1 Giriş
Veri bilimi, ham veriyi anlayışa, içgörüye ve bilgiye dönüştürmeye izin veren heyecan verici bir disiplindir. “Veri Bilimi için R” kitabının amacı size veri bilimi yapmanıza imkan verecek en önemli R araçlarını öğrenmede yardımcı olmaktır. Bu kitabı okuduktan sonra veri biliminde karşınıza çıkabilecek çok çeşitli problemleri R’ın en iyi özelliklerini kullanarak çözmek için yeterli araçlara sahip olacaksınız.
1.1 Ne öğreneceksiniz
Veri bilimi çok büyük bir alan ve bir kitabı okuyarak ustalaşmanın imkanı yok. Bu kitabın amacı size en önemli araçlar için sağlam bir altyapı vermek. Tipik bir veri bilimi projesinde ihtiyaç duyulan araç modelimiz şuna benzer:
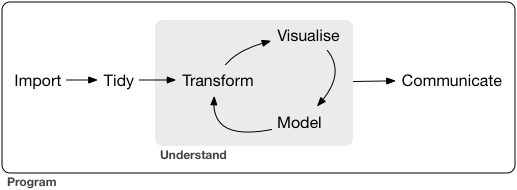
Öncelikle verilerinizi R’a yüklemeniz (import) gerekir. Bu genellikle bir dosyada, veritabanında veya web API’sinde depolanan verileri almanız ve R’daki bir veri tablosuna yüklemeniz anlamına gelir. Verilerinizi R’a alamazsanız üzerinde veri bilimi yapamazsınız!
Verilerinizi R’a yükledikten sonra, onu düzgün veri (tidy) haline getirmek iyi bir fikirdir. Verinizi düzgün veri haline getirmek saklanma şekli veri seti semantiğiyle eşleşen tutarlı bir biçimde depolamak anlamına gelir. Kısaca, verileriniz düzenli olduğunda her sütun bir değişken ve her satır bir gözlemdir. Düzenli veri önemlidir çünkü tutarlı yapı, mücadelenizi farklı işlevler için verileri doğru forma sokmak için mücadele etmek yerine verilerle ilgili sorulara odaklamanıza izin verir.
Düzenli veriye sahip olduğunuzda, genellikle ilk adım onu dönüştürmektir (transform). Dönüşüm, ilgilenilen gözlemleri daraltmayı (bir şehirdeki tüm insanlar veya geçen yıla ait tüm veriler gibi), mevcut değişkenlerin bir işlevi olan yeni değişkenler yaratmayı (mesafe ve zamandan hesaplama hızı gibi) ve bir dizi özet istatistikleri (sayımlar veya ortalamalar gibi) hesaplamayı içerir. Düzenleme ve dönüştürmeye birlikte veri cambazlığı (data wrangle) denir çünkü verilerinizi üzerinde çalışmak için doğal bir forma sokmak genellikle bir ipte yürümeye benzer!
İhtiyacınız olan değişkenleri içeren düzenli bir veriye sahip olduğunuzda bilgi üretiminin iki ana motoru vardır: görselleştirme ve modelleme. Bunların birbirini tamamlayıcı güçlü ve zayıf yönleri vardır, bu nedenle herhangi bir gerçek analiz aralarında birçok kez yinelenecektir.
Görselleştirme(visualise) temelde bir insan etkinliğidir. İyi bir görselleştirme, size beklemediğiniz şeyleri gösterecek veya veri hakkında yeni sorular ortaya çıkaracaktır. İyi bir görselleştirme yanlış soruyu sorduğunuzu veya farklı veriler toplamanız gerektiğini de gösterebilir. Görselleştirmeler sizi şaşırtabilir ancak onları yorumlamak için bir insan gerektirdiğinden çok da iyi ölçeklenmezler.
Modeller(model), görselleştirme için tamamlayıcı araçlardır. Sorularınızı yeterince kesinleştirdikten sonra cevaplamak için bir model kullanabilirsiniz. Modeller temelde matematiksel veya hesaplamalı bir araçtır, bu nedenle genellikle iyi ölçeklenirler. Ölçeklenmediklerinde bile genellikle daha fazla bilgisayar satın almak daha fazla beyin satın almaktan daha ucuzdur! Ancak her model varsayımlarda bulunur ve doğası gereği bir model kendi varsayımlarını sorgulayamaz. Bu, bir modelin sizi temelde şaşırtamayacağı anlamına gelir.
Veri biliminin son adımı herhangi bir veri analiz projesinin kesinlikle kritik bir parçası olan iletişim’dir. Sonuçlarınızı başkalarına da iletemediğiniz sürece modellerinizin ve görselleştirmenizin verileri anlamanıza ne kadar iyi yardımcı olduğu hiç önemli değildir.
Tüm bu araçları çevreleyen şey programlamadır. Programlama, projenin her bölümünde kullandığınız kesişen bir araçtır. Veri bilimcisi olmak için programlama konusunda uzman olmanıza gerek yoktur, ancak programlama hakkında daha fazla şey öğrenmek işe yarar çünkü daha iyi bir programcı olmak sıradan işleri otomatikleştirmenize ve yeni sorunları daha kolay çözmenize olanak tanır.
Bu araçları her veri bilimi projesinde kullanacaksınız, ancak çoğu proje için yeterli değiller. Burada kaba bir 80-20 kuralı var; bu kitapta öğreneceğiniz araçları kullanarak her projenin yaklaşık %80’ini halledebilirsiniz, ancak kalan %20’yi halletmek için başka araçlara ihtiyacınız olacak. Bu kitap boyunca sizi daha fazla bilgi edinebileceğiniz kaynaklara yönlendireceğiz.
