3 Veri görselleştirme
3.1 Giriş
“Basit bir grafik bir veri analistinin aklına herhangi başka bir araçtan daha fazla bilgi getirmiştir.” — John Tukey
Bu bölüm size ggplot2 kullanarak verinizi nasıl görselleştirebileceğinizi öğretecek. R, birkaç grafik oluşturma sistemine sahip, ama ggplot2 aralarındaki en şık ve çok yönlü olanı. ggplot2 grafik dil bilgisi adında grafik oluşturma ve tanımlamaya uygun bir sistemi devreye sokar. ggplot2 ile bir sistemi öğrenip, birçok yere uygulayarak çok daha hızlı olabilirsiniz.
Eğer başlamadan önce ggplot2’nin teorik temeli hakkında daha fazla bilgilenmek isterseniz, “The Layered Grammar of Graphics” isimli belgeyi okumanızı öneririm, http://vita.had.co.nz/papers/layered-grammar.pdf .
3.1.1 Ön koşullar
Bu bölüm tidyverse paketinin ana bileşenlerinden biri olan ggplot2’ye odaklanmaktadır. Bu bölümde kullanacağımız veri setlerine, yardım sayfalarına ve fonksiyonlara ulaşabilmek için öncelikle aşağıdaki kodu kullanarak tidyverse paketini yükleyin:
library(tidyverse)
#> ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.1 ──
#> ✔ ggplot2 3.3.6 ✔ purrr 0.3.4
#> ✔ tibble 3.1.7 ✔ dplyr 1.0.9
#> ✔ tidyr 1.2.0 ✔ stringr 1.4.0
#> ✔ readr 2.1.2 ✔ forcats 0.5.1
#> ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()Bu tek satırlık kod; hemen hemen her veri analizinde kullanacağınız tidyverse paketini yükler. Ek olarak, size tidyverse’ün hangi fonksiyonlarının Temel R fonksiyonlarıyla (ya da yüklemiş olduğunuz başka paketlerin fonksiyonlarıyla) uyuşmadığını da söyler.
Eğer bu kodu çalıştırdığınızda “there is no package called ‘tidyverse’” (“‘tidyverse’ adında bir paket bulunmamaktadır”) şeklinde bir hata mesajı alırsanız, öncelikle tidyverse paketini kurmanız, sonra library() kodunu bir kere daha çalıştırmanız gerekir.
install.packages("tidyverse")
library(tidyverse)Bir paketi sadece bir kere kurmanız yeterlidir, ancak her yeni bir oturum başlattığınızda paketi çağırmanız gerekir.
Eğer bir fonksiyonun (ya da veri setinin) nereden geldiği konusunda daha açık olmamız gerekirse, package::function() (paket adı:fonksiyon adı) şeklinde özel bir kod kullanabiliriz. Mesela, ggplot2::ggplot() size açıkça ggplot2 paketinden ggplot() fonksiyonunu kullandığımızı söyler.
3.2 İlk adımlar
İlk grafiğimizi bir soruyu cevaplamak için kullanalım: Büyük motorlu araçlar, küçük motorlu araçlara göre daha fazla yakıt kullanır mı? Muhtemelen buna bir cevabınız zaten var, ama cevabınızı daha doğru sunmaya çalışın. Motor büyüklüğü ve yakıt verimi arasındaki ilişki neye benzer? Doğru orantılı mıdır? Ters orantılı mıdır? Doğrusal mıdır, değil midir?
3.2.1 mpg veri tablosu
ggplot2’nin içinde bulunana mpg veri tablosu ile cevabınızı test edebilirsiniz (ggplot2::mpg). Veri tablosu, değişkenlerin (sütunlar) ve gözlemlerin (satırlar) dikdörtgen bir derlemesidir. mpg, ABD Çevre Koruma Ajansı tarafından toplanmış olan 38 araba modeline ait gözlemleri içerir.
mpg
#> # A tibble: 234 × 11
#> manufacturer model displ year cyl trans drv cty hwy fl class
#> <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
#> 1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa…
#> 2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa…
#> 3 audi a4 2 2008 4 manual(m6) f 20 31 p compa…
#> 4 audi a4 2 2008 4 auto(av) f 21 30 p compa…
#> 5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa…
#> 6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa…
#> # … with 228 more rowsmpg içindeki değişkenler:
displ, bir arabanın litre biriminden motor büyüklüğü.hwy, bir arabanın galon başına mil (mpg) biriminden otobandaki yakıt verimi. Aynı mesafeyi kat ettiklerinde düşük yakıt verimli bir araba, yüksek yakıt verimli bir arabadan daha fazla yakıt tüketir.
mpg hakkında daha fazla bilgiye erişmek için, ?mpg kodunu çalıştırarak yardım sayfasını açabilirsiniz.
