27 R Markdown
27.1 Giriş
R Markdown, veri bilimi uygulamaları için kod, sonuç ve yazılı notlarnızı birleştiren bir yazılım çerçevesi sağlar. R Markdown belgeleri tamamen yeniden üretilebilirdir ve PDF, Word dosyası, slayt gösterisi ve daha fazlası gibi düzinelerce farklı çıktı biçimini destekler.
R Markdown dosyaları üç şekilde kullanılmak üzere tasarlanmıştır:
Analizin arkasındaki kodlama detaylarına değil, sonuçlara odaklanmak isteyen karar vericilerle kolay iletişim kurmak için.
Hem sonuçlarınızla hem de onlara nasıl ulaştığınızla (yani kaynak kodla) ilgilenen diğer veri bilimcilerle (gelecekteki siz dahil!) iş birliği yapmak için.
Veri bilimi yapmak istediğiniz ortam içerisinde sadece ne yaptığınızı değil, aynı zamanda ne düşündüğünüzü de kayıt altına alan modern bir laboratuvar defteri gibidir.
R Markdown, bir dizi R paketini ve harici araçları entegre eder. Bu, yardım menüsüne genel olarak ? aracılığıyla ulaşamayacağınız anlamına gelir. Bunun yerine, bu bölümü çalışırken ve R Markdown’ı kullanırken aşağıdaki şu kaynakları elinizin altında bulundurun:
R Markdown hile listesi: Help > Cheatsheets > R Markdown Cheat Sheet,
R Markdown başvuru kılavuzu: Help > Cheatsheets > R Markdown Reference Guide.
Her iki listeyi aynı zamanda bu linkte de bulabilirsiniz http://rstudio.com/cheatsheets.
27.2 R Markdown temelleri
Bu .Rmd uzantısına sahip bir R Markdown düz metin dosyasıdır:
---
title: "Diamond sizes"
date: 2016-08-25
output: html_document
---
```{r setup, include = FALSE}
library(ggplot2)
library(dplyr)
smaller <- diamonds %>%
filter(carat <= 2.5)
```
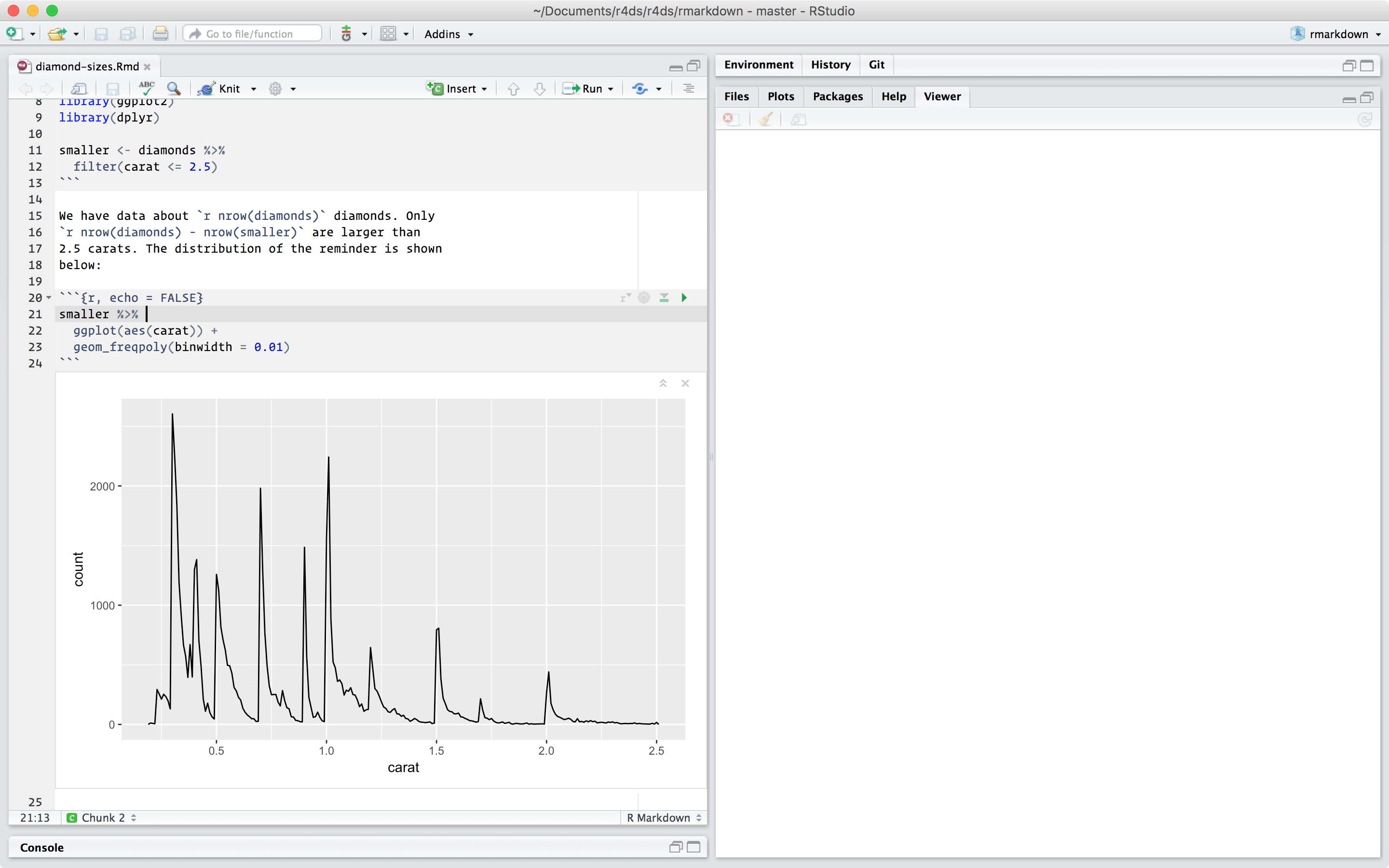
We have data about `r nrow(diamonds)` diamonds. Only
`r nrow(diamonds) - nrow(smaller)` are larger than
2.5 carats. The distribution of the remainder is shown
below:
```{r, echo = FALSE}
smaller %>%
ggplot(aes(carat)) +
geom_freqpoly(binwidth = 0.01)
```It contains three important types of content:
---ler ile çevrili bir YAML başlığı```ler ile çevrili bir Kod parçası.# başlıkve_italikler_gibi metin formatlaer.