1.2 Bu kitap nasıl organize edildi
Veri bilimi araçlarının önceki açıklaması bunları bir analizde kullandığınız sıraya göre kabaca düzenlenmiştir (tabii ki bunları birden çok kez yineleyeceksiniz). Ancak deneyimlerimize göre bunları öğrenmenin en iyi yolu bu değil:
Veriyi sindirmek ve düzenlemek ile başlamak en iyi yol değildir çünkü %80 intimalle rutin ve sıkıcıdır ve geri kalan %20 ihtimalle de garip ve sinir bozucu. Bu yeni bir konu öğrenmeye başlamak için kötü bir yer! Bunun yerine, zaten var olan ve düzgün verilerin görselleştirilmesi ve dönüştürülmesiyle başlayacağız. Bu şekilde, kendi verilerinizi alıp düzenlediğinizde motivasyonunuz yüksek kalacak çünkü acıya değdiğini biliyor olacaksınız
Bazı konular en iyi diğer araçlarla açıklanır. Örneğin, biz görselleştirme, düzenli veri ve programlama hakkında zaten bilgi sahibiyseniz, modellerin nasıl çalıştığını anlamanın daha kolay olduğuna inanıyoruz.
Programlama araçları başlı başına ilgi çekici değildir, ancak çok daha zorlu problemlerin üstesinden gelmenize izin verir. Kitabın ortasında size bir dizi programlama aracı vereceğiz ve ardından bunların ilginç modelleme problemlerini çözmek için veri bilimi araçlarıyla nasıl birleştirilebileceğini göreceksiniz.
Her bölümde benzer bir kalıba sadık kalmaya çalışıyoruz: daha büyük resmi görebilmeniz için bazı motive edici örneklerle başlayıp ve ardından ayrıntılara dalmak. Kitabın her bölümü öğrendiklerinizi uygulamanıza yardımcı olacak alıştırmalarla eşleştirilmiştir. Alıştırmaları atlamak cazip gelse de, öğrenmenin gerçek problemler üzerinde pratik yapmaktan daha iyi bir yolu yoktur.
1.3 Ne öğrenmeyeceksiniz
Bu kitabın kapsamadığı bazı önemli konular var. Çalışmaya mümkün olduğunca çabuk başlayabilmeniz için acımasızca temel şeylere odaklanmanın önemli olduğuna inanıyoruz. Bu, bu kitabın her önemli konuyu kapsayamayacağı anlamına gelir.
1.3.1 Büyük veri
Bu kitap gururla küçük, bellek-içi verisetlerine odaklanmaktadır. Bu, başlamak için doğru yerdir çünkü küçük verilerle deneyiminiz olmadıkça büyük verilerle baş edemezsiniz. Bu kitapta öğrendiğiniz araçlar yüzlerce megabaytlık veriyi kolayca işleyecektir ve biraz dikkat ederseniz genellikle bunları 1-2 GBlık verilerle çalışmak için kullanabilirsiniz. Rutin olarak daha büyük verilerle (10-100 GB) çalışıyorsanız data.table hakkında daha fazla şey öğrenmelisiniz. Bu kitap data.table’ı öğretmiyor çünkü çok kısa bir arayüze sahip olduğu için daha az dilsel ipucu sunuyor ve dolayısıyla öğrenmesi kolay değil. Ancak büyük verilerle çalışıyorsanız performans getirisi onu öğrenmek için gereken ekstra çabaya değer.
Eğer verileriniz bundan daha büyükse, büyük veri sorununuzun aslında kılık değiştirmiş küçük bir veri sorunu olup olmadığını dikkatlice düşünün. Tüm veri büyük olsa da belirli bir soruyu yanıtlamak için gereken veriler genellikle küçüktür. Belleğe sığan ve yine de ilgilendiğiniz soruyu yanıtlamanıza izin veren bir alt veri kümesi, alt örnek veya özet bulabilirsiniz. Buradaki zorluk genellikle doğru küçük veriyi bulmaktır, bu da genellikle bir çok yineleme gerektirir.
Diğer bir olasılık da büyük veri probleminizin aslında çok sayıda küçük veri problemi olmasıdır. Her bir problem belleğe sığabilir ancak bunlardan milyonlarcasına sahipsiniz. Örneğin, veri kümenizdeki her kişiye bir model sığdırmak isteyebilirsiniz. Sadece 10 veya 100 kişi olsaydı bu önemsiz olurdu ama bunun yerine bir milyon kişiniz var. Neyse ki, her sorun diğerlerinden bağımsızdır (bazen utanç verici bir şekilde paralel olarak adlandırılan bir kurulum), bu nedenle sadece farklı veri setlerini işlenmek üzere farklı bilgisayarlara göndermenize izin veren bir sisteme (Hadoop veya Spark gibi) ihtiyacınız vardır. Bu kitapta açıklanan araçları kullanarak tek bir alt küme için soruyu nasıl yanıtlayacağınızı çözdüğünüzde, tam verisetinde bu soruyu çözmek için sparklyr, rhipe ve ddr gibi yeni araçlar öğrenirsiniz.
1.3.2 Python, Julia, ve arkadaşlar
Bu kitapta Python, Julia veya veri bilimi için yararlı olan diğer programlama dilleri hakkında hiçbir şey öğrenmeyeceksiniz. Bunun nedeni bu araçların kötü olduğunu düşünmemiz değil. Kötü değiller! Ve pratikte, çoğu veri bilimi ekibi birden fazla dil kullanır, genellikle en azından R ve Python.
