14 Dizgeler
14.1 Giriş
Bu bölüm R’da dizgeleri nasıl manipüle edeceğinize bir giriş oluşturuyor. dizgelerin nasıl çalıştığını ve nasıl oluşturulduğunu öğreneceksiniz, ama bölümün asıl odağı kurallı ifadeler (regexps) olacak. Kurallı ifadeler kullanışlıdır çünkü dizgeler genellikle yapısal olmayan ya da yarı-yapısal olan verilerden oluşur ve kurallı ifadeler dizgelerdeki kalıpları tanımlarken az ve öz bir dildir. Bir kurallı ifadeye ilk baktığınızda bir kedinin klavyenizin üstünde yürüdüğünü düşüneceksiniz ama bilginiz derinleştikçe ifadeler kısa zamanda anlamlı gelmeye başlayacaktır.
14.2 Dizge temelleri
Dizgeleri tek tırnak ya da çift tırnak ile oluşturabilirsiniz. Diğer dillerin aksine, hangisiyle oluşturduğunuz bir fark yaratmaz. Eğer birden fazla " içeren bir dizge oluşturmayacaksanız, ben her zaman " kullanmanızı öneririm.
string1 <- "Bu bir dizgedir"
string2 <- 'Dizge içinde bir "alıntı" yapmak istediğimde, tek tırnak kullanırım'Eğer bir tırnağı kapatmayı unututursanız devam ettirme işareti olan + yı görürsünüz:
> "Bu dizgenin kapama tırnağı yok
+
+
+ YARDIM EDİN!Eğer bununla karşılaşırsanız, Escape (esc) tuşuna basın ve tekrar deneyin!
Bir dizgede gerçek bir tek ya da çift tırnak kullanmak için “kaçış” işaretini (\) kullanabilirsin:
double_quote <- "\"" # ya da '"'
single_quote <- '\'' # ya da "'"Bu demek oluyor ki eğer dizgeye gerçek bir sola eğik çizgi eklemek isterseniz, iki kere yazmanız gerek: "\\".
Bir dizgenin basılı ifadesi dizgenin kendisiyle aynı olmadığına dikkat edin, çünkü basılı ifade kaçış işaretlereini de gösterir. Dizgenin ham içeriğini görmek için writeLines() kullanın:
x <- c("\"", "\\")
x
#> [1] "\"" "\\"
writeLines(x)
#> "
#> \Pek çok farklı özel karakter vardır. Bunların en yaygınları "\n", yeni satır ve "\t", tab’dır, tüm listeyi ": ?'"', ya da ?"'" üzerinde yardım isteyerek görebilirsiniz. Bazen de her platformda çalışan İngilizce olmayan karakterlerin bir gösterimi olan,"\u00b5" gibi dizgeler görebilirsiniz:
x <- "\u00b5"
x
#> [1] "µ"Birden fazla dizge genellikle c() ile oluşturabileceğiniz bir karakter vektöründe tutulur:
c("bir", "iki", "üç")
#> [1] "bir" "iki" "üç"14.2.1 Dizge uzunluğu
Temel R, dizgelerle çalışmak için pek çok farklı fonksiyon içerir ama bunlardan kaçınmalıyız çünkü tutarsız olabiliyorlar ve bu hatırlanmalarını zorlaştırıyor. Bunun yerine stringr fonksiyonlarını kullanacağız. Bu fonksiyonların daha sezgisel isimleri var ve hepsi str_ ile başlıyor. Örneğin, str_length() bir dizgedeki karakter sayısını verir:
str_length(c("a", "R for data science", NA))
#> [1] 1 18 NAEğer RStudio kullanıyorsanız bu yaygın str_ ön eki bilhassa kullanışlıdır, çünkü str_ yazmak bütün stringr fonksiyonlarını görmenizi sağlayan otomatik tamamlamayı başlatır:
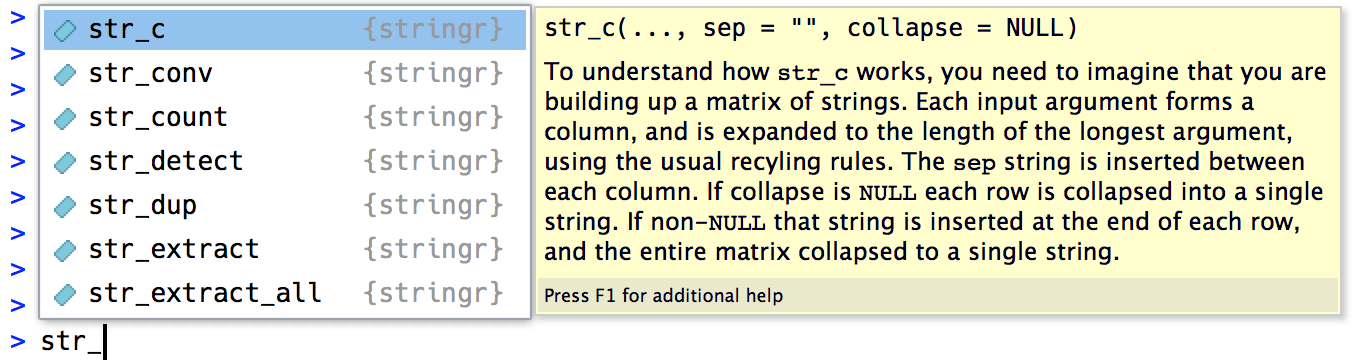
14.2.2 Dizgeleri birleştirme
İki ya da daha fazla dizgeyi birleştirmek için str_c() kullanılır:
str_c("x", "y")
#> [1] "xy"
str_c("x", "y", "z")
#> [1] "xyz"Nasıl ayrılacaklarını kontrol etmek için sep argümanını kullanılır:
str_c("x", "y", sep = ", ")
#> [1] "x, y"R’daki diğer birçok fonksiyon gibi eksik değerler bulaşıcıdır. Eğer onları "NA" olarak yazdırmak istiyorsanız str_replace_na() kullanın:
x <- c("abc", NA)
str_c("|-", x, "-|")
#> [1] "|-abc-|" NA
str_c("|-", str_replace_na(x), "-|")
#> [1] "|-abc-|" "|-NA-|"Yukarda görüldüğü gibi str_c()` vektörleştirilmiştir ve kısa vektörleri otomatik olarak en uzunla aynı boya dönüştürür:
str_c("prefix-", c("a", "b", "c"), "-suffix")
#> [1] "prefix-a-suffix" "prefix-b-suffix" "prefix-c-suffix"Boyu 0 olan objeler sessizce çıkartılır. Bu özellikle if döngülerinde kullanışlıdır:
isim <- "Hadley"
vakit <- "sabah"
dogumgunu <- FALSE
str_c(
" İyi ", vakit, " ", isim,
if (dogumgunu) " Nice Yaşlara! ",
"."