Bir .Rmd dosyası açtığınızda, kod ve çıktının gösterildiği bir not defteri arabirimi elde edersiniz. Her kod parçasını Run simgesine tıklayarak (üst taraftaki panelde oynat düğmesi gibi görünür) veya Cmd/Ctrl + Shift + Enter tuşlarına aynı anda basarak çalıştırabilirsiniz. RStudio kodu yürütür ve sonuçları kodla aynı hizada görüntüler:
Tüm metni, kodları ve sonuçları içeren eksiksiz bir rapor oluşturmak için Knit butonuna tıklayın veya Cmd/Ctrl + Shift + K tuşlarına aynı anda basın. Bunu ayrıca programlı olarak rmarkdown::render("1-example.Rmd") ile de yapabilirsiniz. Bu, raporu görüntüleyici bölmesinde gösterecek ve başkalarıyla paylaşabileceğiniz bağımsız bir HTML dosyası oluşturacaktır.
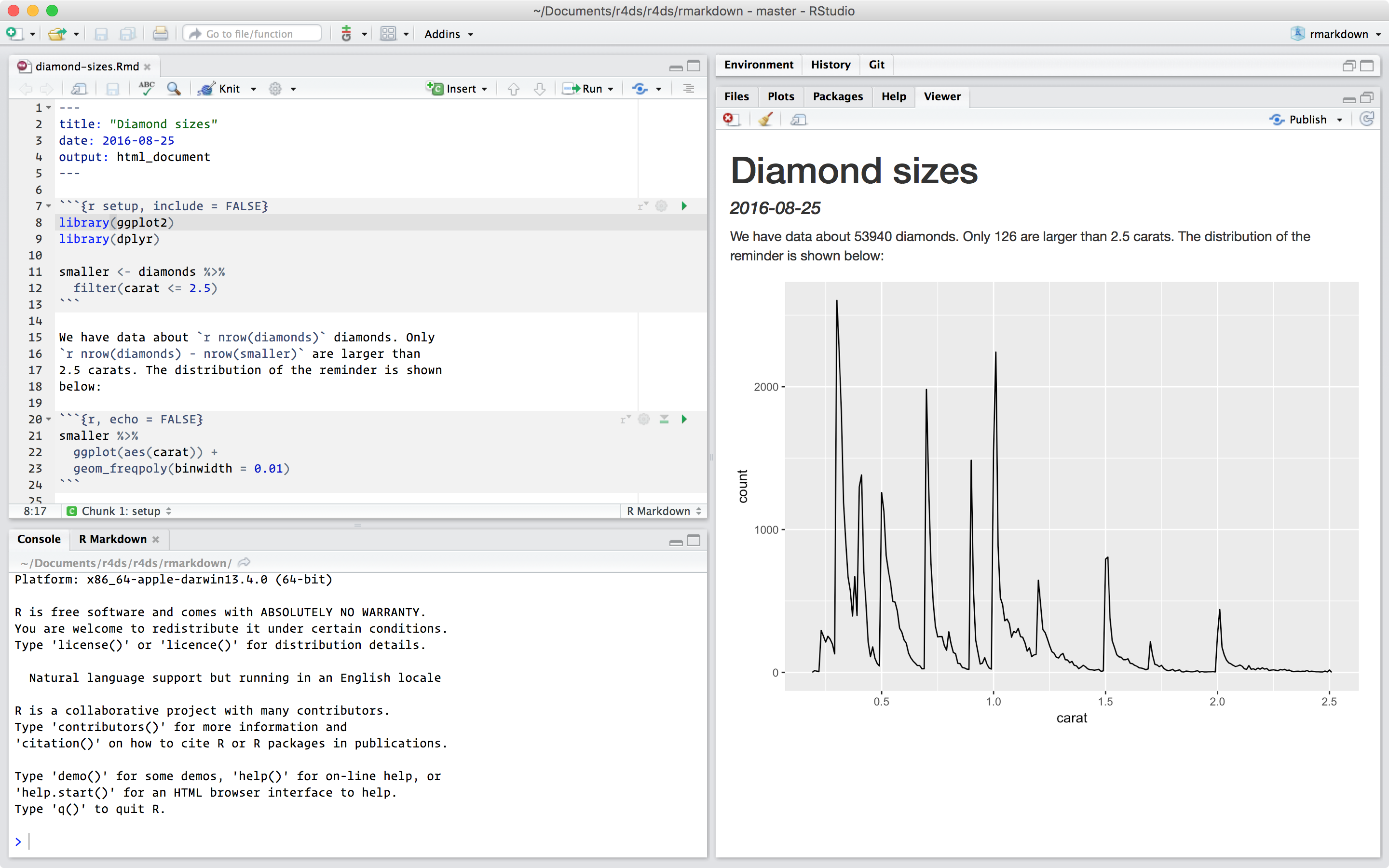
Belgeyi ördüğünüzde, R Markdown, .Rmd dosyasını Ör (Knit), http://yihui.name/knitr/ adresine gönderir; bu, tüm kod parçalarını yürütür ve kodlarla beraber sonuçları gösteren yeni bir markdown (.md) belgesi oluşturur. knitr tarafından oluşturulan markdown dosyası daha sonra bitmiş dosyayı oluşturmaktan sorumlu olan pandoc, http://pandoc.org/ tarafından işlenir. Bu iki adımlı iş akışının avantajı, kitabin “R markdown formatları” bölümünde öğreneceğiniz gibi, çok çeşitli çıktı formatları oluşturabilmenizdir.