Ancak biz kesinlikle her seferinde bir araçta uzmanlaşmanın en iyisi olduğuna inanıyoruz. Kendinizi bir çok farklı konuya dağıtmak yerine bir tanesinde derinlere inerseniz daha hızlı iyi hale gelirsiniz. Bu, yalnızca bir şeyi bilmeniz gerektiği anlamına gelmez, yalnızca her seferinde bir şeye bağlı kalırsanız genellikle daha hızlı öğreneceğiniz anlamına gelir. Kariyeriniz boyunca yeni şeyler öğrenmeye çalışmalısınız ancak bir sonraki ilginç şeye geçmeden önce anladıklarınızın sağlam olduğundan emin olun.
R’ın veri bilimi yolculuğunuza başlamak için harika bir yer olduğunu düşünüyoruz çünkü veri bilimini desteklemek için sıfırdan tasarlanmış bir ortam. R sadece bir programlama dili değil, aynı zamanda veri bilimi yapmak için etkileşimli bir ortamdır. R bu etkileşimi desteklemek için akranlarının çoğundan çok daha esnek bir dildir. Tabi bu esnekliğin dezavantajları da vardır ancak en büyük artısı veri bilimi sürecinin belirli bölümleri için özellikle uyarlanmış dilbilgisi geliştirmenin ne kadar kolay olduğudur. Bu mini diller, bir veri bilimcisi olarak problemler hakkında düşünmenize yardımcı olurken beyniniz ve bilgisayar arasındaki akıcı etkileşimi destekler.
1.3.3 Dikdörtgen olmayan veri
Bu kitap yalnızca dikdörtgen verilere odaklanıyor: her biri bir değişken ve bir gözlemle ilişkilendirilen değer koleksiyonları. Bu paradigmaya doğal olarak uymayan pek çok veri seti vardır: görüntüler, sesler, ağaçlar ve metin dahil olmak üzere. Ancak dikdörtgen veri çerçeveleri bilimde ve endüstride son derece yaygındır ve veri bilimi yolculuğunuza başlamak için harika bir yer olduğuna inanıyoruz.
1.3.4 Hipotez doğrulama
Veri analizini iki kampa ayırmak mümkündür: hipotez oluşturma ve hipotez doğrulama (bazen doğrulayıcı analiz olarak adlandırılır). Bu kitabın odak noktası arsızca hipotez oluşturma veya veri keşfi üzerinedir. Burada verilere derinlemesine bakacaksınız ve konu hakkındaki bilginizle birlikte verilerin neden böyle davrandığını açıklamaya yardımcı olacak birçok ilginç hipotez üreteceksiniz. Verileri çeşitli şekillerde sorgulamak için şüpheciliğinizi kullanarak hipotezleri gayri resmi olarak değerlendirirsiniz.
Hipotez oluşturmanın tamamlayıcısı hipotez doğrulamadır. Hipotez doğrulamak iki sebepten ötürü zordur:
Yanlışlanabilir tahminler üretmek için çok net bir matematiksel modele ihtiyacınız vardır. Bu genellikle ileri seviyede bir istatistik uzmanlık gerektirir.
Bir hipotezi doğrulamak için bir gözlemi yalnızca bir kez kullanabilirsiniz. İkinci kez kullanmaya başladığınızda keşifsel analiz yapmaya geri dönmüşsünüz demektir. Bu, hipotez doğrulaması yapmak için analiz planınızı “erken-kaydetmeniz (önceden yazmanız) ve verileri gördüğünüzde bile ondan sapmamanız gerektiği anlamına gelir. Modelleme konusunda bunu kolaylaştıracak bazı stratejiler hakkında bir miktar konuşacağız.
Modellemeyi hipotez doğrulama için, görselleştirmeyi de hipotez oluşturma için bir araç olarak düşünmek genel bir kanıdır. Fakat bu yanlış bir ikilem: modeller genellikle keşif için iyidir ve birazcık dikkatle görselleştirmeyi doğrulamak için kullanabilirsiniz. Temel fark her gözleme ne kadar sıklıkla baktığınız: eğer bir kere bakarsanız, bu bir doğrulama, eğer birden fazla bakarsanız, bu bir keşif.
1.4 Ön koşullar
Bu kitaptan en iyi şekilde faydalanmak için neler bildiğinize dar bazı varsayımlar yaptık. Sayılar konusunda genel bir okur yazarlığınız olmalı ve halihazırda bir miktar programlama geçmişinizin olması faydalıdır. Eğer daha önce hiç programlama yapmadıysanız bu kitaba ek olarak Garrett’ın yazdığı Hands on Programming with R kitabını yararlı bulabilirsiniz.
Bu kitaptaki kodları çalıştırmak için dört şeye ihtiyacınız var: R, RStudio, tidyverse adı verilen bir paketler koleksiyonu ve faydalı bir kaç diğer paket. Paketler tekrarlanabilir R kodunun temel birimidir. Tekrar kullanılabilen fonksiyonlar ve onları nasıl kullanacağımızı anlatan belgeleri ve örnek veri setleri içerirler.
1.4.1 R
R’ı indirmek için CRAN’a (comprehensive R archive network) yani Kapsamlı R Arşivi Şebekesine gidin. CRAN, dünya çapında dağıtılan bir dizi ayna sunucusundan oluşur ve R ve R paketlerini dağıtmak için kullanılır. Size yakın bir ayna sunucu seçmeye çalışmayın, onun yerine bunu otomatik olarak bunu sizin için yapan bulut aynasını seçin https://cloud.r-project.org.