)
#> [1] " İyi sabah Hadley."Dizgelerden oluşan bir vektörü tek bir dizgede toplamak için collapse kullanın:
str_c(c("x", "y", "z"), collapse = ", ")
#> [1] "x, y, z"14.2.3 Dizgelerde alt kümeleme
str_sub() ile bir dizgenin kısımlarını elde edebilirsiniz. Dizge gibi, str_sub(), alt dizgenin (kapsayan) pozisyonunu veren başlangıç (start) ve bitiş (end) argumanları alır.
x <- c("Elma", "Muz", "Armut")
str_sub(x, 1, 3)
#> [1] "Elm" "Muz" "Arm"
# negatif rakamlar sondan başa doğru sayar
str_sub(x, -3, -1)
#> [1] "lma" "Muz" "mut"Dikkate alınmalı ki str_sub() dizge çok kısa olsa bile başarısız olmayacaktır: sadece mümkün olanı döndürecektir:
str_sub("a", 1, 5)
#> [1] "a"Dizgeleri modifiye etmek için str_sub()’ın atama yöntemini de kullanabilirsiniz:
str_sub(x, 1, 1) <- str_to_lower(str_sub(x, 1, 1))
x
#> [1] "elma" "muz" "armut"14.2.4 Yereller
Yukarıda metni küçük harfe çevirmek için str_to_lower() kullandım. Siz str_to_upper() ya da str_to_title() de kullanabilirsiniz. Yine de, harflerin durumunu değiştirmek ilk bakışta göründüğünden daha karmaşık olabilir çünkü farklı dillerin farklı kuralları vardır. Bir yerel (locale) belirleme yaparak kurallar seti seçebilirsiniz:
# Türkçe'de noktalı ve noktasız olmak üzere iki i vardır, ve
# bunları büyük harf olarak kullanmak için faklı bir kural vardır:
str_to_upper(c("i", "ı"))
#> [1] "I" "I"
str_to_upper(c("i", "ı"), locale = "tr")
#> [1] "İ" "I"Lokal, iki ya da üç harf kısaltması olan ISO 639 dil kodu olarak belirlenmiştir. Eğer kendi dilininin kodunu bilmiyorsanız Wikipedia adresinde güzel bir liste var. Eğer lokali boş bırakırsanız, işletim sisteminin sağladığı o anki lokali kullanır.
Lokalden etkilenen bir diğer işlem sıralamadır. R’ın temel order() ve sort() fonksiyonları dizleri o anki lokale göre sıralar. Eğer farklı bilgisayarlar arasında tutarlı davranış sağlamak isterseniz, ekstra locale argümanı alan str_sort() ve str_order()kullanabilirsiniz:
x <- c("apple", "eggplant", "banana")
str_sort(x, locale = "en") # İngilizce
#> [1] "apple" "banana" "eggplant"
str_sort(x, locale = "haw") # Hawai dili
#> [1] "apple" "eggplant" "banana"14.2.5 Alıştırmalar
stringr’ı kullanmayan kodlarda, genelde
paste()vepaste0()göreceksiniz. Bu iki fonksiyonun farkı nedir? Bunlara eşit olan stringr fonksiyonu nedir? Bu fonksiyonlarınNAleri ele alış biçimleri nasıl farklılık gösterir?Kendi kelimelerinizle
str_c()nin argümanlarısepvecollapsearasındaki farkı açıklayın.Bir dizgenin ortasındaki karakteri çıkarmak için
str_length()vestr_sub()kullanın. Eğer dizgenin çift sayıda karakteri varsa ne yaparsınız?str_wrap()ne yapar? Bunu ne zaman kullanmak istersiniz?str_trim()ne yapar?str_trim()’in tersi nedir?Bir vektörü, örneğin
c("a", "b", "c")dizgeyea, b, ve cçevirecek bir fonksiyon yazın. Verilen vektörün uzunluğu 0, 1 ya da 2 olursa ne yapacağınız hakkında dikkatli düşün.
14.3 Kurallı ifadeler ile örüntüleri eşleştirme
Kurallı ifadeler (regexp’ler) dizgelerdeki örüntüleri tanımlamana izin veren özlü bir dildir. Alışana kadar biraz zamanınınızı alır ama bir kere anladığınızda çok kullanışlı bulacaksınız.
Kurallı ifadeleri öğrenmek için str_view() ve str_view_all() kullanacağız. Bu fonksiyonlar bir karakter vektörü ve bir kurallı ifade alırlar ve ikisinin nasıl eşleştiğini gösterirler. Çok basit kurallı ifadelerle başlayacağız, git gide karmaşıklaşacak. Bir kere örüntü eşleştirmede ustalaştıktan sonra bu fikirleri farklı stringr fonksiyonlarına nasıl uygulayacağımızı öğreneceksiniz.
14.3.1 Basit eşleşmeler
En basit örüntüler, dizgelerle eşleşir:
x <- c("elma", "muz", "armut")
str_view(x, "bir")Karmaşıklışmada bir sonraki seviye her karakterlerle (yeni satır hariç) eşleşebilen .:
str_view(x, ".bir.")Ama eğer “.” her karakterle eşleşiyorsa, “.” karakterini nasıl eşleştireceksiniz? Kurallı ifadeye bunu özel haliyle değil de olduğu gibi kullanmak istediğinizi söylemek için bir “escape” tuşunu kullanmalısınız. Dizgeler gibi kurallı ifadeler de özel davranıştan kaçınmak için ters taksim, \, kullanır. Yani bir .’yı eşleştirmek için, kurallı ifadede \.’e ihtiyacınız var. Maalesef bu bir problem yaratır. Dizgeleri kurallı ifadeleri temsil etmek için kullanırız ve \ dizgelerde de kaçış sembolü olarak kullanılır. Bu yüzden \. kurallı ifadesini oluşturmak için "\\." dizgesine ihtiyacımız vardır.
# Kurallı ifade oluşturmak için \\'a ihtiyacımız vardır
dot <- "\\."
# Ama ifadenin kendisi sadece bir tane içerir:
writeLines(dot)
#> \.