Belgeyi knit yaptığınızda R Markdown, .Rmd dosyasını Knit, http://yihui.name/knitr/ adresine gönderir; bu, tüm kod parçalarını yürütür ve kodlarla beraber sonuçları gösteren yeni bir markdown (.md) belgesi oluşturur. knitr tarafından oluşturulan markdown dosyası daha sonra bitmiş dosyayı oluşturmaktan sorumlu olan pandoc, http://pandoc.org/ tarafından işlenir. Bu iki adımlı iş akışının avantajı, kitabin R Markdown Formatları bölümünde öğreneceğiniz gibi, çok çeşitli çıktı formatları oluşturabilmenizdir.

Kendi .Rmd dosyanızla başlamak istediğinizde menü çubuğundan sırayla File > New File > R Markdown… öğesini seçin. RStudio, dosyanızı R Markdown’ın temel özelliklerinin nasıl çalıştığını hatırlatan, ve onu faydalı içeriklerle hazır doldurabileceğiniz bir sihirbaz başlatacaktır.
Aşağıdaki bölümler, R Markdown belgelerinin üç bileşenini daha ayrıntılı olarak ele alır: markdown metni, kod parçaları ve YAML başlığı.
27.2.1 Alıştırmalar
File > New File > R Notebook kullanarak yeni bir not defteri oluşturun. Talimatları okuyun. Kod parçalarını çalıştırma alıştırması yapın. Kodu değiştirebildiğinizi, yeniden çalıştırabildiğinizi ve değiştirilmiş çıktıyı görebildiğinizi doğrulayın.
File > New File > R Markdown… yoluyla yeni bir markdown belgesi oluşturun. Uygun butona tıklayarak knit işlemini gerçekleştirin. Uygun klavye kısayolunu kullanarak knit işlemini gerçekleştirin. Girdiyi değiştirebildiğinizi ve çıktıda güncellemesini görebildiğinizi doğrulayın.
Yukarıda oluşturduğunuz R notebook ve R markdown dosyalarını karşılaştırın. Çıktılar ne kadar benzer ya da farklılar? Girdiler ne kadar benzer ya da farklılar? YAML başlığını birinden kopyalayıp diğerine yapıştırırsanız ne olur?
Üç hazır biçimin her biri için yeni bir R Markdown belgesi oluşturun: HTML, PDF ve Word. Üç belgenin her birine knit uygulayın. Çıktılar nasıl farklılık gösterir? Girdiler nasıl farklılık gösterir? (PDF çıktısını oluşturmak için LaTeX’i yüklemeniz gerekebilir- RStudio bunun gerekli olup olmadığını size soracaktır.)
27.3 Markdown ile metin oluşturma
Markdown .Rmd dosyalarındaki düz metin kısımlarını biçimlendirmeye yarayan basit kurallar seti olarak hazırlanmıştır. Markdown, okunması ve yazılması kolay olacak şekilde tasarlanmıştır. Ayrıca öğrenmesi çok kolaydır. Aşağıdaki kılavuz, R Markdown’ın okuyabildiği, genişletilmiş bir Markdown sürümü olan Pandoc Markdown’ın nasıl kullanılacağını gösterir.
Text formatting
------------------------------------------------------------
*italic* or _italic_
**bold** __bold__
`code`
superscript^2^ and subscript~2~
Headings
------------------------------------------------------------
# 1st Level Header
## 2nd Level Header
### 3rd Level Header
Lists
------------------------------------------------------------
* Bulleted list item 1
* Item 2
* Item 2a
* Item 2b
1. Numbered list item 1
1. Item 2. The numbers are incremented automatically in the output.
Links and images
------------------------------------------------------------
<http://example.com>
[linked phrase](http://example.com)

Tables
------------------------------------------------------------
First Header | Second Header
------------- | -------------
Content Cell | Content Cell
Content Cell | Content CellBunları öğrenmenin en iyi yolu denemektir. Birkaç gün sürecek, ancak sonrasında doğal refleks haline gelecekler ve düşünmenize gerek kalmayacaktır. Unutursanız Help > Markdown Quick Reference ile kullanışlı bir başvuru sayfasına ulaşabilirsiniz.