R’ın ana sürümleri yılda bir kez ve küçük sürümleri yılda 2-3 kez çıkıyor. Düzenli olarak güncelle yapmak iyi bir fikirdir. Yükseltme özellikle tüm paketlerinizi yeniden yüklemenizi gerektiren ana sürümler için biraz zor olabilir ancak bunu ertelemek işi yalnızca daha kötü hale getirir.
1.4.2 RStudio
RStudio R programlama için entegre bir geliştirme ortamıdır ya da EGO. RStudio’yu http://www.rstudio.com/download adresinden indirip yükleyebilirsiniz. Yılda bir kaç kez güncellemesi yayınlanır. Bir güncellemesi mevcut olduğunda RStudio size haber verecektir. Düzenli aralıklarla güncelleme yapmak iyi bir fikirdir böylece en son ve en iyi özelliklerden faydalanabilirsiniz. Bu kitap için RStudio 1.0.0’a sahip olduğunuzdan emin olun.
RStudio’yu başlattığınızda arayüzde iki temel bölge göreceksiniz:
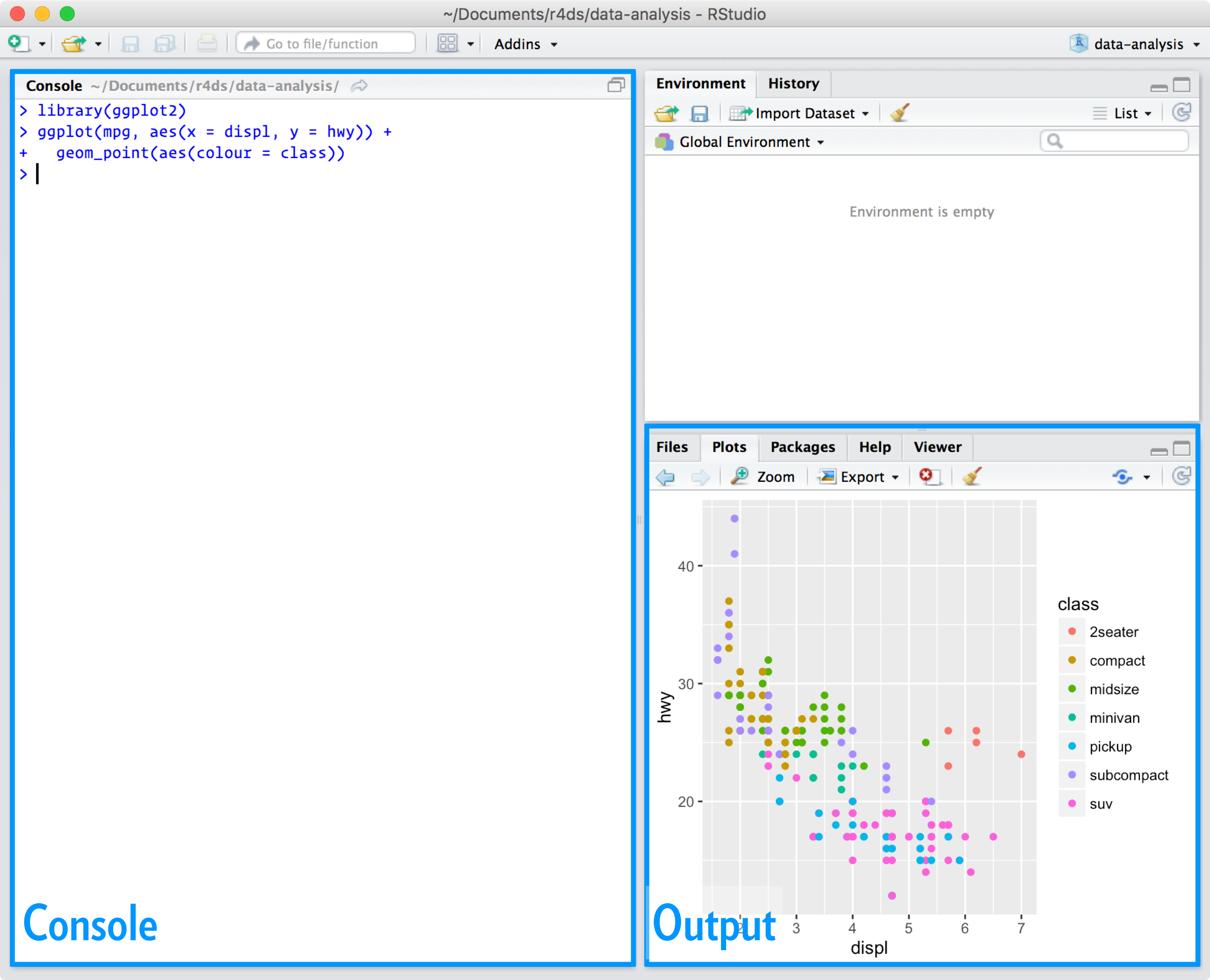
Şu an için sadece konsol paneline R kodu yazabileceğinizi, ve entera basarak çalıştırabileceğinizi bilmeniz yeterli. İLerledikçe daha fazlasını öğreneceksiniz.
1.4.3 tidyverse
Bazı paketler yüklemeniz de gerekecek. Bir paket R’ın temel yeteneklerini geliştiren fonksiyonlar, veri ve belgeler koleksiyonudur. Paketleri kullanmak başarılı R kullanımının anahtarıdır. Bu kitapta öğreneceğiniz paketlerin çoğu tidyverse’ün bir parçasıdır. Tidyverse içindeki paketler ortak bir veri ve programlama felsefesine sahiptir ve doğal bir şekilde birlikte çalışmak için tasarlanmıştır.