# ve bu R'a kesin bir ifadeye bakmasını söyler.
str_view(c("abc", "a.c", "bef"), "a\\.c")Eğer \ kurallı ifadede kaçış karakteri olarak kullanılıyorsa, gerçek bir \’ı nasıl eşleştirirsiniz? Kurallı ifade \\ı oluşturarak kaçmanız gerek. Bu kurallı ifadeyi oluşturmak için, \den kaçışa ihtiyacı olan bir dizge kullanmanız gerek. Yani bir \’ın gerçek halini eşleştirmek için "\\\\" yazmanız gerek — bir tane ters taksimi eşleştirmek için dört tanesine ihtiyacınız var!
x <- "a\\b"
writeLines(x)
#> a\b
str_view(x, "\\\\")Bu kitapta, kurallı ifadeleri \. olarak ve kurallı ifadeleri temsil eden dizgeleri "\\." olarak ifade edeceğim.
14.3.2 Sabitler
Kurallı ifadelerin dizgelerin her hangi bir kısmıyla eşleşeceği varsayılır. sabit (anchor) kurallı ifadeleri dizgenin sonuyla ya da başıyla eşleştirmek genellikle kullanışlıdır. Şunları kullanabilirsiniz:
Dizgenin başlangıcını eşleştirmek için:
^.Dizgenin sonunu eşleştirmek için:
$.
x <- c("apple", "banana", "pear")
str_view(x, "^a")Hangisinin hangisi olduğunu hatırlamak için Evan Misshula’dan öğrendiğim hatırlatıcı ipucunu kullanmayı deneyebilirsiniz: eğer kuvvet (^) ile başlarsanız, para ($) ile bitirirsiniz.
Bir kurallı ifadeyi bir dizgenin tamamı ile eşleşmeye zorlamak isterseniz, ^ ve $ ile sabitleyin:
x <- c("elmalı turta", "elma", "elmalı kek")
str_view(x, "elma")Ayrıca kelimeler arasındaki sınırları \b ile eşleştirebilirsin. Ben bunu R’da genellikle kullanmam, ama bazen RStudio’da başka bir fonksiyonun parçası olan bir fonksiyon için arama yaparken kullanırım. Örneğin summarise, summary, rowsum gibi eşleşmelerden kaçınmak için \bsum\b’ı ararım.
14.3.2.1 Alıştırmalar
Gerçek
"$^$"dizgesini nasıl eşlersiniz?stringr::words’un verdiği ortak esas kelimelerde, aşağıdaki özellikleri sağlayan kurallı ifadeleri bulun:- “y” ile başlayan.
- “x” ile biten
- Tam olarak üç harften oluşan. (
str_length()kullanaraak kopya çekmeyin!) - Yedi harf ya da fazlası olan.
Bu liste uzun olduğu için, sadece eşleşen ve eşleşmeyen kelimeleri
görmek için str_view()’in match argümanını kullanmak
isteyebilirsiniz.
14.3.3 Karakter sınıfları ve alternatifleri
Birden fazla karakterlerle eşleşen özel örüntüler vardır. Yeni satır hariç diğer tüm karakterlerle eşleşen .’yı çoktan gördünüz. Dört tane daha kullanışlı araç vardır:
\d: tüm sayılarla eşleşir.\s: tüm boşluklarla eşleşir (space, tab, yeni satır gibi).[abc]: a, b ya da c ile eşleşir.[^abc]: a, b ya da c dışında herşeyle eşleşir.
\d ya da \s içeren bir kurallı ifade oluşturmak için, dizgede \ kaçış elemanına ihtiyacınız olacağını unutmayın, yani "\\d" ya da "\\s" yazacaksınız.
Kurallı ifadeye tek bir metakarakteri dahil etmek istediğin,zde, tek karakter içeren bir karakter klası ters taksim kaçış sembolününü güzel bir alternatifidir. Pek çok insan bunu daha okunaklı bulur.
# Normalde regex'te özel anlamı olan kesin bir karaktere bakmak
str_view(c("abc", "a.c", "a*c", "a c"), "a[.]c")Bu pek çok (ama hepsi değil) kurallı ifade metakarakteri için çalışır: $ . | ? * + ( ) [ {. Maalesef, birkaç karakter bir karakter klasının içinde bile olsa özel anlamlarını taşır ve bunu ele almak için ters taksim kaçış sembolü gerekir: ] \ ^ ve -.–>
Bir ya da birden fazla alternatif kalıp arasından seçmek için alternation kullanabilirsiniz. Örneğin, abc|d..f kalıbı ‘“abc”’ ya da "deaf" ile eşleşecek. Unutmayın ki |’in önceliği düşük olduğu için abc|xyz kalıbı abc ya da xyz ile eşleşecek ama abcyz ya da abxyz ile eşleşmeyecek. Matematiksel gösterimlerde olduğu gibi, eğer öncelik sırası karışıkılaşırsa isteğininiz ifadenin daha açık olması için parantez kullan:
str_view(c("grey", "gray"), "gr(e|a)y")14.3.3.1 Alıştırmalar
Aşağıdakileri içeren tüm kelimeleri bulmak için kurallı ifade oluşturun:
Sesli harfle başlayan.
Sadece sessiz harfler içeren. (İpucu: sesli olmayanlarla eşleştirmeyi düşünün.)
edile biten amaeedile bitmeyen.ingya daiseile biten.
“i, c’den sonra olmadığı sürece e’den önce” kuralını ampirik olarak doğrulayın.
“q”yu her zaman “u” mu takip eder?
Bir kelimenin Amerikan İngilizcesi değil de İngiliz İngilizcesi ile yazılmış olma olasılığı ile eşleşecek bir kurallı ifade yaz.
Ülkenizdeki telefon numaralarının yaygın yazımı ile eşleşecek bir kurallı ifade oluşturun.
14.3.4 Tekrarlama
Kuvvetteki bir sonraki adım, bir kalıbın kaç kere eşleştiğini kontrol etmeyi içerir:
?:0 ya da 1+: 1 ya da daha fazla*: 0 ya da daha fazla
x <- "1888 Roma rakamlarıyla yazılan en uzun yıldır: MDCCCLXXXVIII"
str_view(x, "CC?")Bu operatörlerin öncelikleri yüksektir, bu yüzden: Amerikan ya da İngiliz yazımını eşleştirmek için colou?r şeklinde yazabilirsiniz. Bu da pek çoğunun parantez gerektirdiği anlamına gelir, bana(na)+ gibi.