27.3.1 Alıştırmalar
Kısa bir özgeçmiş (CV) oluşturarak öğrendiklerinizi uygulayın. Ana başlık adınız olmalı ve (en azından) eğitim veya iş deneyimi için iki alt başlık eklemelisiniz. Bölümlerin her biri madde işaretli bir iş/derece listesi içermelidir. Yılı kalın harflerle vurgulayın.
R Markdown hızlı başvuruyu kullanarak şunları nasıl yapacağınızı öğrenin:
- Bir dipnot ekleyin.
- Yatay bir cetvel ekleyin.
- Bir alıntı paragrafı ekleyin.
https://github.com/hadley/r4ds/tree/master/rmarkdown
adresindendiamond-sizes.Rmdiçeriğini kopyalayıp yerel bir R Markdown belgesine yapıştırın. Çalıştırıp çalıştıramadığınızı kontrol edin, ardından ortaya çıkan sıklık poligonun sonuna, poligonun en çarpıcı özelliklerini açıklayan bir metin ekleyin.
27.4 Kod parçaları
Bir R Markdown belgesinde kodları çalıştırmak için bir kod parçası eklemeniz gerekir. Bunu yapmanın üç yolu vardır:
Cmd/Ctrl + Alt + I klavye kısa yolu ile
Düzenleme araç çubuğundaki “Insert” simgesi ile.
Kod parçası sınırları olan
```{r}ve```ı manuel olarak yazarak.
Ben elbette klavye kısa yolunu öğrenmenizi tavsiye ederim. Uzun vadede size çok zaman kazandıracak!
Kodları, şimdiye kadar öğrendiğiniz (umarım!) ve sevdiğiniz klavye kısa yolunu kullanarak çalıştırmaya devam edebilirsiniz: Cmd/Ctrl + Enter. Ancak, kod parçalarını toplu yürütmek başka bir klavye kısa yolu gerektirir: Cmd/Ctrl + Shift + Enter. Kod parçalarını fonksiyonlar gibi düşünün. Bir kod parçası nispeten bağımsız olmalı ve tek bir göreve odaklanmalıdır.
```{r’den sonra başlık ve isteğe bağlı olarak kod parçasının adı gelir. Bunu, virgülle ayrılmış opsiyonlar takip eder ve sonra } gelir. Sonra da, R kodunuz ve kodunuzun bittiğini belirten ``` gelir.
27.4.1 Kod parçası isimleri
Kod parçaları isteğe bağlı olarak isimlendirilebilir: ```{r by-name}. Bunun üç avantajı vardır:
Betik düzenleyicisinin sol alt kısmındaki açılır kod gezginini kullanarak belirli kod parçalarına daha kolay gidebilirsiniz:
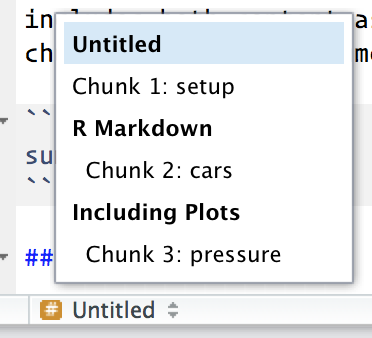
Yığınlarda üretilen grafikler, başka yerlerde kullanımı kolaylaştıran
faydalı adlara sahip olmalıdır. Daha fazla bilgiyi “Diğer önemli
seçeneklerde” kısmında bulabilirsiniz.Her yürütmede uzun hesaplamaları yeniden yapmaktan kaçınmak için önbelleğe alınmış kod parçası ağları kurabilirsiniz. Aşağıda bunun hakkında daha fazlasını bulabilirsiniz.
Özel davranış içeren bir kod parçası adı vardır: setup. Not defteri modundayken, başka bir kod çalıştırılmadan önce setup adlı parça otomatik olarak bir kez çalıştırılacaktır.
27.4.2 Kod parçası seçenekleri
Kod parçası çıktısı, kod parçası başlığına sağlanan argümanları içeren seçenekler opsiyonu ile özelleştirilebilir. Knitr, kod parçalarınızı özelleştirmek için kullanabileceğiniz yaklaşık 60 sunar. Burada sık kullanacağınız en önemli yığın seçeneklerini ele alacağız. Listenin tamamına http://yihui.name/knitr/options/ adresinden ulaşabilirsiniz.
En önemli seçenek grubu, kod bloğunuzun yürütülüp yürütülmediğini ve bitmiş rapora hangi sonuçların eklendiğini kontrol eder:
eval = FALSEkodun değerlendirilmesini engeller (Kod çalıştırılmazsa hiçbir sonuç üretilmez). Bu, örnek kodu görüntülemek veya her satırı görüntülemeden büyük bir kod bloğunu devre dışı bırakmak için kullanışlıdır.include = FALSEkodu çalıştırır, ancak son belgede kodu veya sonuçları göstermez. Raporunuzu karmaşık hale getirmek istemediğiniz durumlarda bunu kullanabilirsiniz.echo = FALSEkodu engeller, ancak sonuçların bitmiş dosyada görünmesini engellemez. R kodlarını görmek istemeyen kişilere yönelik raporlar yazarken bunu kullanabilirsiniz.message = FALSEtamamlanan dosyada mesajların,warning = FALSEuyarıların görülmesini egleller.results = 'hide'sonuç çıktısını saklar;fig.show = 'hide'grafikleri saklar.error = TRUEkod bir hata verse bile işlemenin devam etmesini sağlar. Bu raporunuzun son haline nadiren dahil etmek isteyeceğiniz bir şeydir, ancak.Rmddosyanızın içinde tam olarak neler olup bittiğini görmeniz gerekiyorsa çok yararlı olabilir. R öğretiyorsanız ve kasıtlı olarak bir hata eklemek istiyorsanız da yararlıdır. Varsayılanerror = FALSE, belgede tek bir hata varsa bile knit işlemini başarısız olarak sonuçlandırır.