Tek bir satır kod ile tidyverse yüklemesini tamamlayabilirsiniz.
install.packages("tidyverse")Bu kodu kendi bilgisayarınızda konsola yazın ve entera basarak çalıştırın. R, paketleri CRAN’dan indirecek ve bilgisayarınıza yükleyecek. Yüklerken bir problemle karşılaşırsanız bilgisayarınızın internete bağlı olduğundan ya da firewall veya proxy ayarlarınıza bakıp https://cloud.r-project.org/ adresinin bloklu olmadığına emin olun.
library() ile paketi yüklemediğiniz sürece paketlerin içindeki fonksiyonları, objeleri ya da yardım dosyalarını kullanamayacaksınız. Bir paketi yüklediğinizde, library() fonksiyonunu kullanarak yüklemelisiniz.
library(tidyverse)
#> ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.1 ──
#> ✔ ggplot2 3.3.6 ✔ purrr 0.3.4
#> ✔ tibble 3.1.7 ✔ dplyr 1.0.9
#> ✔ tidyr 1.2.0 ✔ stringr 1.4.0
#> ✔ readr 2.1.2 ✔ forcats 0.5.1
#> ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()Bu kod size tidyverse’in ggplot2, tibble, tidyr, purr, ve dplyr paketlerini yüklediğini söyler. Bunlar tidyverse’in çekirdek paketleri olarak düşünülür çünkü neredeyse her analizde kullanılırlar.
tidyverse içindeki paketler oldukça sık bir şekilde değişir. Güncelleme olduğunu ve onları yüklemek için tidyverse_update() kodunu çalıştırabilirsiniz.
1.4.4 Diğer paketler
tidyverse’e dahil olmayan bir çok harika farklı paketler mevcut. Bu paketler farklı alanlardaki problemleri çözüyor ya da altında yatan farklı prensiplere sahip. Bu onları daha iyi ya da kötü yapmıyor, sadece farklılar. Bir başka deyişle, tidyverse’ü (düzenli evren) tamamlayıcı olan paketler messyverse (dağınık evren) değil birbiriyle ilişkili paketlerin diğer bir çok evrenidir. R ile daha fazla veri bilimi projesiyle uğraştıkça yeni paketler ve veriniz hakkında farklı şekilde düşünme yolları öğreneceksiniz.
Bu kitapta tidyverse dışında üç paket daha kullanacağız.
install.packages(c("nycflights13", "gapminder", "Lahman"))Bu paketler temel veri bilimi fikirlerini göstermek için havayolu uçuşları, dünya gelişimi, ve beyzbol hakkında veriler barındırıyor.
1.5 R kodu çalıştırma
Önceki bölüm size R kodunu çalıştırmanın birkaç örneğini gösterdi. Kod kitapta şöyle görünür:
1 + 2
#> [1] 3
#> [1] 3Aynı kodu kendi konsolunuzda çalıştırırsanız şöyle görünecektir:
> 1 + 2
[1] 3Bunlar arasında iki temel fark vardır. Sizin konsolunuzda, komut istemi olarak adlandırılan > işaretinden sonra yazarsınız; bu kitapta istemi göstermiyoruz. Kitapta, çıktı #> kullanarak yorum olarak gizlenmiştir; konsolunuzda ise kodunuzdan hemen sonra görünür. Bu iki fark kitabın elektronik versiyonunu kullanıyorsanız kodu kitaptan konsola kolayca kopyalayabileceğiniz anlamına gelir.
Bu kitap boyunca koda atıfta bulunmak için bir dizi tutarlı kural kullanıyoruz.
Fonksiyonlar kod yazı tipindedir ve parantez ile devam eder,
sum(), veyamean()gibi.Diğer R objeleri (veri ya da fonksiyon argümanları gibi) parantez olmadan kod fontundadır,
flightsveyaxgibi.Bir nesnenin hangi paketten geldiğini belirtmek istiyorsak bunu paket adının ardından iki nokta üst üste ‘dplyr::mutate()’ veya “nycflights13::uçuşlar” şeklinde belirtiriz. Bu da geçerli R kodudur.
1.6 Yardım edinmek ve daha fazla öğrenme
Bu kitap bir ada değil, size R’da uzmanlaşmanızı sağlayacak tek bir kaynak yok. Bu kitapta anlatılan teknikleri kendi verinize uygulamaya başladığınızda burada cevaplanmayan sorularla karşılaşmaya başlayacaksınız. Bu bölüm nasıl yardım alacağınıza ve öğrenmeye nasıl devam edeceğinize dair bir kaç ipucu paylaşıyor.
Eğer bir yerde takılırsanız Google ile başlayın. Genellikle aramanıza R eklemek alakalı sonuçları göstermek için faydalıdır, eğer arama yardımcı değilse bu genellikle R’a özgü sonuç olmadığı anlamına gelir. Google özellikle hata mesajları için önemlidir. Eğer bir hata mesajı alırsanız ve ne olduğu hakkında hiç bir fikriniz yoksa Googlelamayı deneyin! Geçmişte başka birisinin de bu mesajla kafası karışmış olabilir ve internetin bir yerlerinde yardım almış olabilir. (Eğer hata mesajı İngilizce değilse, önce Sys.setenv(LANGUAGE = "en")’ı çalıştırın ve ardından kodunuzu tekrar çalıştırın. İngilizce hata mesajları için yardım bulmanız daha olası.)
Eğer Google yardımcı olmazsa, stackoverflow’u deneyin. Aramanızı R kullanan soru ve yanıtlarla sınırlamak için [R] ekleyip mevcut bir yanıtı aramak için biraz zaman harcayın. eğer yararlı bir şey bulamazsanız minimal tekrarlanabilir bir örnek veya reprex hazırlayın. İyi bir tekrarnalanabilir örnek diğer insanların size yardımcı olabilmesini kolaylaştırır ve çoğu zaman sorunu bunu hazırlarken kendi başınıza çözersiniz.