3.2.2 ggplot oluşturmak
mpg’nin grafiğini çizmek için aşağıdaki kodu x-eksenine displ, y-eksenine hwy gelecek şekilde çalıştırın:
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy))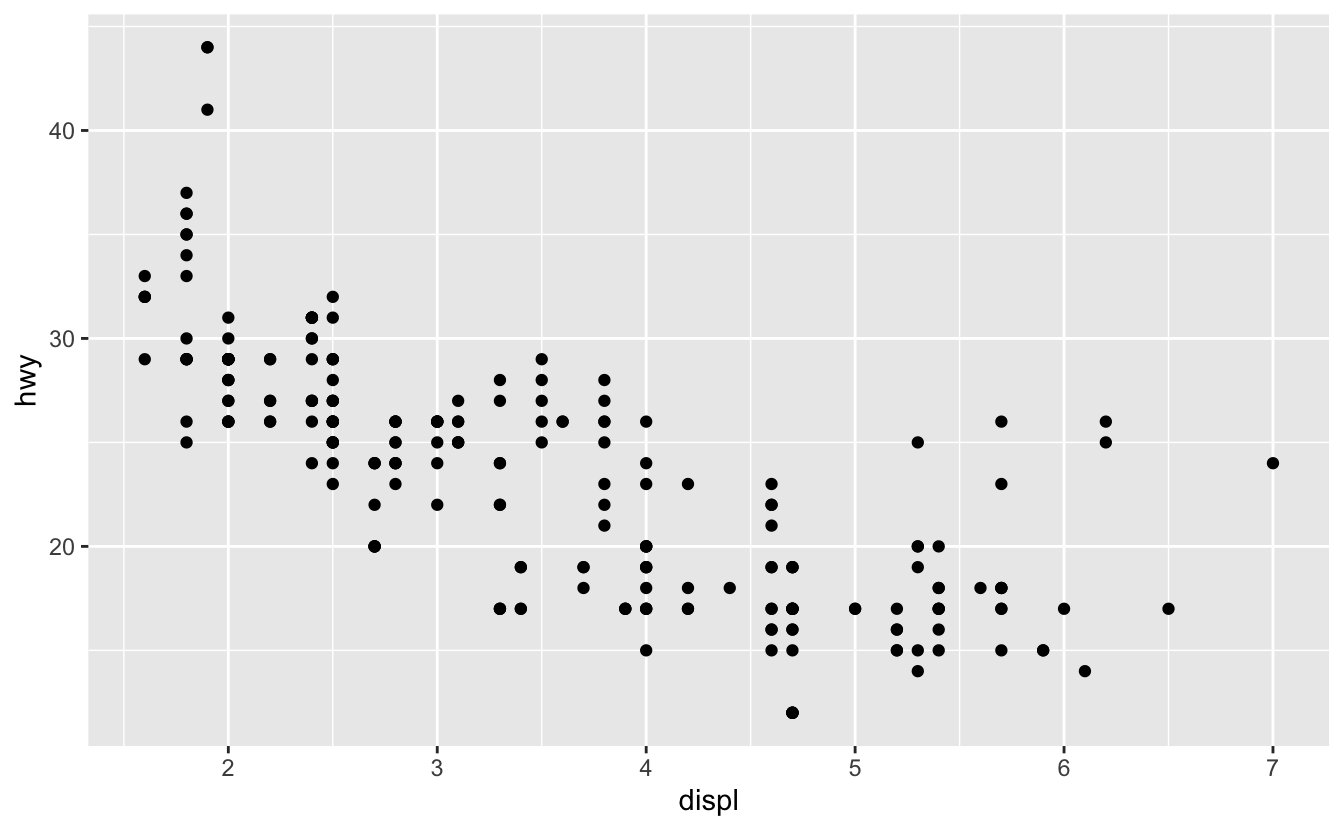
Grafik, motor büyüklüğü (displ) ve yakıt verimi (hwy) arasında ters orantılı bir ilişki gösteriyor. Başka bir deyişle, büyük motorlu araçlar daha fazla yakıt kullanıyor. Bu sonuç sizin yakıt verimi ve motor büyüklüğü hakkındaki hipotezinizle uyuşuyor mu?
ggplot2 ile grafik yapmaya ggplot() fonksiyonuyla başladınız. ggplot() katmanlar ekleyebileceğiniz bir koordinat sistemi oluşturuyor. ggplot() ’un ilk değişkeni grafiğini çizmek istediğiniz veri seti. Yani, ggplot(data = mpg) boş bir grafik oluşturuyor, ancak bu çok ilginç olmadıgından burada göstermeyeceğim.
Grafiğinizi ggplot()’a bir ya da birden fazla katman ekleyerek tamamlıyorsunuz. geom_point() fonksiyonu grafiğinize nokta katmanı ekler, bu da bir dağılım grafiği oluşturur. ggplot2 geom denilen birçok fonksiyon ile beraber gelir, her biri grafiğe başka tipte bir katman ekler. Bu bölüm boyunca bunlar hakkında birçok şey öğreneceksiniz.
ggplot2 içindeki her bir geom fonksiyonu için bir mapping değişkeni gerekmektedir. Bu veri setiniz içindeki değişkenlerin görsel özellikler ile nasıl eşleştirileceğini tanımlar. mapping değişkeni her zaman aes() ile aes()’in değişkenleri olan, x ve y eksenlerinin nerelerine gelmesi gerektiğini belirten x ve y argümanları ile beraberdir. ggplot2, data değişkeninin içinde tanımlanmış olan bu argümanları arar, bizim durumumuzda bu mpg’dir.
3.2.3 Grafik şablonu
Şimdi bu kodu ggplot2 ile grafik çizmek için tekrar kullanılabilen bir şablona dönüştürelim. Grafik çizmek için aşağıdaki kodda parantez içindeki yerleri bir veri seti, geom fonksiyonu veya bir eşleme (mapping ) derlemesi ile değiştirin.
ggplot(data = <DATA>) +
<GEOM_FUNCTION>(mapping = aes(<MAPPINGS>))Bu bölümün geri kalanı size farklı grafikler için bu şablonu nasıl tamamlamanız ve genişletmeniz gerektiğini anlatacak. <MAPPINGS> bileşeni ile başlayacağız.