Aşağıdaki tablo, her seçeneğin hangi tür çıktıları baskıladığını özetler:
| Option | Run code | Show code | Output | Plots | Messages | Warnings |
|---|---|---|---|---|---|---|
eval = FALSE |
- | - | - | - | - | |
include = FALSE |
- | - | - | - | - | |
echo = FALSE |
- | |||||
results = "hide" |
- | |||||
fig.show = "hide" |
- | |||||
message = FALSE |
- | |||||
warning = FALSE |
- |
27.4.3 Tablo
Varsayılan ayar olarak, R Markdown, veri çerçevelerini ve matrisleri konsolda gördüğünüz gibi yazdırır:
mtcars[1:5, ]
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> Mazda RX4 21.0 6 160 110 3.90 2.62 16.5 0 1 4 4
#> Mazda RX4 Wag 21.0 6 160 110 3.90 2.88 17.0 0 1 4 4
#> Datsun 710 22.8 4 108 93 3.85 2.32 18.6 1 1 4 1
#> Hornet 4 Drive 21.4 6 258 110 3.08 3.21 19.4 1 0 3 1
#> Hornet Sportabout 18.7 8 360 175 3.15 3.44 17.0 0 0 3 2Verilerin ek biçimlendirme ile görüntülenmesini tercih ederseniz, knitr::kable fonksiyonunu kullanabilirsiniz. Aşağıdaki kod, Tablo 27.1 oluşturur.
knitr::kable(
mtcars[1:5, ],
caption = "A knitr kable."
)| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mazda RX4 | 21.0 | 6 | 160 | 110 | 3.90 | 2.62 | 16.5 | 0 | 1 | 4 | 4 |
| Mazda RX4 Wag | 21.0 | 6 | 160 | 110 | 3.90 | 2.88 | 17.0 | 0 | 1 | 4 | 4 |
| Datsun 710 | 22.8 | 4 | 108 | 93 | 3.85 | 2.32 | 18.6 | 1 | 1 | 4 | 1 |
| Hornet 4 Drive | 21.4 | 6 | 258 | 110 | 3.08 | 3.21 | 19.4 | 1 | 0 | 3 | 1 |
| Hornet Sportabout | 18.7 | 8 | 360 | 175 | 3.15 | 3.44 | 17.0 | 0 | 0 | 3 | 2 |
Tabloyu özelleştirebileceğiniz diğer yöntemleri görmek için ?knitr::kable belgelerini okuyun. Daha ayrıntılı özelleştirme için xtable, stargazer, pander, tables, ve ascii paketlerini deneyebilirsiniz. Her biri, R kodundan biçimlendirilmiş tabloları oluşturmak için bir dizi araç sağlar.
Ayrıca, rakamların nasıl yerleştirildiğini kontrol etmek için bir dizi zengin seçenek vardır. Bunları grafiklerinizi kaydetme kısmında öğreneceksiniz.
27.4.4 Önbelleğe alma
Normalde, bir belgenin knit işlemi tamamen temiz bir sayfada başlar. Bu, tekrarlanabilirlik için harikadır çünkü her önemli hesaplamayı kodda görebilmenizi sağlar. Ancak, uzun zaman alan bazı hesaplamalarınız varsa acı verici olabilir. Çözüm kodu cache = TRUE. Kullanıldığında kod parçasının çıktısını diskte özel olarak adlandırılmış bir dosyaya kaydeder. Sonraki çalıştırmalarda, knitr kodun değişip değişmediğini kontrol edecek ve değişmediyse, önbelleğe alınan sonuçları yeniden kullanacaktır.
Önbelleğe alma sistemi dikkatli kullanılmalıdır, çünkü varsayılan olarak yalnızca kodu temel alır. Örneğin, burada processed_data (işlenmiş veri) yığını, raw_data (ham veri) yığınına bağlıdır:
```{r raw_data}
rawdata <- readr::read_csv("a_very_large_file.csv")
```
```{r processed_data, cache = TRUE}
processed_data <- rawdata %>%
filter(!is.na(import_var)) %>%
mutate(new_variable = complicated_transformation(x, y, z))
```processed_data (işlenmiş veri) kod parçasının önbelleğe alınması, dplyr pipeline’ı değiştirilirse yeniden çalıştırılabileceği, ancak read_csv() çağrısı değiştiğinde yeniden çalıştırılamayacağı anlamına gelir. Bu sorunu dependson kod parçası seçeneğiyle önleyebilirsiniz:
```{r processed_data, cache = TRUE, dependson = "raw_data"}
processed_data <- rawdata %>%
filter(!is.na(import_var)) %>%
mutate(new_variable = complicated_transformation(x, y, z))
```dependson önbelleğe alınmış kod parçasının bağlı olduğu her parçanın bir karakter vektörünü içermelidir. Knitr, bağımlılıklarından birinin değiştiğini algıladığında, önbelleğe alınan yığının sonuçlarını güncelleyecektir.