Ayrıca tam olarak kaç tane eşleşme olacağının sayısını da belirleyebilirsiniz:
{n}: tam olarak n{n,}: n ya da daha fazla{,m}: en fazla m tane{n,m}: n ve m arasında
str_view(x, "C{2}")Varsayılan olarak bu eşleşmeler “açgözlü”dür: mümkün olan en uzun dizgeyle eşleşirler. Sonrasına ? koyarak onları “tembel” yapıp mümkün olan en kısa dizgeyle eşleştirebilirsiniz. Bu kurallı ifadelerin ileri seviye bir özelliğidir ama olduğunu bilmek kullanışlıdır:
str_view(x, 'C{2,3}?')14.3.4.1 Alıştırmalar
?,+,*’ın{m,n}formundaki hallerini tanımlayın.Aşağıdaki kurallı ifadelerin neyle eşleşeceğini açıklayın:
^.*$"\\{.+\\}"\d{4}-\d{2}-\d{2}"\\\\{4}"
Aşağıdaki kelimelerin tümünü bulacak kurallı ifadeleri oluşturun:
- Üç sessiz harf ile başlayan.
- Ardarda üç ya da daha fazla sesli harfi olan.
- Ardarda iki ya da daha fazla sesli-sessiz harf çifti olan.
https://regexcrossword.com/challenges/beginner adresindeki başlangıç seviyesi kurallı ifade (regexp) bulmacasını çözün.
14.3.5 Gruplama ve geri-referanslama
Daha önce, kompleks ifadeleri belirginleştirmenin bir yolunun parantezler olduğunu öğrendiniz. Parantezler ayrıca bir sayılı (numbered) yakalama grubu (sayı 1, 2 vs.) oluşturur. Bir yakalama grubu parantez içindeki kurallı ifade kısmı ile eşleşen dizgenin kısımlarını (the part of the string) saklar. Bir öncekinde bir yakalama grubu ile eşleşen aynı yazıyı \1, \2 gibi geri-referanslama (backreferences) ile işaret edebilirsiniz. Örneğin, sonraki kurallı ifade tekrar eden harf çiftleri içeren tüm meyveleri bulur.
str_view(fruit, "(..)\\1", match = TRUE)(Kısaca bunların str_match() ile birleşince ne kadar kullanışlı olduklarını da göreceksiniz.)
14.3.5.1 Alıştırmalar
Aşağıdaki ifadelerin neyle eşleşeceğini kelimelerle tanımlayın:
(.)\1\1"(.)(.)\\2\\1"(..)\1"(.).\\1.\\1""(.)(.)(.).*\\3\\2\\1"
Aşağıdaki kelimelerle eşleşecek kurallı ifadeleri oluşturun:
Aynı karakterle başlayıp aynı karakterle biten.
Tekrar eden harf çifti içeren (örneğin “church” kelimesi “ch”yi iki kez tekrarlar.)
Bir harfin en az üç yerde tekrarını içeren (örneğin “eleven” kelimesi üç tane “e” içerir)
14.4 Araçlar
Şu ana kadar kurallı ifadelerin temellerini öğrendiniz, şimdi bunları gerçek problemlere nasıl uygulayacağınızı göreceksiniz. Bu bölümde aşağıdakileri yapmanızı sağlayacak geniş bir stringr fonksiyonlar yelpazesi bulunur:
Hangi dizgenin bir kalıpla eşleştiğini tanımlama.
Eşleşmelerin pozisyonlarını bulma.
Eşleşmelerin içeriğini elde etme.
Eşleşmelerin değerlerini yenileriyle değiştirme.
Bir dizgeyi bir eşleşmeye göre bölme.
Devam etmeden önce dikkat etmemiz gereken bir şey var: basit bir kurallı ifadeyle tüm problemleri denemek ve çözmek çok kolay çünkü kurallı ifadeler çok güçlüdür. Jamie Zawinski’nin deyimiyle:
Bazı insanlar bir problemle yüzleştiklerinde “Biliyorum, kurallı ifadeleri kullanacağımı.” diye düşünürler. Böylece artık iki problemleri vardır.
Uyarı niteliğinde bir hikaye olarak, mail adresinin geçerliliğini kontrol eden kurallı ifadeyi inceleyin:
(?:(?:\r\n)?[ \t])*(?:(?:(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t]
)+|\Z|(?=[\["()<>@,;:\\".\[\]]))|"(?:[^\"\r\\]|\\.|(?:(?:\r\n)?[ \t]))*"(?:(?:
\r\n)?[ \t])*)(?:\.(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(
?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|"(?:[^\"\r\\]|\\.|(?:(?:\r\n)?[
\t]))*"(?:(?:\r\n)?[ \t])*))*@(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\0
31]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\
](?:(?:\r\n)?[ \t])*)(?:\.(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031]+
(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:
(?:\r\n)?[ \t])*))*|(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z
|(?=[\["()<>@,;:\\".\[\]]))|"(?:[^\"\r\\]|\\.|(?:(?:\r\n)?[ \t]))*"(?:(?:\r\n)
?[ \t])*)*\<(?:(?:\r\n)?[ \t])*(?:@(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\
r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[
\t])*)(?:\.(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)
?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t]
)*))*(?:,@(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[
\t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*
)(?:\.(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t]
)+|\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*))*)
*:(?:(?:\r\n)?[ \t])*)?(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+
|\Z|(?=[\["()<>@,;:\\".\[\]]))|"(?:[^\"\r\\]|\\.|(?:(?:\r\n)?[ \t]))*"(?:(?:\r
\n)?[ \t])*)(?:\.(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:
\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|"(?:[^\"\r\\]|\\.|(?:(?:\r\n)?[ \t
]))*"(?:(?:\r\n)?[ \t])*))*@(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031
]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\](
?:(?:\r\n)?[ \t])*)(?:\.(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031]+(?
:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?
:\r\n)?[ \t])*))*\>(?:(?:\r\n)?[ \t])*)|(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?
:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|"(?:[^\"\r\\]|\\.|(?:(?:\r\n)?
[ \t]))*"(?:(?:\r\n)?[ \t])*)*:(?:(?:\r\n)?[ \t])*(?:(?:(?:[^()<>@,;:\\".\[\]
\000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|"(?:[^\"\r\\]|
\\.|(?:(?:\r\n)?[ \t]))*"(?:(?:\r\n)?[ \t])*)(?:\.(?:(?:\r\n)?[ \t])*(?:[^()<>
@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|"
(?:[^\"\r\\]|\\.|(?:(?:\r\n)?[ \t]))*"(?:(?:\r\n)?[ \t])*))*@(?:(?:\r\n)?[ \t]
)*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\
".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*)(?:\.(?:(?:\r\n)?[ \t])*(?
:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[
\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*))*|(?:[^()<>@,;:\\".\[\] \000-
\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|"(?:[^\"\r\\]|\\.|(
?:(?:\r\n)?[ \t]))*"(?:(?:\r\n)?[ \t])*)*\<(?:(?:\r\n)?[ \t])*(?:@(?:[^()<>@,;
:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([
^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*)(?:\.(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\"
.\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\
]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*))*(?:,@(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\
[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\]\
r\\]|\\.)*\](?:(?:\r\n)?[ \t])*)(?:\.(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\]
\000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\]\r\\]
|\\.)*\](?:(?:\r\n)?[ \t])*))*)*:(?:(?:\r\n)?[ \t])*)?(?:[^()<>@,;:\\".\[\] \0
00-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|"(?:[^\"\r\\]|\\
.|(?:(?:\r\n)?[ \t]))*"(?:(?:\r\n)?[ \t])*)(?:\.(?:(?:\r\n)?[ \t])*(?:[^()<>@,
;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|"(?
:[^\"\r\\]|\\.|(?:(?:\r\n)?[ \t]))*"(?:(?:\r\n)?[ \t])*))*@(?:(?:\r\n)?[ \t])*
(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".
\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*)(?:\.(?:(?:\r\n)?[ \t])*(?:[
^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\]
]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*))*\>(?:(?:\r\n)?[ \t])*)(?:,\s*(
?:(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\
".\[\]]))|"(?:[^\"\r\\]|\\.|(?:(?:\r\n)?[ \t]))*"(?:(?:\r\n)?[ \t])*)(?:\.(?:(
?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[
\["()<>@,;:\\".\[\]]))|"(?:[^\"\r\\]|\\.|(?:(?:\r\n)?[ \t]))*"(?:(?:\r\n)?[ \t
])*))*@(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t
])+|\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*)(?
:\.(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|
\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*))*|(?:
[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".\[\
]]))|"(?:[^\"\r\\]|\\.|(?:(?:\r\n)?[ \t]))*"(?:(?:\r\n)?[ \t])*)*\<(?:(?:\r\n)
?[ \t])*(?:@(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["
()<>@,;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*)(?:\.(?:(?:\r\n)
?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>
@,;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*))*(?:,@(?:(?:\r\n)?[
\t])*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,
;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*)(?:\.(?:(?:\r\n)?[ \t]
)*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\
".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*))*)*:(?:(?:\r\n)?[ \t])*)?
(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\["()<>@,;:\\".
\[\]]))|"(?:[^\"\r\\]|\\.|(?:(?:\r\n)?[ \t]))*"(?:(?:\r\n)?[ \t])*)(?:\.(?:(?:
\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z|(?=[\[
"()<>@,;:\\".\[\]]))|"(?:[^\"\r\\]|\\.|(?:(?:\r\n)?[ \t]))*"(?:(?:\r\n)?[ \t])
*))*@(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])
+|\Z|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*)(?:\
.(?:(?:\r\n)?[ \t])*(?:[^()<>@,;:\\".\[\] \000-\031]+(?:(?:(?:\r\n)?[ \t])+|\Z
|(?=[\["()<>@,;:\\".\[\]]))|\[([^\[\]\r\\]|\\.)*\](?:(?:\r\n)?[ \t])*))*\>(?:(
?:\r\n)?[ \t])*))*)?;\s*)Her nasılsa bu patolojik bir örnek (çünkü mail adresleri şaşırtıcı derecede karmaşıktır) ama gerçek kodda kullanılır. Detaylar için stackoverflow’daki tartışmaya http://stackoverflow.com/a/201378 bakın.
Bir programlama dilinin içinde olduğunu ve kullanabileceğin başka araçlar olduğunu unutmayın. Karmaşık bir kurallı ifade oluşturmak yerine, basit ifadelerden oluşan bir seri oluşturmak her zaman daha kolaydır. Eğer probleminizi çözecek tek bir kurallı ifade yazmakta zorlanıyorsanız, bir adım geri gidin ve problemi küçük parçalara ayırabilecek misiniz diye bir bakın, bir sonrakine geçmeden her bir zorluğu çözün.
14.4.1 Eşleşmeleri tespit etme
Bir karakter vektörünün bir kalıpla eşleşip eşleşmediğini tanımlamak için str_detect() kullanılır. Bu, girdiyle aynı uzunlukta bir mantık vektörü döndürür.
x <- c("elma", "muz", "armut")
str_detect(x, "e")
#> [1] TRUE FALSE FALSEBir mantık vektörünü sayısal bağlamda kullanırken FALSEın 0 ve TRUEnun 1 olduğunu unutmayın. Bu da büyük bir vektörde eşleşmeler hakkındaki soruları yanıtlamak istediğinizde sum()ı ve mean()i kullanışlı hale getirir.
# Kaç tane yaygın kelime t ile başlıyor?
sum(str_detect(words, "^t"))
#> [1] 65
# Yaygın kelimelerin sesli ile bitme oranı ne?
mean(str_detect(words, "[aeiou]$"))
#> [1] 0.277Karmaşık mantıksal şartlarınız olduğunda (örneğin d değilse a ve ya b ile eşleş ama c’yle eşleşme) tek bir kurallı ifade oluşturmak yerine mantıksal operatörleri birden fazla str_detect() ile çağırmak genallikle daha kolaydır. Örneğin, aşağıda herhangi iki sesli harf bulundurmayan tüm kelimeleri bulmanın iki yolu var:
# En az bir tane sesli harf içeren tüm kelimeleri bulun ve etkisiz hale getirin.
no_vowels_1 <- !str_detect(words, "[aeiou]")
# Sadece sessiz harf içeren (sesli harf içermeyen) tüm kelimeleri bulun.
no_vowels_2 <- str_detect(words, "^[^aeiou]+$")
identical(no_vowels_1, no_vowels_2)
#> [1] TRUESonuçlar aynı ama bence ilk yaklaşımı anlamak çok daha kolay. Eğer kurallı ifadeniz aşırı derecede karmaşıklaşırsa, küçük parçalara ayırmaya çalışın, her bir parçaya isim verin ve parçaları mantıksal operatörlerle birleştirin.
