uygulamasını getS3method() ile görebilirsiniz:
getS3method("as.Date", "default")
#> function (x, ...)
#> {
#> if (inherits(x, "Date"))
#> x
#> else if (is.null(x))
#> .Date(numeric())
#> else if (is.logical(x) && all(is.na(x)))
#> .Date(as.numeric(x))
#> else stop(gettextf("do not know how to convert '%s' to class %s",
#> deparse1(substitute(x)), dQuote("Date")), domain = NA)
#> }
#> <bytecode: 0x7ff0d9749558>
#> <environment: namespace:base>
getS3method("as.Date", "numeric")
#> function (x, origin, ...)
#> {
#> if (missing(origin)) {
#> if (!length(x))
#> return(.Date(numeric()))
#> if (!any(is.finite(x)))
#> return(.Date(x))
#> stop("'origin' must be supplied")
#> }
#> as.Date(origin, ...) + x
#> }
#> <bytecode: 0x7ff0ddb852e0>
#> <environment: namespace:base>En önemli S3 genel fonksiyon print()’tir: İsmini konsola yazdığınızda objenin nasıl yazılacağını kontrol eder. Diğer önemli genel fonksiyonlar [, [[ ve $’tir.
20.7 Çoğaltılmış vektörler
Atomik vektörler ve listeler faktörler ve tarihler gibi diğer önemli vektör tipleri için yapı taşlarıdır. Ben bunlara çoğaltılmış vektörler diyorum çünkü bunlar, sınıf da dahil, ilave özellikleri olan vektörlerdir. Çoğaltlmış vektörlerin bir sınıfı bulunduğundan üzerine inşa edildikleri atomik vektörden farklı davranırlar. Bu kitapta dört önemli çoğaltılmış vektör kullanıyoruz:
- Faktörler
- Tarihler
- Tarih-zamanlar
- tibble’lar
Bunlar sırasıyla aşağıda açıklanmaktadır:
20.7.1 Faktörler
Faktörler sabit bir değerler seti alabilen kategorik veriyi temsil etmek için tasarlanmıştır. Faktörler tamsayıların üzerine inşa edilir ve bir “levels” özelliği bulunur:
x <- factor(c("ab", "cd", "ab"), levels = c("ab", "cd", "ef"))
typeof(x)
#> [1] "integer"
attributes(x)
#> $levels
#> [1] "ab" "cd" "ef"
#>
#> $class
#> [1] "factor"20.7.2 Tarihler ve tarih-zamanlar
R’da tarihler 1 Ocak 1970’ten bu yana gün sayısını temsil eden sayısal vektörlerdir.
x <- as.Date("1971-01-01")
unclass(x)
#> [1] 365
typeof(x)
#> [1] "double"
attributes(x)
#> $class
#> [1] "Date"Tarih-zamanlar 1 Ocak 1970’te bu yana saniye sayısını temsil eden, POSIXct sınıfına sahip sayısal vektörlerdir. (Merak ediyorsanız söyleyeyim; “POSIXct” “Portable Operating System Interface [taşınabilir işleyen sistem arayüzü]”in kısaltmasıdır ki bu da takvim zamanıdır.)
x <- lubridate::ymd_hm("1970-01-01 01:00")
unclass(x)
#> [1] 3600
#> attr(,"tzone")
#> [1] "UTC"
typeof(x)
#> [1] "double"
attributes(x)
#> $class
#> [1] "POSIXct" "POSIXt"
#>
#> $tzone
#> [1] "UTC"tzone özelliği tercihe bağlıdır. Hangi mutlak zamana karşılık geldiğini değil, zamanın nasıl yazılacağını kontrol eder.
attr(x, "tzone") <- "US/Pacific"
x
#> [1] "1969-12-31 17:00:00 PST"
attr(x, "tzone") <- "US/Eastern"
x
#> [1] "1969-12-31 20:00:00 EST"POSIXlt denen bir tarih-zaman tipi daha bulunmaktadır. Bunlar isimli listelerin üzerine inşa edilir:
y <- as.POSIXlt(x)
typeof(y)
#> [1] "list"
attributes(y)
#> $names
#> [1] "sec" "min" "hour" "mday" "mon" "year" "wday" "yday"
#> [9] "isdst" "zone" "gmtoff"
#>
#> $class
#> [1] "POSIXlt" "POSIXt"
#>
#> $tzone
#> [1] "US/Eastern" "EST" "EDT"POSIXlt’ler tidyverse içinde nadirdir. Temel R’da ise bol miktarda bulunurlar çünkü yıl ya da ay gibi bir tarihin özel bileşenlerinin ekstrakte edilmesinde gerekldirler. Lubridate bunu yapabilmeniz için yardımcı olduğundan , bunlara ihtiycınız yoktur. POSIXltlerle çalışmak her zaman daha kolaydır. O nedenle eğer bir POSIXlt’niz olduğunu görürseniz bunu her zaman düzenli bir veri zamanına çevirmelisiniz: lubridate::as_date_time()
20.7.3 tibble’lar
tibble’lar çoğaltılmış listelerdir: “tbl_df” + “tbl” + “data.frame”sınıfları ve names (column) ve row.names özellikleri vardır:
tb <- tibble::tibble(x = 1:5, y = 5:1)
typeof(tb)
#> [1] "list"
attributes(tb)
#> $class
#> [1] "tbl_df" "tbl" "data.frame"
#>
#> $row.names
#> [1] 1 2 3 4 5
#>
#> $names
#> [1] "x" "y"Bir tibble ile bir liste arasındaki fark bir veri çerçevesindeki tüm elemanların aynı uzunluktaki vektörler olması zorunluluğudur. Tibble’larla çalışan tüm fonksiyonlar bu kısıtlamayı zorlar.
Geleneksel veri çerçeveleri çok benzer bir yapıya sahiptir:
df <- data.frame(x = 1:5, y = 5:1)
typeof(df)
#> [1] "list"
attributes(df)
#> $names
#> [1] "x" "y"
#>
#> $class
#> [1] "data.frame"
#>
#> $row.names
#> [1] 1 2 3 4 5Ana fark sınıftır. tibble’ın sınıfında “data.frame” bulunur. Yani tibble’lar düzenli veri çerçevesi davranışına ‘doğuştan’ sahiptir.
20.7.4 Alıştırmalar
hms::hms(3600)ne verir? Nasıl yazılır? Üzerine inşa edildiği önsel çoğaltılmış vektör tipi nedir? Hangi özellikleri kullanır?farklı uzunluktaki sütunlara sahip bir tibble yapmayı denediğinizde ne oluyor?
Yukarıdaki tanımdan hareketle bir tibble’ın bir sütunu olan bir liste doğru mudur?