a_very_large_file.csv değişirse parçaların güncellenmeyeceğini unutmayın, çünkü knitr önbelleğe alırken yalnızca .Rmd dosyasındaki değişiklikleri izler. Bu dosyadaki değişiklikleri de izlemek istiyorsanız, cache.extra seçeneğini kullanabilirsiniz. Bu her değiştiğinde önbelleği geçersiz kılacak rastgele bir R kodudur. Kullanılacak başka iyi bir işlev ise file.info() en son ne zaman değiştirildiği de dahil olmak üzere dosya hakkında bir sürü bilgi verir. Aşağıdaki gibi yapabilirsiniz:
```{r raw_data, cache.extra = file.info("a_very_large_file.csv")}
rawdata <- readr::read_csv("a_very_large_file.csv")
```Önbelleğe alma stratejileriniz giderek daha karmaşık hale gelirse, tüm önbelleklerinizi knitr::clean_cache() ile düzenli olarak temizlemek iyi bir fikirdir.
Bu parçaları adlandırmak için David Robinson’ın tavsiyesini kullandım: her parça, yarattığı birincil nesnenin adını alır. Bu, dependson özelleştirmesinin anlaşılmasını kolaylaştırır.
27.4.5 Genel seçenekler
knitr ile daha fazla çalıştıkça, bazı varsayılan kod parçası seçeneklerinin ihtiyaçlarınıza uymadığını ve bunları değiştirmek istediğinizi keşfedeceksiniz. Bunu bir kod parçasına knitr::opts_chunk$set() öğesini çağırarak yapabilirsiniz. Örneğin, ben kitap ve eğitim materyalleri yazarken şunları kullandım:
knitr::opts_chunk$set(
comment = "#>",
collapse = TRUE
)Bu, benim tercihim olan yazı formatlarını kullanır ve kod ile çıktının iç içe geçmesini sağlar. Öte yandan, bir rapor hazırlıyorsanız şunları ayarlayabilirsiniz:
knitr::opts_chunk$set(
echo = FALSE
)Bu işlem, kodu varsayılan olarak gizleyecektir, o yüzden yalnızca echo = TRUE ile kasıtlı olarak göstermeyi seçtiğiniz parçaları gösterir. message = FALSE ve warning = FALSE olarak ayarlamayı düşünebilirsiniz, ancak bunu yaparsanız son belgede herhangi bir ileti görmeyeceğiniz için sorunlarınızı çözmeniz zorlaşır.
27.4.6 Satır içi kodlar
R kodunu bir R Markdown belgesine gömmenin başka bir yolu daha vardır: `r `. Metinde verilerinizin özelliklerinden bahsederseniz bu çok faydalı olabilir. Örneğin, bölümün başında kullandığım örnek belgede:
Elimizde
`r nrow(diamonds)`elmasları hakkında veri var. Yalnızca`r nrow(diamonds) - nrow(smaller)`2,5 karattan büyüktür. Kalanın dağılımı aşağıda gösterilmiştir:
Rapora knit işlemi uygulandığında , bu hesaplamaların sonuçları metne eklenir:
Elimizde 53940 elmas hakkında veri var. Sadece 126’sı 2.5 karattan büyüktür. Kalanın dağılımı aşağıda gösterilmiştir:
Metne sayı eklerken, format() arkadaşınız olacaktır. Saçma bir doğruluk derecesinde yazdırmamak için digits (hane) sayısını ve sayıların daha kolay okunmasını sağlamak için bir big.mark (büyük işaret) ayarlamanıza olanak tanır. Bunları genellikle bir yardımcı fonksiyonla birleştiririm:
comma <- function(x) format(x, digits = 2, big.mark = ",")
comma(3452345)
#> [1] "3,452,345"
comma(.12358124331)
#> [1] "0.12"27.4.7 Alıştırmalar
Pırlanta parçaları () datasında pırlanta parçası boyutlarının (size) kesim (cut), renk (color) ve berraklığa (clarity) göre nasıl değiştiğini araştıran bir bölüm ekleyin. R kullanmayı bilmeyen biri için bir rapor yazdığınızı varsayalım ve her kod parçasında
echo = FALSEyerine genel bir seçenek belirleyin.https://github.com/hadley/r4ds/tree/master/rmarkdown adresinden
diamond-sizes.Rmdverisini indirin. En önemli özellikleri dahil olmak üzere, en büyük 20 pırlantayı sıralayan bir tablo oluşturun.Güzel biçimlendirilmiş bir çıktı üretmek için
comma()kullanarakdiamonds-sizes.Rmddosyasını değiştirin. Ayrıca 2.5 karattan büyük elmasların yüzdesini de ekleyin.d’nincvebbağlı olduğu ve hembhem dec’nina’ya bağlı olduğu bir kod parçası ağı kurun. Her yığınınlubridate::now()göstermesini sağlayın,cache = TRUEolarak ayarlayın, ardından önbelleğe alma konusunu anladığınızı doğrulayın.