3.2.4 Alıştırmalar
ggplot(data = mpg)kodunu çalıştırın. Ne görüyorsunuz?mpg’de kaç tane satır ve sütun var?drvdeğişkeni neyi tanımlıyor? Öğrenmek için?mpgile yardım sayfasını okuyun.hwyvecylilişkisinin dağılım grafiğini oluşturun.classvedrvilişkisinin dağılım grafiğini oluşturunca sonuç ne oluyor? Bu grafik neden kullanışlı değil?
3.3 Estetik eşleme
“Bir resmin en değerli olduğu an, bizi hiç beklemediğimiz bir şeyi görmeye zorladığı andır.” — John Tukey
Aşağıdaki grafikte, bir grup noktanın (kırmızıyla belirtilmiştir) doğrusal eğilimin dışına düştüğü görülüyor. Bu arabalar beklediğinizden daha fazla mesafe kat etmiş. Bu arabaları nasıl açıklarsınız?
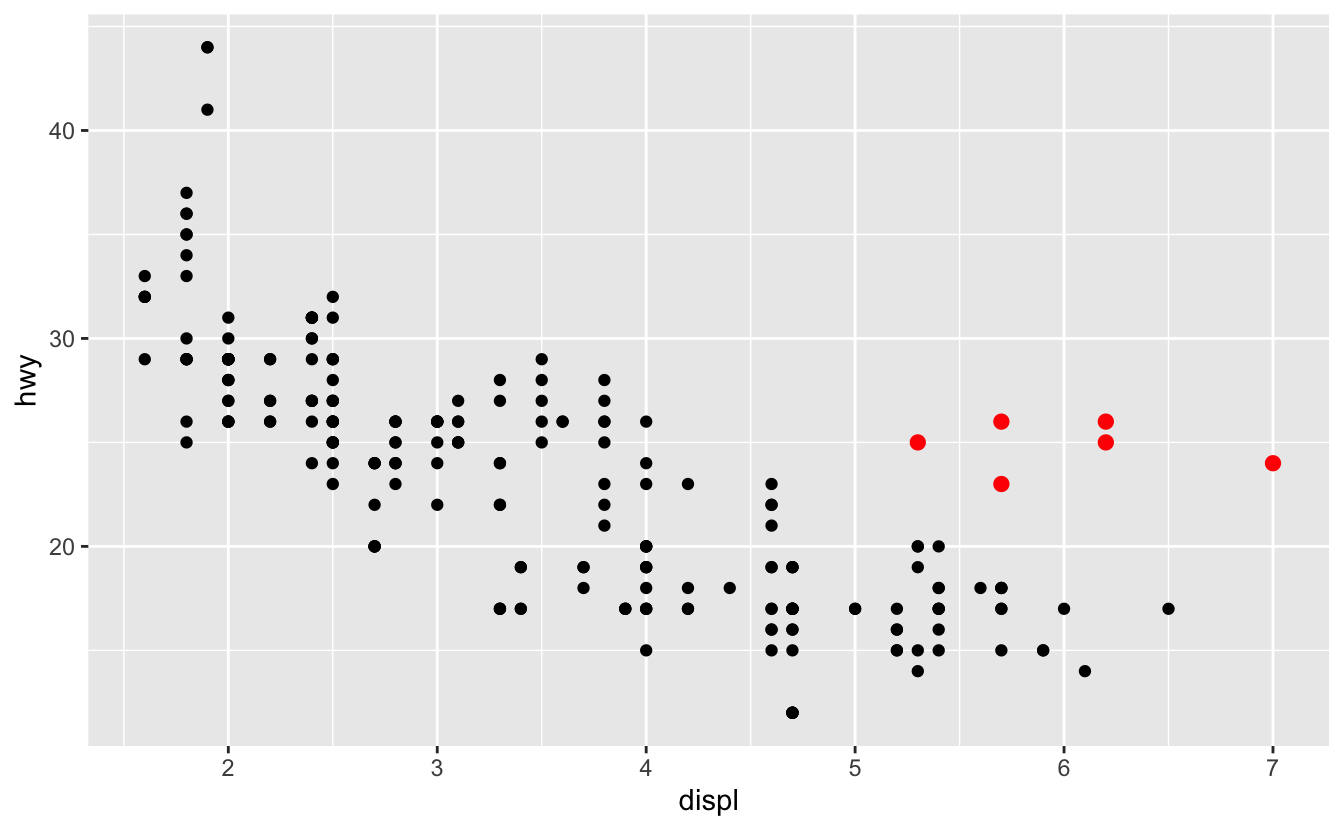
Bu arabaların hibrit olduklarını düşünelim. Bu hipotezi test etmenin bir yolu, her arabanın class değişkenine bakmaktır. mpg veri setinin içindeki class değişkeni arabaları kompakt, orta ölçekli ve SUV şeklinde sınıflandırır. Eğer dışarıda kalan noktalar hibritse bu arabalar kompakt ya da tercihen yarı-kompakt olarak sınıflandırılır (unutmayın ki bu veri hibrit kamyonlar ve SUVler popüler olmadan önce toplanmıştır).