Örneğinizi tekrarlanabilir yapmanız için ona dahil etmeniz gereken üç şey var: gerekli paketler, veri ve kod.
Paketler betiğin en üstüne yüklenmelidir böylece örneğin hangi paketlere ihtiyacı olduğu görülür. Bu, paketlerin güncel versiyonunu kullandığınızı kontrol etmek için iyi bir zaman çünkü daha önce çözülmüş olan bir bug bulmuş olma ihtimaliniz vardır. tidyverse içindeki paketler için bunu kontrol etmenin en kolay yolu
tidyverse_update()kodunu çalıştırmaktır.Sorunuza en kolay şekilde veri ekleme yolu onu yeniden oluşturacak R kodunu oluşturan
dput()kullanmaktır. Örneğin,mtcarsverisetini R’da yeniden oluşturmak için aşağıdaki adımları uygulardım:dput(mtcars)kodunu R’da çalıştırırım.- Çıktıyı kopyalarım
Verinizdeki problemi gösteren en küçük alt kümeyi bulmaya çalışın.
Yazdığınız kodun diğerleri için okunabilir olduğuna emin olmak için biraz zaman harcayın:
Boşlukları düzgün kullandığınızdan ve değişken adlarınızın az ama öz olduğundan emin olun.
Problemin nerede olduğunu anlatan yorumlar kullanın.
Problemle alakalı olmayan her şeyi sildiğinizden emin olun. Kodunuz ne kadar kısa olursa okuması ve anlaması da o kadar kolay olur, dolayısıyla problemi çözmesi de kolaylaşır.
Son olarak yeni bir R oturumu başlatıp, kodunuzu yapıştırarak tekrarlanabilir bir örnek oluşturduğunuzdan emin olarak bitirin.
Problemleri ortaya çıkmadan önce çözmeye de biraz zaman harcalamalısınız. Her gün biraz R öğrenmeye bir miktar zaman ayrımak uzun dönemde çok faydalı olan bir şeydir. Bunun bir yolu Hadley, Garret ya da RStudiyo’da çalışan diğer herkesin RStudio bloğunda yaptıklarını takip etmektir. Yeni paketler, yeni EGO özellikleri ve yüz-yüze kurslar hakkında duyuruları buradan yayınlıyoruz. Ayrıca Hadley’i (@hadleywickham) ya da Garrett’ı (@statgarrett) Twitter’dan takip edebilir, ya da EGO’daki yeni özelliklere ayak uydurmak için @rstudiotips’i takip edebilirsiniz.
R topluluğuna daha geniş bir şekilde ayak uydurmak için size http://www.r-bloggers.com sitesini okumanızı öneririz. Burada dünyanın dört bir yanında R hakkında yazan 500’den fazla blog toplanıyor. Eğer aktif bir Twitter kullanıcısıysanız #rstats hashtagini de takip edebilirsiniz. Twitter, Hadley’in topluluktaki yeni gelişmelere ayak uydurmak için kullandığı temel araçlardan biri.
1.7 Teşekkür
Bu kitap sadece Hadley ve Garrett’ın bir ürünü değil, aynı zamanda birçok insanla yaptığımız bir çok sohbetin (bireysel ve çevirimiçi) sonucudur. Aptalca sorularımızı cevaplamak için saatlerini harcamış ve bize veri bilimi hakkını daha iyi düşünmemiz konusunda yardımcı oldukları için özellikle teşekkür etmek istediğimiz bir kaç insan var.
Listeler ve liste-sütunlar konusunda yararlı tartışmalar için Jenny Bryan ve Lionel Henry’e
İş akışı üzerine olan üç bölüm Jenny Bryan’ı izniyle http://stat545.com/block002_hello-r-workspace-wd-project.html’den uyarlandı.
Modeller, modelleme, istatistiksel öğrenme perspektifi ve hipotez oluşturma ile hipotez doğrulama arasındaki fark hakkındaki tartışmalar için Genevera Allen’a
bookdown paketi üzerindeki çalışmaları ve özellik isteklerime yorulmadan yanıt verdiği için Yihui Xie’a.
Kitabın tamamını düşünceli bir şekilde okuduğu ve Stanford’daki veri bilimi sınıfında denediği için Bill Behrman’a,
Tüm taslak bölümleri gözden geçiren ve tonlarca faydalı geri bildirim sağlayan #rstats twitter topluluğuna
dendextend paketini nihai taslağa girmeyen kümeleme üzerine bir bölümü desteklemek üzere genişlettiği için Tal Galili’ye.