str_detect()in yaygın bir kullanımı bir kalıpla eşleşen elemanları seçmektir. Bunu mantıksal alt kümeleme ya da daha elverişli str_subset() sarıcısı ile yapabilirsiniz:
words[str_detect(words, "x$")]
#> [1] "box" "sex" "six" "tax"
str_subset(words, "x$")
#> [1] "box" "sex" "six" "tax"Bununla birlikte, yine de dizgelerin bir veri çerçevesinin bir sütunu olacaksa, yerine bir filtre kullanmak istersiniz:
df <- tibble(
word = words,
i = seq_along(word)
)
df %>%
filter(str_detect(word, "x$"))
#> # A tibble: 4 × 2
#> word i
#> <chr> <int>
#> 1 box 108
#> 2 sex 747
#> 3 six 772
#> 4 tax 841str_detect()in bir varyasyonu str_count()dur: basit bir evet ya da hayır yerine, bir dizgede kaç tane eşleşme olduğunu söyler:
x <- c("elma", "muz", "armut")
str_count(x, "a")
#> [1] 1 0 1
# Ortalama olarak bir kelimede kaç tane sesli harf vardır?
mean(str_count(words, "[aeiou]"))
#> [1] 1.99str_count()u mutate() ile beraber kullanmak olağandır:
df %>%
mutate(
vowels = str_count(word, "[aeiou]"),
consonants = str_count(word, "[^aeiou]")
)
#> # A tibble: 980 × 4
#> word i vowels consonants
#> <chr> <int> <int> <int>
#> 1 a 1 1 0
#> 2 able 2 2 2
#> 3 about 3 3 2
#> 4 absolute 4 4 4
#> 5 accept 5 2 4
#> 6 account 6 3 4
#> # … with 974 more rowsEşleşmelerin asla örtüşmediğine dikkat edin. Örneğin, "abababa"da "aba" kalıbı kaç kere eşleşir? Kurallı ifadeler buna üç değil iki der:
str_count("abababa", "aba")
#> [1] 2
str_view_all("abababa", "aba")str_view_all() kullanımına dikkat edin. Kısaca öğreneceğiniz gibi, pek çok stringr fonksiyonu çiftler halinde gelir: bir fonksiyon tek bir eşleşme ile çalışır, diğeri tüm eşleşmeler ile çalışır. İkinci fonksiyonun _all son eki olacaktır.
14.4.1.1 Alıştırmalar
Her bir zorlu görevi, hem tek bir kurallı ifade ile hem de birden fazla
str_detect()kombinasyonu ile çözün.xile başlayan ya da biten tüm kelimeleri bulun.Sesli harf ile başlayan ve sessiz harf ile biten tüm kelimeleri bulun.
Her bir sesli harfi en az bir kere içeren bir kelime var mı?
En yüksek sayıda sesli harf hangi kelimede vardır? Sesli harf oranının en yüksek olduğu kelime hangisidir? (İpucu: payda nedir?)
14.4.2 Eşleşmeleri elde etmek
Bir eşleşmenin gerçek dizgesini elde etmek için str_extract() kullanılır. Bunu kapalı göstermek için daha karmaşık bir örneğe ihtiyacımız var. VOIP sistemlerini test etmek için tasarlanmış ama kurallı ifadelerle pratik yapmaka için de kullanışlı olan Harvard sentences’i kullanacağım. Bunlar stringr::sentences tarafından sağlanır:
length(sentences)
#> [1] 720
head(sentences)
#> [1] "The birch canoe slid on the smooth planks."
#> [2] "Glue the sheet to the dark blue background."
#> [3] "It's easy to tell the depth of a well."
#> [4] "These days a chicken leg is a rare dish."
#> [5] "Rice is often served in round bowls."
#> [6] "The juice of lemons makes fine punch."İçinde bir renk geçen tüm cümleleri bulmak istediğimizi düşünelim. İlk olarak renk isimlerini içeren bir vektör oluştururuz ve bunu tek bir kurallı ifadeye çeviririz:
colours <- c("red", "orange", "yellow", "green", "blue", "purple")
colour_match <- str_c(colours, collapse = "|")
colour_match
#> [1] "red|orange|yellow|green|blue|purple"Şimdi içinde renk geçen cümleleri seçebiliriz ve hangi renk olduğunu bulmak için renkleri çıkarabiliriz:
has_colour <- str_subset(sentences, colour_match)
matches <- str_extract(has_colour, colour_match)
head(matches)
#> [1] "blue" "blue" "red" "red" "red" "blue"str_extract()ın sadece ilk eşleşmeyi çıkaracağına dikkat edin. İlk önce birden fazla eşleşmesi olan tüm cümeleleri seçmek bunu görmenin en kolay yolu:
more <- sentences[str_count(sentences, colour_match) > 1]
str_view_all(more, colour_match)Bu stringr fonksiyonları için yaygın bir kalıptır çünkü basit bir eşleşmeyle çalışmak daha kolay veri yapıları kullanmamıza izin verir. Tüm eşleşmeleri almak için str_extract_all() kullanın. Bu bir liste döndürür:
str_extract_all(more, colour_match)
#> [[1]]
#> [1] "blue" "red"
#>
#> [[2]]
#> [1] "green" "red"
#>
#> [[3]]
#> [1] "orange" "red"listeler ve yinelemeler’de listeleri daha detaylı öğreneceğiz.
Eğer simplify = TRUE kullanırsanız str_extract_all() kısa eşleşmeleri en uzun uzunluğa çıkaran bir matris çıktısı verir.
str_extract_all(more, colour_match, simplify = TRUE)
#> [,1] [,2]
#> [1,] "blue" "red"
#> [2,] "green" "red"
#> [3,] "orange" "red"
x <- c("a", "a b", "a b c")
str_extract_all(x, "[a-z]", simplify = TRUE)
#> [,1] [,2] [,3]
#> [1,] "a" "" ""
#> [2,] "a" "b" ""
#> [3,] "a" "b" "c"14.4.3 Grup eşleşmeleri
Bu bölümde önceden parantez kullanmanın eşleşmelerde öncelikleri açıklamak ve geri referans vermek için kullanımını konuşmuştuk. Parantezleri kompleks eşleşmeleri elde etmek için de kullanabilirsiniz. Örneğin, cümlelerdeki isimleri elde etmek istediğimizi düşünün. Sezgisel olarak (İngilizce için) “a” ya da “the”dan sonra gelen her kelimeye bakacağız. Kurallı ifadelerde bir kelimeyi tanımlamak biraz aldatıcıdır bu yüzden burada basit bir yaklaşım kullanacağım:
noun <- "(a|the) ([^ ]+)"
has_noun <- sentences %>%
str_subset(noun) %>%
head(10)
has_noun %>%
str_extract(noun)
#> [1] "the smooth" "the sheet" "the depth" "a chicken" "the parked"
#> [6] "the sun" "the huge" "the ball" "the woman" "a helps"str_extract() bize tüm eşleşmeyi verir; str_match() bize her bir ayrı parçayı verir. Bir karakter vektörü yerine, her bir tam eşeleşme için bir sütunu her bir grup için bir sütunun takip ettiği bir matris döndürür:
has_noun %>%
str_match(noun)
#> [,1] [,2] [,3]
#> [1,] "the smooth" "the" "smooth"
#> [2,] "the sheet" "the" "sheet"
#> [3,] "the depth" "the" "depth"
#> [4,] "a chicken" "a" "chicken"
#> [5,] "the parked" "the" "parked"
#> [6,] "the sun" "the" "sun"
#> [7,] "the huge" "the" "huge"
#> [8,] "the ball" "the" "ball"
#> [9,] "the woman" "the" "woman"
#> [10,] "a helps" "a" "helps"(Beklendiği gibi bizim isimleri tespit eden sezgisel metodumuz zayıf, naif ve park etmiş gibi sıfatları da seçiyor.)