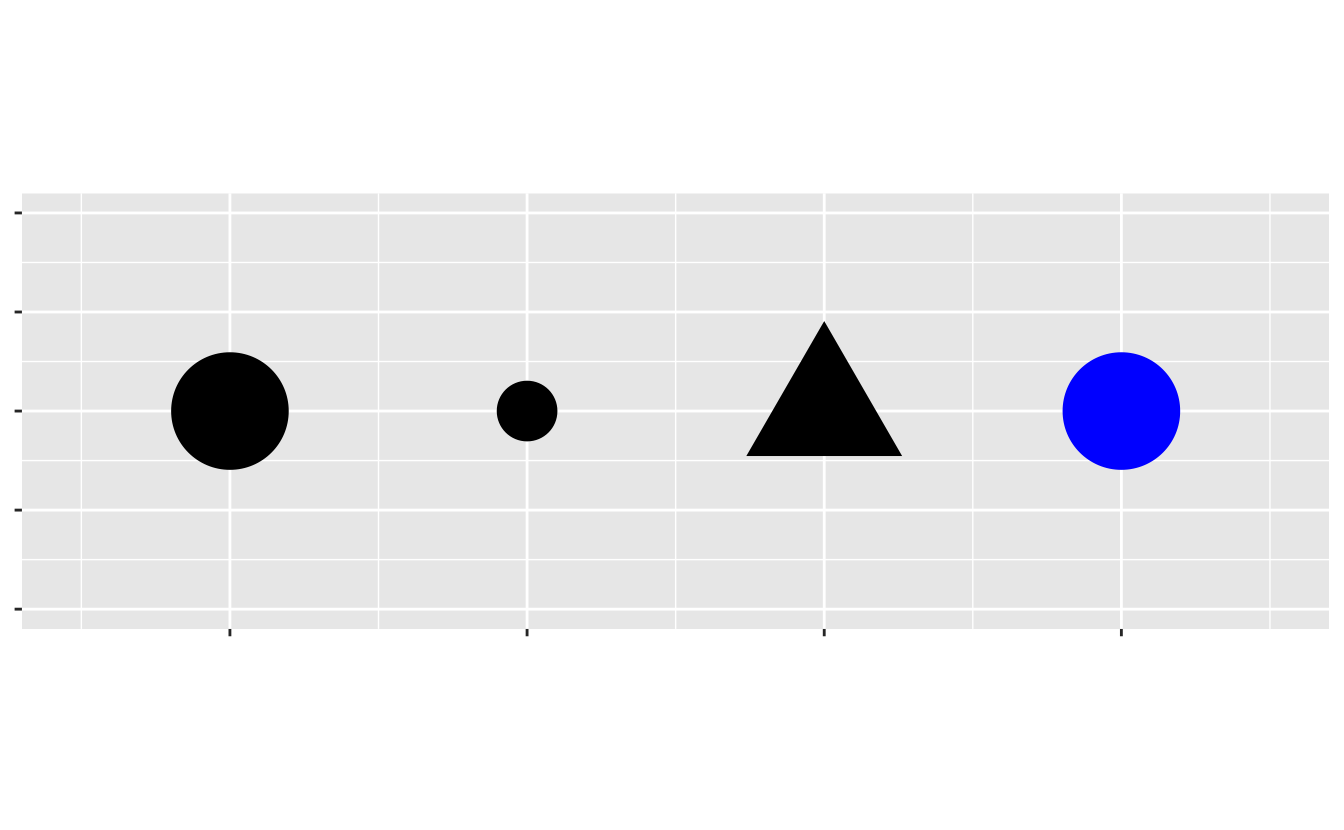
İki boyutlu dağılım grafiğine, bir estetik eşleyerek, class gibi, üçüncü bir değişken ekleyebilirsiniz. Bir estetik, grafiğinizdeki nesnelerin bir görsel özelliğidir. Estetikler noktalarınızın boyut, biçim veya renklerini içerir. Bir noktayı, estetik özelliklerini değiştirerek (aşağıdaki gibi) çeşitli şekillerde gösterebilirsiniz. “Değer” (value) kelimesini veriyi tanımlamak için kullandığımız için, estetik özellikleri tanımlamak için “kademe” (level) kelimesini kullanalım. Burada bir noktayı küçük, üçgen şeklinde veya mavi yapmak için; boyut, biçim ve renk kademelerini değiştiriyoruz:
Grafiğinizdeki estetiği veri setinizdeki değişkenlerle eşleştirerek verilerinizle ilgili bilgileri aktarabilirsiniz. Örneğin, her bir aracın sınıfını ortaya çıkarmak için noktalarınızın renklerini class değişkenine eşleyebilirsiniz.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, color = class))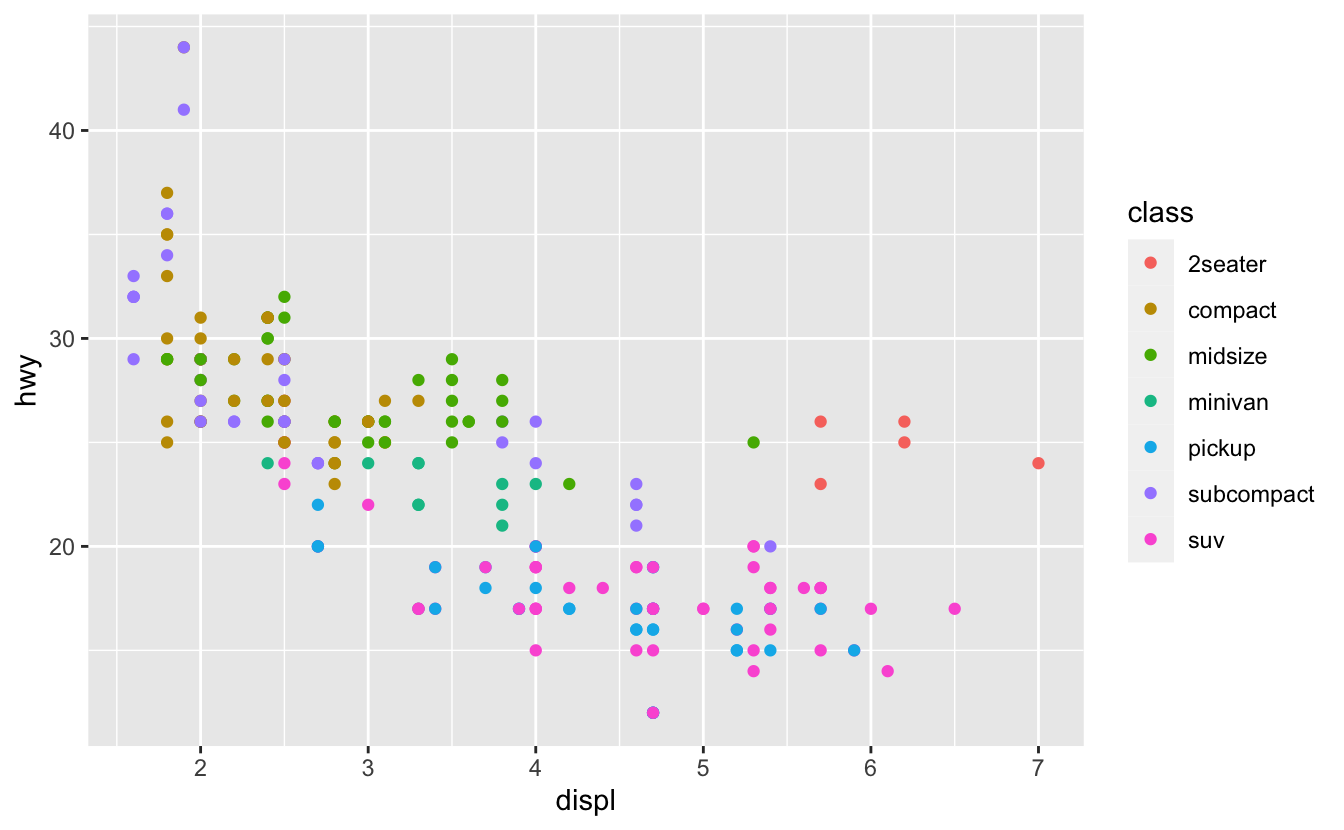
(Eğer siz de Hadley gibi İngiliz İngilizcesi tercih ediyorsanız, color yerine colour kullanabilirsiniz.)
Bir estetiği bir değişkene eşlemek için, aes() içinde estetiğin adını değişkenin adıyla ilişkilendirin. ggplot2 otomatik olarak her özgün değişken değeri için, özgün bir estetik kademesi atayacaktır (burada özgün bir renk), bu işleme ölçeklendirme adı verilir. ggplot2 ayrıca her kademe-değişken eşleşmesini açılayan bir gösterge de ekleyecektir.
Renklere göre, olağandışı olan tüm noktalar iki kişilik arabalardır. Bu arabalar hibrit olmamanın yanı sıra aslında spor arabalar! Spor arabalar, SUVler ve kamyonetler gibi büyük motorlara, ama orta ölçekli ve kompakt arabalar gibi küçük kasalara sahiptir; bu da onların daha fazla mesafe kat edebilmesini sağlar. Aslına bakıldığında, bu arabalar büyük motorlara sahip oldukları için hibrit olmaları pek de olası değildir.