27.5 Sorun giderme
Artık etkileşimli bir R ortamında olmadığınız için R Markdown belgelerinde sorun giderme zor olabilir, bu yüzden bazı yeni numaralar öğrenmeniz gerekecek. Her zaman denemeniz gereken ilk şey, aktif olmayan bir oturumda sorunu yeniden oluşturmaktır. R’ı yeniden başlatın, ardından tüm kodları yürütmek için Kod menüsünde, Çalıştır bölgesi altında Run all chunks seçeneğini kullanın veya Ctrl + Alt + R klavye kısa yoluyla yürütmeye ulaşabilirsiniz. Şanslıysanız, bu sorunu yeniden yaratır ve ne olduğunu etkileşimli olarak anlayabilirsiniz.
Bu işe yaramazsa, etkileşimli ortamınız ile R Markdown ortamı arasında farklı bir şey olmalıdır. Seçenekleri sistematik olarak keşfetmeniz gerekecek. En yaygın fark, çalışma dizinidir: bir R Markdown’ın çalışma dizini, içinde yaşadığı dizindir. Bir kod parçasına getwd() ekleyerek çalışma dizininin beklediğiniz gibi olup olmadığını kontrol edebilirsiniz.
Ardından, hataya neden olabilecek her şeyi beyin fırtınası yapın. R oturumunuzda ve R Markdown oturumunuzda her şeyin aynı olup olmadığını sistematik olarak kontrol etmeniz gerekecek. Bunu yapmanın en kolay yolu, soruna neden olan kod parçası üzerinde error = TRUE olarak ayarlamak ve ardından ayarların beklediğiniz gibi olup olmadığını kontrol etmek için print() ve str() yollarını kullanmaktır.
27.6 YAML başlığı
YAML başlığının parametrelerini değiştirerek diğer birçok “whole document” (tüm belge) ayarını kontrol edebilirsiniz. YAML’nin ne anlama geldiğini merak edebilirsiniz: Hiyerarşik verileri insanların okuması ve yazmasını kolaylaştırmak için tasarlanmış başka bir format dilidir. R Markdown çıktının birçok ayrıntısını kontrol etmek için bunu kullanır. Burada iki tanesini tartışacağız: belge parametreleri ve kaynakçalar.
27.6.1 Parametreler
R Markdown belgeleri, raporu oluşturduğunuzda değerleri ayarlanabilen bir veya daha fazla parametre içerebilir. Aynı raporu farklı değer girişleri için yeniden oluşturmak istediğinizde parametreler oldukça kullanışlıdır. Örneğin, şube bazında satış raporları, öğrenci bazında sınav sonuçları veya ülkelere göre demografik özetler üretiyor olabilirsiniz. Bir veya daha fazla parametre bildirmek için params alanını kullanabilirsiniz.
Bu örnek, hangi sınıf arabaların görüntüleneceğini belirlemek için bir my_class parametresi kullanır:
---
output: html_document
params:
my_class: "suv"
---
```{r setup, include = FALSE}
library(ggplot2)
library(dplyr)
class <- mpg %>% filter(class == params$my_class)
```
# Fuel economy for `r params$my_class`s
```{r, message = FALSE}
ggplot(class, aes(displ, hwy)) +
geom_point() +
geom_smooth(se = FALSE)
```Gördüğünüz gibi, parametreler kod parçaları içinde params adlı, sadece okunabilen (yani düzenlenemeyen) bir liste olarak mevcuttur.
Atomik vektörleri doğrudan YAML başlığına yazabilirsiniz. Parametre değerinin önüne !r ekleyerek rastgele R ifadelerini de çalıştırabilirsiniz. Bu, tarih/saat parametrelerini belirtmenin iyi bir yoludur.
params:
start: !r lubridate::ymd("2015-01-01")
snapshot: !r lubridate::ymd_hms("2015-01-01 12:30:00")RStudio içinde tek bir adımda parametreleri ayarlamak, rapor oluşturmak ve önizleme yapmak için Knit menüsündeki ” Knit with Parameters ” seçeneğini tıklayabilirsiniz. Başlıktaki diğer seçenekleri ayarlayarak iletişim kutusunu özelleştirebilirsiniz. Daha fazla ayrıntı için http://rmarkdown.rstudio.com/developer_parameterized_reports.html#parameter_user_interfaces adresine bakın.
Alternatif olarak, bu tür çok parametreli raporlar üretmeniz gerekiyorsa, bir parametre listesi params ile rmarkdown::render() öğesini çağırabilirsiniz:
rmarkdown::render("fuel-economy.Rmd", params = list(my_class = "suv"))Bu, özellikle purrr:pwalk() ile birlikte kullanıldığında oldukça güçlüdür. Aşağıdaki örnek, mpg veri serinde bulunan her class (sınıf) değeri için bir rapor oluşturur. İlk önce, raporun dosya adını (filename) ve parametreleri (params) vererek, her sınıf (class) için bir satır içeren veri çerçevesi oluşturuyoruz:
reports <- tibble(
class = unique(mpg$class),
filename = stringr::str_c("fuel-economy-", class, ".html"),
params = purrr::map(class, ~ list(my_class = .))