Bu kitap açık bir şekilde yazılmıştır ve birçok kişi küçük sorunları çözmek için çekme taleplerine katkıda bulunmuştur. GitHub aracılığıyla katkıda bulunan herkese çok teşekkürler:
Alfabetik sırayle tüm katkı sağlayanlara teşekkürler: adi pradhan, Ahmed ElGabbas, Ajay Deonarine, @Alex, Andrew Landgraf, bahadir cankardes, @batpigandme, @behrman, Ben Marwick, Bill Behrman, Brandon Greenwell, Brett Klamer, Christian G. Warden, Christian Mongeau, Colin Gillespie, Cooper Morris, Curtis Alexander, Daniel Gromer, David Clark, Derwin McGeary, Devin Pastoor, Dylan Cashman, Earl Brown, Eric Watt, Etienne B. Racine, Flemming Villalona, Gregory Jefferis, @harrismcgehee, Hengni Cai, Ian Lyttle, Ian Sealy, Jakub Nowosad, Jennifer (Jenny) Bryan, @jennybc, Jeroen Janssens, Jim Hester, @jjchern, Joanne Jang, John Sears, Jon Calder, Jonathan Page, @jonathanflint, Jose Roberto Ayala Solares, Julia Stewart Lowndes, Julian During, Justinas Petuchovas, Kara Woo, @kdpsingh, Kenny Darrell, Kirill Sevastyanenko, @koalabearski, @KyleHumphrey, Lawrence Wu, Matthew Sedaghatfar, Mine Cetinkaya-Rundel, @MJMarshall, Mustafa Ascha, @nate-d-olson, Nelson Areal, Nick Clark, @nickelas, Nirmal Patel, @nwaff, @OaCantona, Patrick Kennedy, @Paul, Peter Hurford, Rademeyer Vermaak, Radu Grosu, @rlzijdeman, Robert Schuessler, @robinlovelace, @robinsones, S’busiso Mkhondwane, @seamus-mckinsey, @seanpwilliams, Shannon Ellis, @shoili, @sibusiso16, @spirgel, Steve Mortimer, @svenski, Terence Teo, Thomas Klebel, TJ Mahr, Tom Prior, Will Beasley, @yahwes, Yihui Xie, @zeal626.
1.8 Baskı bilgisi
Bu kitabın online versiyonu http://r4ds.had.co.nz adresinde mevcut. Fiziksel kitabın yeni baskıları arasında evrimleşmeye devam edecektir. Kitabın kaynağı https://github.com/hadley/r4ds adresinde. Kitap R markdown dosyalarını HTML, PDF ve EPUB’a dönüştürmeyi kolaylaştıran https://bookdown.org’dan güç almaktadır.
Bu kitap aşağıdakilerle oluşturulmuştur.
devtools::session_info(c("tidyverse"))
#> ─ Session info ───────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.2.1 (2022-06-23)
#> os macOS Big Sur ... 10.16
#> system x86_64, darwin17.0
#> ui X11
#> language (EN)
#> collate en_US.UTF-8
#> ctype en_US.UTF-8
#> tz UTC
#> date 2022-07-05
#> pandoc 2.14.2 @ /usr/local/bin/ (via rmarkdown)
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> ! package * version date (UTC) lib source
#> askpass 1.1 2019-01-13 [1] CRAN (R 4.2.0)
#> assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.2.0)
#> backports 1.4.1 2021-12-13 [1] CRAN (R 4.2.0)
#> base64enc 0.1-3 2015-07-28 [1] CRAN (R 4.2.0)
#> bit 4.0.4 2020-08-04 [1] CRAN (R 4.2.0)
#> bit64 4.0.5 2020-08-30 [1] CRAN (R 4.2.0)
#> blob 1.2.3 2022-04-10 [1] CRAN (R 4.2.0)
#> broom 1.0.0 2022-07-01 [1] CRAN (R 4.2.0)
#> bslib 0.3.1 2021-10-06 [1] CRAN (R 4.2.0)
#> callr 3.7.0 2021-04-20 [1] CRAN (R 4.2.0)
#> cellranger 1.1.0 2016-07-27 [1] CRAN (R 4.2.0)
#> cli 3.3.0 2022-04-25 [1] CRAN (R 4.2.0)
#> clipr 0.8.0 2022-02-22 [1] CRAN (R 4.2.0)
#> colorspace 2.0-3 2022-02-21 [1] CRAN (R 4.2.0)
#> R cpp11 <NA> <NA> [?] <NA>
#> crayon 1.5.1 2022-03-26 [1] CRAN (R 4.2.0)
#> curl 4.3.2 2021-06-23 [1] CRAN (R 4.2.0)
#> data.table 1.14.2 2021-09-27 [1] CRAN (R 4.2.0)
#> DBI 1.1.3 2022-06-18 [1] CRAN (R 4.2.0)
#> dbplyr 2.2.1 2022-06-27 [1] CRAN (R 4.2.0)
#> digest 0.6.29 2021-12-01 [1] CRAN (R 4.2.0)
#> dplyr * 1.0.9 2022-04-28 [1] CRAN (R 4.2.0)
#> dtplyr 1.2.1 2022-01-19 [1] CRAN (R 4.2.0)
#> ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.2.0)
#> evaluate 0.15 2022-02-18 [1] CRAN (R 4.2.0)
#> fansi 1.0.3 2022-03-24 [1] CRAN (R 4.2.0)
#> farver 2.1.0 2021-02-28 [1] CRAN (R 4.2.0)