Yukarıdaki örnekte, class değişkenini renk estetiğine eşledik, ama aynı şekilde class değişkenini boyut estetiğine de eşleyebilirdik. Bu durumda, her bir noktanın tam boyutu sınıflandırmasıyla ilişkili olurdu. Burada bir uyarı alıyoruz, çünkü sıralanmamış bir değişkeni (class), sıralanmış bir estetiğe (size) eşlemek iyi bir fikir değil.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, size = class))
#> Warning: Using size for a discrete variable is not advised.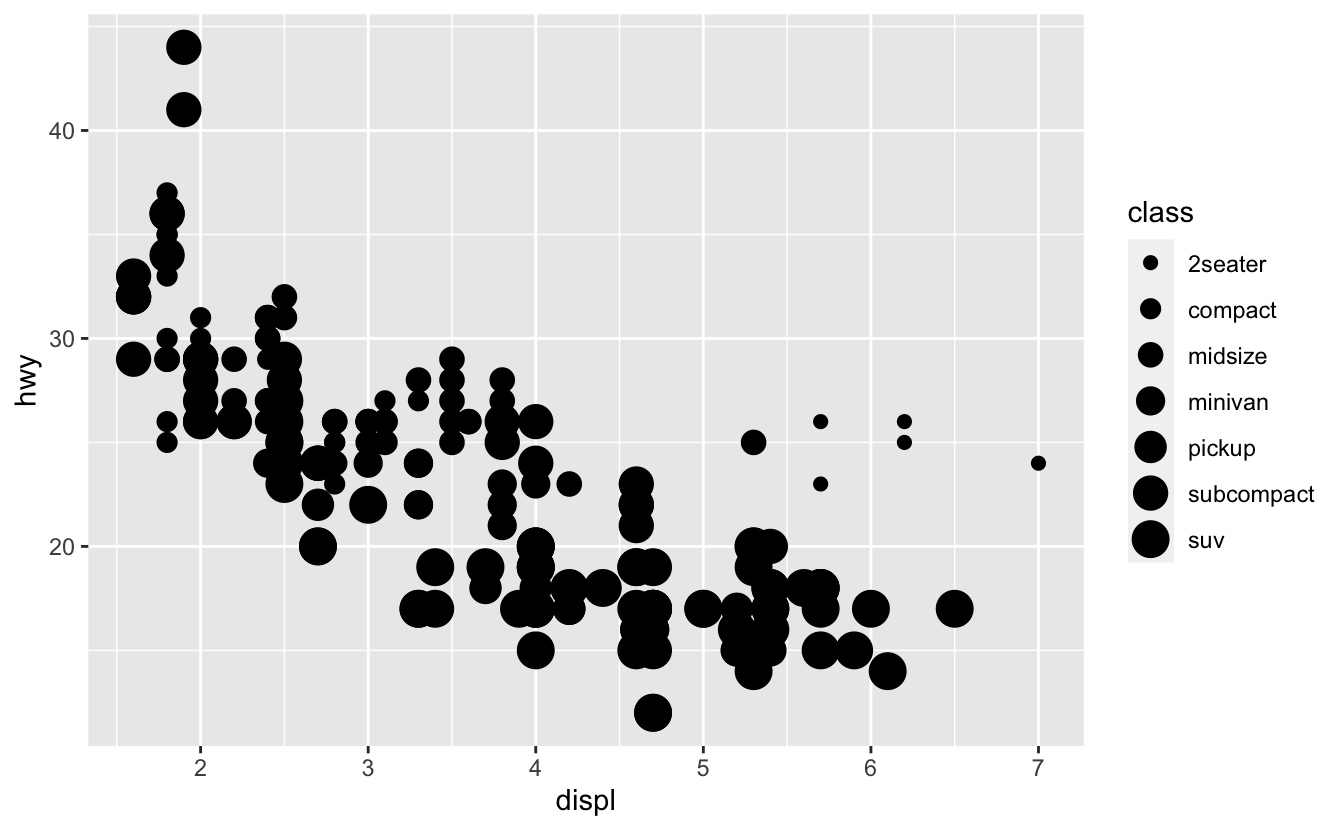
Ya da class değişkenini, noktaların saydamlığını kontrol eden alpha estetiğine veya noktaların biçimini kontrol eden biçim estetiğine eşleyebilirdik.
# Left
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, alpha = class))
# Right
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy, shape = class))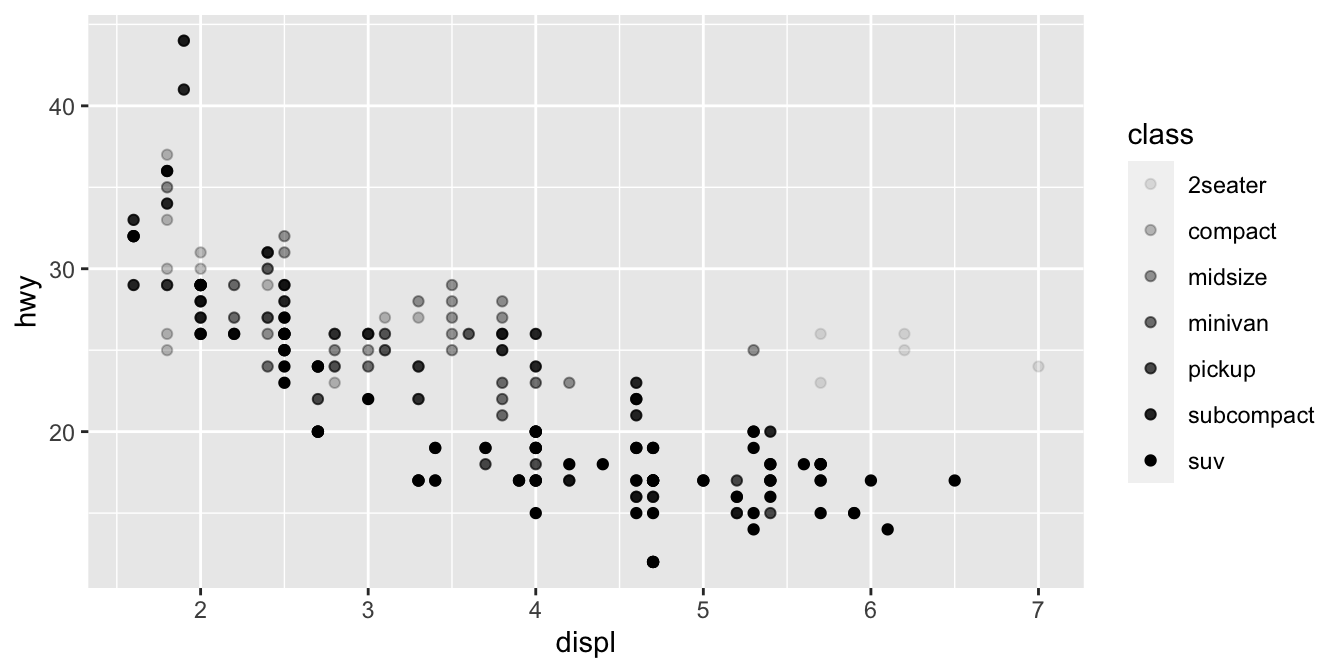
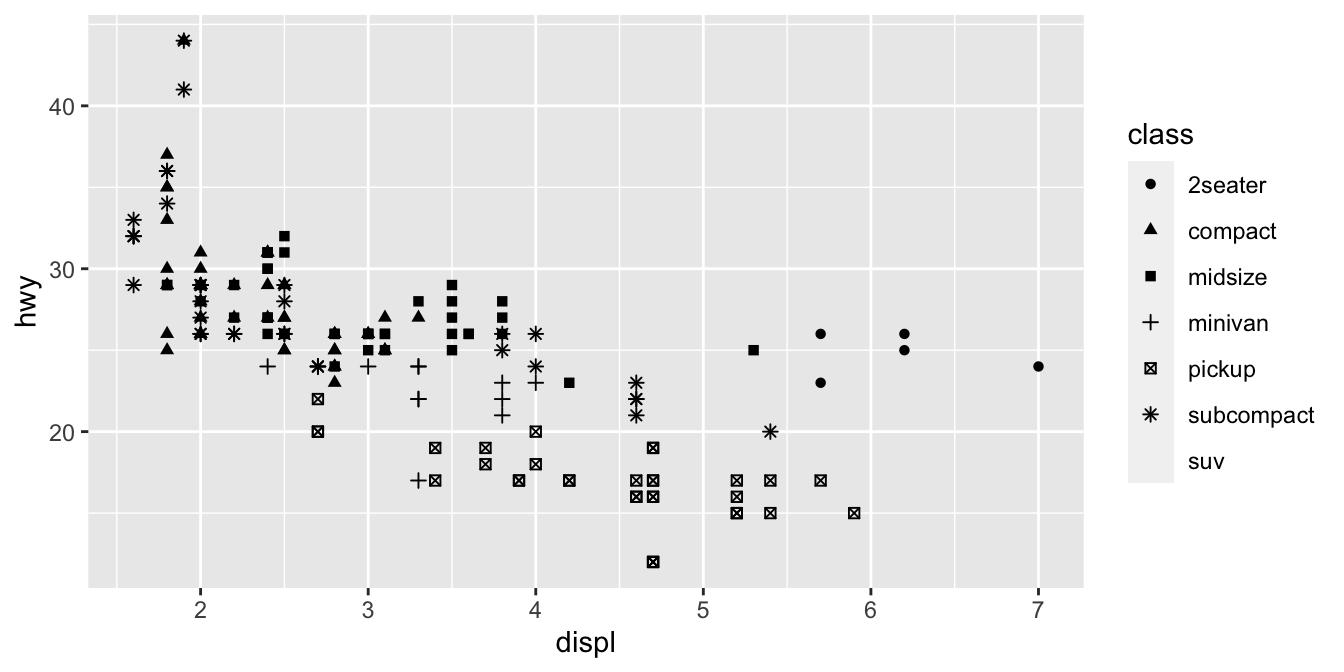
SUVlara ne oldu? ggplot2 aynı anda sadece altı biçim kullanır. Varsayımsal olarak, biçim estetiğini kullandığınzda eklenen gruplar grafikte gözükmeyecektir.
Her estetiği görselleştirebilmek için, estetiğin adıyla değişkenin adını aes() kullanarak ilişkilendirmeniz gerekir. aes() fonksiyonu her estetik eşleme katmanını bir araya toplayarak onu eşleme argümanından geçirir. Sözdizimi, x ve y hakkında faydalı bir anlama dikkat çeker: bir noktanın x ve y konumlarının kendileri estetiklerdir, verilerle ilgili bilgileri görüntülemek için değişkenlerle eşleştirebileceğiniz görsel özelliklerdir.
Bir estetiği eşleştirdiğinizde, ggplot2 gerisini halleder. Estetikle kullanmak için makul bir ölçek seçer ve kademeler ve değerler arasındaki eşlemeyi açıklayan bir gösterge oluşturur. x ve y estetikleri için, ggplot2 bir gösterge oluşturmaz, ancak ölçüm çentikli ve etiketli bir eksen çizgisi oluşturur. Eksen çizgisi bir gösterge olarak hareket eder; konumlar ve değerler arasındaki eşlemeyi açıklar.