Eğer verilerin bir tibble’da ise tidyr::extract() kullanmak genellikle daha kolaydır. Bu str_match() gibi çalışır ama yeni bir sütuna yerleştireceği eşleşmeleri isimlendirmenizi ister.
tibble(sentence = sentences) %>%
tidyr::extract(
sentence, c("article", "noun"), "(a|the) ([^ ]+)",
remove = FALSE
)
#> # A tibble: 720 × 3
#> sentence article noun
#> <chr> <chr> <chr>
#> 1 The birch canoe slid on the smooth planks. the smooth
#> 2 Glue the sheet to the dark blue background. the sheet
#> 3 It's easy to tell the depth of a well. the depth
#> 4 These days a chicken leg is a rare dish. a chicken
#> 5 Rice is often served in round bowls. <NA> <NA>
#> 6 The juice of lemons makes fine punch. <NA> <NA>
#> # … with 714 more rowsstr_extract()deki gibi eğer her bir dizgenin tüm eşleşmelerini istersen str_match_all()a ihtiyacımız var.
14.4.4 Eşleşmeleri yenisiyle değiştirme
str_replace() ve str_replace_all() eşleşmeleri yeni dizgelerle değiştirmenize izin verir. En kolay kullanımı bir kalıbı sabit bir dizge ile değiştirmektir.
x <- c("apple", "pear", "banana")
str_replace(x, "[aeiou]", "-")
#> [1] "-pple" "p-ar" "b-nana"
str_replace_all(x, "[aeiou]", "-")
#> [1] "-ppl-" "p--r" "b-n-n-"str_replace_all()a isimli bir vektör vererek birden fazla değişim yapabilirsiniz:
x <- c("1 house", "2 cars", "3 people")
str_replace_all(x, c("1" = "one", "2" = "two", "3" = "three"))
#> [1] "one house" "two cars" "three people"Sabit bir dizge ile değiştirmek yerine eşleşme bileşenlerini eklemek için geri referanslamayı da kullanabilirsiniz. Aşağıdaki kodda, ikinci ve üçüncü kelimelerin yerini değiştirdim.
sentences %>%
str_replace("([^ ]+) ([^ ]+) ([^ ]+)", "\\1 \\3 \\2") %>%
head(5)
#> [1] "The canoe birch slid on the smooth planks."
#> [2] "Glue sheet the to the dark blue background."
#> [3] "It's to easy tell the depth of a well."
#> [4] "These a days chicken leg is a rare dish."
#> [5] "Rice often is served in round bowls."14.4.5 Parçalarına bölme
str_split() bir dizgeyi parçalarına bölmek için kullanılır. Örneğin, bir cümleyi kelimelerine bölebiliriz:
sentences %>%
head(5) %>%
str_split(" ")
#> [[1]]
#> [1] "The" "birch" "canoe" "slid" "on" "the" "smooth"
#> [8] "planks."
#>
#> [[2]]
#> [1] "Glue" "the" "sheet" "to" "the"
#> [6] "dark" "blue" "background."
#>
#> [[3]]
#> [1] "It's" "easy" "to" "tell" "the" "depth" "of" "a" "well."
#>
#> [[4]]
#> [1] "These" "days" "a" "chicken" "leg" "is" "a"
#> [8] "rare" "dish."
#>
#> [[5]]
#> [1] "Rice" "is" "often" "served" "in" "round" "bowls."Her bir birleşen farklı sayıda parça içerebileceği için bu bir liste döndürür. Eğer uzunluğu 1 olan bir vektörle çalışıyorsanız en kolay şey sadece listenin ilk elemanını elde etmektir.
"a|b|c|d" %>%
str_split("\\|") %>%
.[[1]]
#> [1] "a" "b" "c" "d"Bir diğer yandan, liste döndüren diğer stringr fonksiyonları gibi bir matris döndürmek için simplify = TRUE kullanabilirsiniz.
sentences %>%
head(5) %>%
str_split(" ", simplify = TRUE)
#> [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
#> [1,] "The" "birch" "canoe" "slid" "on" "the" "smooth" "planks."
#> [2,] "Glue" "the" "sheet" "to" "the" "dark" "blue" "background."
#> [3,] "It's" "easy" "to" "tell" "the" "depth" "of" "a"
#> [4,] "These" "days" "a" "chicken" "leg" "is" "a" "rare"
#> [5,] "Rice" "is" "often" "served" "in" "round" "bowls." ""
#> [,9]
#> [1,] ""
#> [2,] ""
#> [3,] "well."
#> [4,] "dish."
#> [5,] ""Ayrıca parçaların maksimum sayısını da elde edebilirsiniz:
fields <- c("Name: Hadley", "Country: NZ", "Age: 35")
fields %>% str_split(": ", n = 2, simplify = TRUE)
#> [,1] [,2]
#> [1,] "Name" "Hadley"
#> [2,] "Country" "NZ"
#> [3,] "Age" "35"Dizgelerle kalıplarla bölmek yerine karakter, satır, cümle ve kelime boundary()leri ile de bölebilirsiniz:
x <- "This is a sentence. This is another sentence."
str_view_all(x, boundary("word"))14.4.6 Eşleşmeleri bulma
str_locate() ve str_locate_all() her bir eşleşmenin başlangıç ve bitiş pozisyonlarını verir. Diğer fonksiyonların hiçbiri tam olarak istediğini vermediğinde bunlar özellikle kullanışlı olur. Eşleşen kalıpları bulmak için str_locate(), onları elde elde etmek ve/veya modifiye etmek için ise str_sub() kullanabilirsiniz.