)
reports
#> # A tibble: 7 × 3
#> class filename params
#> <chr> <chr> <list>
#> 1 compact fuel-economy-compact.html <named list [1]>
#> 2 midsize fuel-economy-midsize.html <named list [1]>
#> 3 suv fuel-economy-suv.html <named list [1]>
#> 4 2seater fuel-economy-2seater.html <named list [1]>
#> 5 minivan fuel-economy-minivan.html <named list [1]>
#> 6 pickup fuel-economy-pickup.html <named list [1]>
#> # … with 1 more rowArdından, sütun adlarını render() sutun argümanlarıyla eşleştirir ve her satır için bir kez render() çağırmak için purr fonksiyonunun paralel yürütmeyi kullanırız:
reports %>%
select(output_file = filename, params) %>%
purrr::pwalk(rmarkdown::render, input = "fuel-economy.Rmd")27.6.2 Kaynakça ve atıflar
Pandoc, kaynakları çeşitli stillerde otomatik olarak alıntılar ve kaynakça oluşturabilir. Bu özelliği kullanmak için dosyanızın başlığındaki bibliography (kaynakça) alanını kullanarak bir kaynakça dosyası belirtin. Alan .Rmd dosyanızı içeren dizinden kaynakça dosyasını içeren dosyaya giden bir yol içermelidir:
bibliography: rmarkdown.bibBibLaTeX, BibTeX, endnote, medline dahil birçok yaygın kaynak formatını kullanabilirsiniz.
.Rmd dosyanızda bir alıntı oluşturmak için, ‘@’ + (ve) kaynakça dosyasındaki alıntı tanımlayıcısından oluşan bir anahtar kullanın. Ardından alıntıyı köşeli parantez içine alın. İşte bazı örnekler:
Separate multiple citations with a `;`: Blah blah [@smith04; @doe99].
You can add arbitrary comments inside the square brackets:
Blah blah [see @doe99, pp. 33-35; also @smith04, ch. 1].
Remove the square brackets to create an in-text citation: @smith04
says blah, or @smith04 [p. 33] says blah.
Add a `-` before the citation to suppress the author's name:
Smith says blah [-@smith04].R Markdown dosyanızı oluşturduğunda, bir kaynakça oluşturacak ve belgenizin sonuna ekleyecektir. Kaynakça, kaynak dosyanızdan atıf yapılan referansların her birini içerecek, ancak bir bölüm başlığı içermeyecektir. Sonuç olarak, dosyanızı kaynakça için # References (Referanslar) veya # Bibliography (Kaynakça) gibi bir bölüm başlığıyla bitirebilirsiniz.
csl alanında bir CSL (alıntı stil dili) dosyasına başvurarak alıntılarınızın ve kaynakçalarınızın stilini değiştirebilirsiniz:
bibliography: rmarkdown.bib
csl: apa.cslKaynakça alanında olduğu gibi, csl dosyanız da dosya yolunu içermelidir. Burada csl dosyasının .Rmd dosyasıyla aynı dizinde olduğunu varsayıyorum. Yaygın kaynakça stilleri için CSL stili dosyalarını bulabileceğiniz iyi bir yer http://github.com/citation-style-language/styles adresidir.
27.7 Daha fazla öğrenin
R Markdown hala nispeten genç ve hala hızla büyüyen bir sistemdir. Yeniliklerden haberdar olmak için en iyi yer resmi R Markdown web sitesidir: http://rmarkdown.rstudio.com.
Burada ele almadığımız iki önemli konu var: iş birliği ve fikirlerinizi diğer insanlara doğru bir şekilde paylaşmanın ayrıntıları. İş birliği, modern veri biliminin hayati bir parçasıdır. Git ve GitHub gibi sürüm kontrol araçlarını kullanarak hayatınızı çok daha kolaylaştırabilirsiniz. Size Git’i öğretecek iki ücretsiz kaynak öneriyoruz:
“Happy Git with R”: R kullanıcıları vasıtasıyla geliştirilen, Jenny Bryan tarafından toplanmış Git ve GitHub’a kullanıcı dostu bir giriş kitabıdır. Kitap çevrimiçi ve ücretsiz olarak mevcuttur: http://happygitwithr.com
Hadley tarafından yazılmış __R Paketleri__nin “Git ve GitHub” bölümünü çevrimiçi olarak ücretsiz okuyabilirsiniz: http://r-pkgs.had.co.nz/git.html.
Analizlerinizin sonuçlarını net bir şekilde iletebilmek için ne yapmanız gerektiğine değinmedim. Metninizi geliştirmek için, Joseph M. Williams ve Joseph Bizup tarafından yazılan Style: Lessons in Clarity and Grace’i ya da George Gopen tarafından yazılan The Sense of Structure: Writing from the Reader’s Perspective’i okumanızı ısrarla tavsiye ederim. Her iki kitap da cümlelerin ve paragrafların yapısını anlamanıza yardımcı olacak ve metinlerinizi daha net hale getirmek için araçlar sağlayacaktır. (Bu kitaplarin yenisi oldukça pahalı, ancak birçok İngilizce sınıfı tarafından kullanıldığı için çok sayıda ucuz ikinci el kopyaları vardır). Ayrıca George Gopen’in https://www.georgegopen.com/the-litigation-articles.html adresinde yazma üzerine bir dizi kısa makalesi bulunmaktadır. Burada her şey avukatlara yönelik hazırlanmış olsa da neredeyse tamamen veri bilimcileri için de geçerlidir.