#> fastmap 1.1.0 2021-01-25 [1] CRAN (R 4.2.0)
#> forcats * 0.5.1 2021-01-27 [1] CRAN (R 4.2.0)
#> fs 1.5.2 2021-12-08 [1] CRAN (R 4.2.0)
#> gargle 1.2.0 2021-07-02 [1] CRAN (R 4.2.0)
#> generics 0.1.2 2022-01-31 [1] CRAN (R 4.2.0)
#> ggplot2 * 3.3.6 2022-05-03 [1] CRAN (R 4.2.0)
#> glue 1.6.2 2022-02-24 [1] CRAN (R 4.2.0)
#> googledrive 2.0.0 2021-07-08 [1] CRAN (R 4.2.0)
#> googlesheets4 1.0.0 2021-07-21 [1] CRAN (R 4.2.0)
#> gtable 0.3.0 2019-03-25 [1] CRAN (R 4.2.0)
#> haven 2.5.0 2022-04-15 [1] CRAN (R 4.2.0)
#> highr 0.9 2021-04-16 [1] CRAN (R 4.2.0)
#> hms 1.1.1 2021-09-26 [1] CRAN (R 4.2.0)
#> htmltools 0.5.2 2021-08-25 [1] CRAN (R 4.2.0)
#> httr 1.4.3 2022-05-04 [1] CRAN (R 4.2.0)
#> ids 1.0.1 2017-05-31 [1] CRAN (R 4.2.0)
#> isoband 0.2.5 2021-07-13 [1] CRAN (R 4.2.0)
#> jquerylib 0.1.4 2021-04-26 [1] CRAN (R 4.2.0)
#> jsonlite 1.8.0 2022-02-22 [1] CRAN (R 4.2.0)
#> knitr 1.39 2022-04-26 [1] CRAN (R 4.2.0)
#> labeling 0.4.2 2020-10-20 [1] CRAN (R 4.2.0)
#> lattice 0.20-45 2021-09-22 [2] CRAN (R 4.2.1)
#> lifecycle 1.0.1 2021-09-24 [1] CRAN (R 4.2.0)
#> lubridate 1.8.0 2021-10-07 [1] CRAN (R 4.2.0)
#> magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.2.0)
#> MASS 7.3-57 2022-04-22 [2] CRAN (R 4.2.1)
#> Matrix 1.4-1 2022-03-23 [2] CRAN (R 4.2.1)
#> mgcv 1.8-40 2022-03-29 [2] CRAN (R 4.2.1)
#> mime 0.12 2021-09-28 [1] CRAN (R 4.2.0)
#> modelr 0.1.8 2020-05-19 [1] CRAN (R 4.2.0)
#> munsell 0.5.0 2018-06-12 [1] CRAN (R 4.2.0)
#> nlme 3.1-157 2022-03-25 [2] CRAN (R 4.2.1)
#> openssl 2.0.2 2022-05-24 [1] CRAN (R 4.2.0)
#> pillar 1.7.0 2022-02-01 [1] CRAN (R 4.2.0)
#> pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.2.0)
#> processx 3.6.1 2022-06-17 [1] CRAN (R 4.2.0)
#> R progress <NA> <NA> [?] <NA>
#> ps 1.7.1 2022-06-18 [1] CRAN (R 4.2.0)
#> purrr * 0.3.4 2020-04-17 [1] CRAN (R 4.2.0)
#> R6 2.5.1 2021-08-19 [1] CRAN (R 4.2.0)
#> rappdirs 0.3.3 2021-01-31 [1] CRAN (R 4.2.0)
#> RColorBrewer 1.1-3 2022-04-03 [1] CRAN (R 4.2.0)
#> readr * 2.1.2 2022-01-30 [1] CRAN (R 4.2.0)
#> readxl 1.4.0 2022-03-28 [1] CRAN (R 4.2.0)
#> rematch 1.0.1 2016-04-21 [1] CRAN (R 4.2.0)
#> rematch2 2.1.2 2020-05-01 [1] CRAN (R 4.2.0)
#> reprex 2.0.1 2021-08-05 [1] CRAN (R 4.2.0)
#> rlang 1.0.3 2022-06-27 [1] CRAN (R 4.2.0)
#> rmarkdown 2.14 2022-04-25 [1] CRAN (R 4.2.0)
#> rstudioapi 0.13 2020-11-12 [1] CRAN (R 4.2.0)
#> rvest 1.0.2 2021-10-16 [1] CRAN (R 4.2.0)
#> sass 0.4.1 2022-03-23 [1] CRAN (R 4.2.0)
#> scales 1.2.0 2022-04-13 [1] CRAN (R 4.2.0)
#> selectr 0.4-2 2019-11-20 [1] CRAN (R 4.2.0)
#> stringi 1.7.6 2021-11-29 [1] CRAN (R 4.2.0)
#> stringr * 1.4.0 2019-02-10 [1] CRAN (R 4.2.0)
#> sys 3.4 2020-07-23 [1] CRAN (R 4.2.0)
#> tibble * 3.1.7 2022-05-03 [1] CRAN (R 4.2.0)
#> tidyr * 1.2.0 2022-02-01 [1] CRAN (R 4.2.0)
#> tidyselect 1.1.2 2022-02-21 [1] CRAN (R 4.2.0)
#> tidyverse * 1.3.1 2021-04-15 [1] CRAN (R 4.2.0)
#> tinytex 0.40 2022-06-15 [1] CRAN (R 4.2.0)
#> tzdb 0.3.0 2022-03-28 [1] CRAN (R 4.2.0)
#> utf8 1.2.2 2021-07-24 [1] CRAN (R 4.2.0)
#> uuid 1.1-0 2022-04-19 [1] CRAN (R 4.2.0)
#> vctrs 0.4.1 2022-04-13 [1] CRAN (R 4.2.0)
#> viridisLite 0.4.0 2021-04-13 [1] CRAN (R 4.2.0)
#> vroom 1.5.7 2021-11-30 [1] CRAN (R 4.2.0)
#> withr 2.5.0 2022-03-03 [1] CRAN (R 4.2.0)
#> xfun 0.31 2022-05-10 [1] CRAN (R 4.2.0)
#> xml2 1.3.3 2021-11-30 [1] CRAN (R 4.2.0)
#> yaml 2.3.5 2022-02-21 [1] CRAN (R 4.2.0)
#>
#> [1] /Users/runner/work/_temp/Library
#> [2] /Library/Frameworks/R.framework/Versions/4.2/Resources/library
#>
#> R ── Package was removed from disk.
#>
#> ──────────────────────────────────────────────────────────────────────────────