14.5 Diğer örüntü tipleri
Dizge olan bir örüntü kullandığınızda otomatik olarak bir regex() ile çağrılacak:
# Normal çağırma:
str_view(fruit, "nana")
# Kısaltması
str_view(fruit, regex("nana"))Eşleşmenin detaylarını kontrol etmek için regex()in diğer argümanlarını kullanabilirsiniz:
ignore_case = TRUEkarakterlerin büyük ya da küçük harflerle eşleşmelerine izin verir. Her zaman o anki lokali kullanır.str_view(bananas, regex("banana", ignore_case = TRUE))bananas <- c("banana", "Banana", "BANANA") str_view(bananas, "banana")multiline = TRUE,^ve$ın her bir dizgenin değil de her bir satırın başı ve sonuyla eşleşmesine izin verir.x <- "Line 1\nLine 2\nLine 3" str_extract_all(x, "^Line")[[1]] #> [1] "Line" str_extract_all(x, regex("^Line", multiline = TRUE))[[1]] #> [1] "Line" "Line" "Line"comments = TRUE, karmaşık kurallı ifadeleri daha anlaşılır yapmak için yorum ve boşluk eklemeye izin verir.#dan sonra gelen herşey gibi boşluklar göz ardı edilir. Gerçek bir boşluğu eşleştirmek için kaçış elemanı gerekir:"\\ ".phone <- regex(" \\(? # optional opening parens (\\d{3}) # area code [) -]? # optional closing parens, space, or dash (\\d{3}) # another three numbers [ -]? # optional space or dash (\\d{3}) # three more numbers ", comments = TRUE) str_match("514-791-8141", phone) #> [,1] [,2] [,3] [,4] #> [1,] "514-791-814" "514" "791" "814"dotall = TRUE,.yı\ndahil herşeyle eşleştirmeye izin verir.
regex() yerine kullanabieceğiniz üç farklı fonksiyon daha var:
fixed(): tam olarak spesifik bit dizgeleriyle eşleşir. Tüm özel kurallı ifadeleri göz ardı eder ve en alt seviyede yönetir. Karmaşık kaçışlardan kaçınmanıza izin verir ve kurallı ifadelerden daha hızlı olabilir. Aşağıdaki küçük karşılaştırma, basit bir örnek için yaklaşık 3 kat daha hızlı olduğunu gösterir.microbenchmark::microbenchmark( fixed = str_detect(sentences, fixed("the")), regex = str_detect(sentences, "the"), times = 20 ) #> Unit: microseconds #> expr min lq mean median uq max neval #> fixed 108 116 151 126 160 434 20 #> regex 355 361 395 391 420 493 20
İngilizce olmayan veriler için fixed() kullanmaktan kaçının. Bu problem yaratır çünkü bir karakteri ifade etmenin genellikle birden fazla yolu vardır. Örneğin, “á”yı tanımlamanın iki yolu var: tek bir karakter olarak ya da bir “a” ve aksan olarak:
```r
a1 <- "\u00e1"
a2 <- "a\u0301"
c(a1, a2)
#> [1] "á" "á"
a1 == a2
#> [1] FALSE
```
Bunlar aynı şekilde ifade ederler ama farklı tanımlandıkları için `fixed()` bir eşleşme bulamaz. İnsan karakter karşılaştırma kurallarına uymak için, şimdi tanımlanacak olan, `coll()`u kullanabilirsiniz.
```r
str_detect(a1, fixed(a2))
#> [1] FALSE
str_detect(a1, coll(a2))
#> [1] TRUE
```coll(): Standart karşılaştırma (collation) kuralları ile dizgeleri karşılaştırır. Büyük-küçük harfe duyarsız karşılaştırma yapmak için kullanışlıdır.coll()un, karakterleri karşılaştırmak için hangi kuralların kullanılacağını kontrol eden birlocale(lokal) parametresi aldığına dikkat edin! Maalesef dünyanın farklı kısımlarında farklı kurallar kullanılıyor!# Bu demek oluyor ki büyük-küçük harfe duyarsız eşleşme yaparken # bu farklılığın farkında olman gerekiyor: i <- c("I", "İ", "i", "ı") i #> [1] "I" "İ" "i" "ı" str_subset(i, coll("i", ignore_case = TRUE)) #> [1] "I" "i" str_subset(i, coll("i", ignore_case = TRUE, locale = "tr")) #> [1] "İ" "i"fixed()veregex()in her ikisinin deignore_caseargümanı vardır, ama lokal seçmenize izin vermezler: her zaman o anki lokali kullanırlar. Bunun ne olduğunu takip eden kodda görebilirsiniz:stringi::stri_locale_info() #> $Language #> [1] "en" #> #> $Country #> [1] "US" #> #> $Variant #> [1] "" #> #> $Name #> [1] "en_US"coll()un dezavantajı hızı;coll(),regex()vefixed()ile karşılaştırıldığında görece yavaş olmasıdır, çünkü hangi karakterlerin aynı olduğunu tanıma kuralı karışıktır.str_split()de gördüğün gibi sınırları eşleşleştirmek içinboundary()kullanabilirsiniz. Bunu ayrıca diğer fonksiyonlarla da kullanabilirsiniz:str_extract_all(x, boundary("word")) #> [[1]] #> [1] "This" "is" "a" "sentence"x <- "This is a sentence." str_view_all(x, boundary("word"))
14.6 Kurallı ifadelerin diğer kullanımları
Temel R’da kurallı ifadeleri kullanan iki kullanışlı fonksiyon vardır.
apropos()evrensel ekosistemde kullanılan mevcut tüm objeleri arar. Eğer fonksiyonun adını tam olarak hatırlayamazsanız bu kullanışlıdır.apropos("replace") #> [1] "%+replace%" "replace" "replace_na" "setReplaceMethod" #> [5] "str_replace" "str_replace_all" "str_replace_na" "theme_replace"dir()bir dizindeki tüm dosyaları listeler.patternargümanı bir kurallı ifade alır ve sadece kalıpla eşleşen dosyaları döndürür. Örneğin, o anki dizinde bulunan tüm R Markdown dosyalarını bulmak için:head(dir(pattern = "\\.Rmd$")) #> [1] "communicate-plots.Rmd" "communicate.Rmd" "datetimes.Rmd" #> [4] "EDA.Rmd" "explore.Rmd" "factors.Rmd"(Eğer
*.Rmdgibi “globs”larla daha rahatsan, bunlarıglob2rx()ile kurallı ifadeye dönüştürebilirsin)
14.7 stringi
stringr, stringi paketinin üstüne kurulmuştur. stringr, en yaygın dizge manipüle eden fonksiyonları dikkatlice tutan asgari bir fonksiyonlar setini barındırdığından kullanışlıdır. Diğer bir yandan stringi daha kapsamlı şekilde tasarlanmıştır. İhtiyacınız olabilecek hemen her fonksiyonu içerir: stiringr’ın 49ı için stringi’ın 256 fonksiyonu vardır.
Eğer kendinizi stringr’da birşey yapmak için mücadele ederken bulursanız, stirngi’a göz atmaya değer. Bu paketler oldukça benzer çalışırlar, yani stringr bilgini çok doğal yollarla çevirebiliyor olmanız gerekir. Asıl fark önekleridir: str_ ve stri_.