Ayrıca geom estetik özelliklerini manuel olarak da ayarlayabilirsiniz. Örneğin, grafiğimizdeki tüm noktaları mavi yapabiliriz:
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy), color = "blue")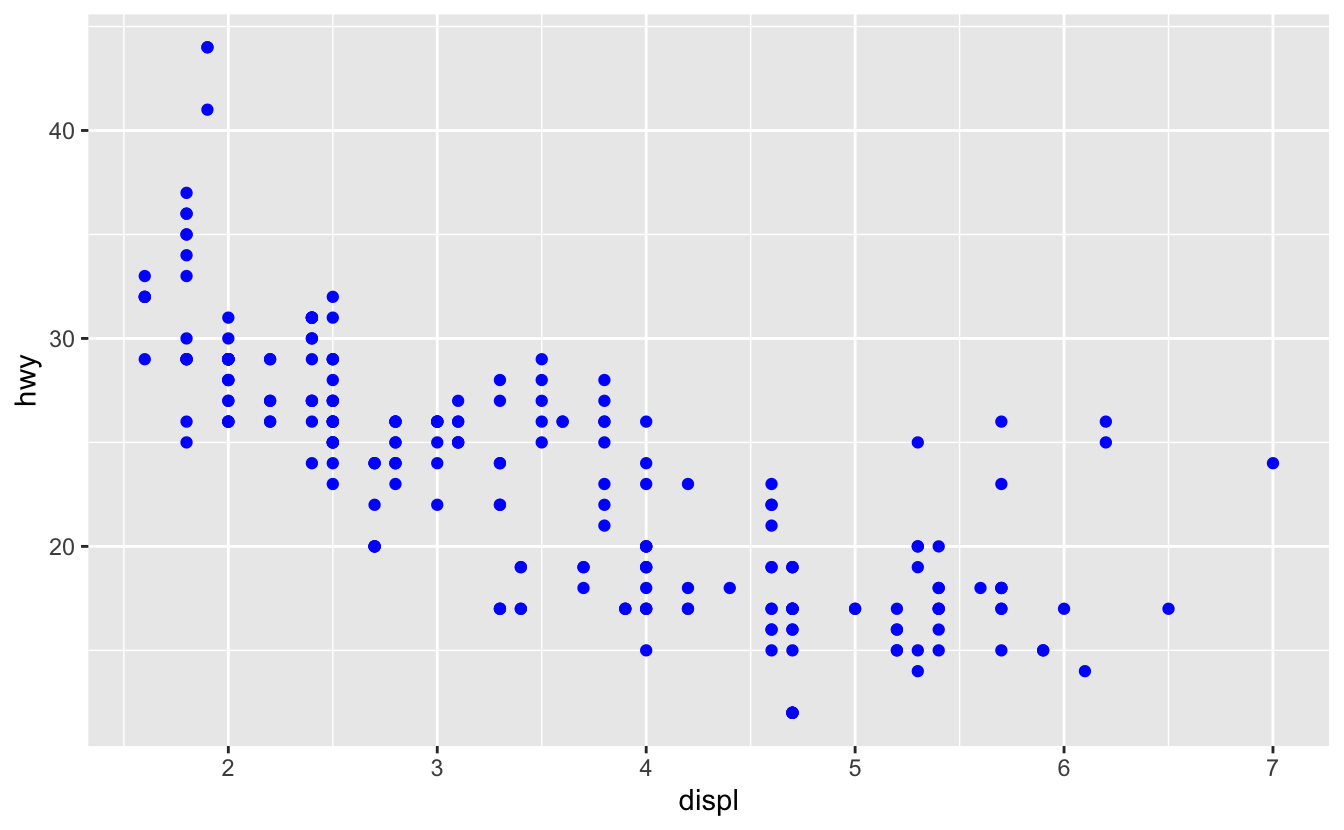
Burada, renk değişken hakkında bilgi taşımaz, yalnızca grafiğin görünümünü değiştirir. Bir estetiği manuel olarak ayarlamak için, estetiği adına göre geom fonksiyonunun bir argümanı olarak ayarlayın; yani aes()’in dışında olmalı. Bu estetik için mantıklı bir kademe seçmeniz gerekir:
- Bir rengin karakter dizisi olarak adı.
- Bir noktanın mm cinsinden boyutu.
- Bir noktanın, Şekil 3.1 ’de gösterildiği gibi sayı şeklinde biçimi.
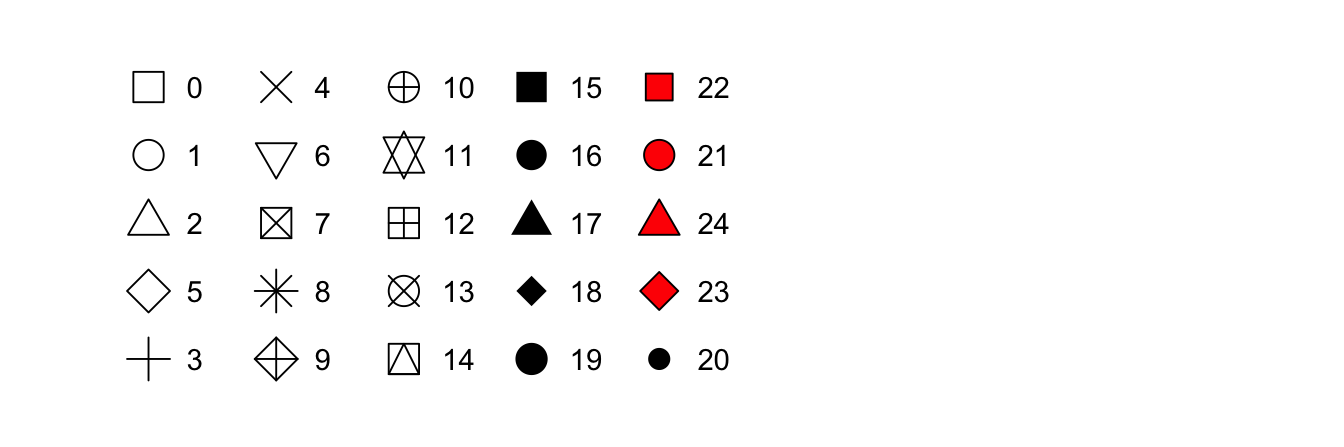
Figure 3.1: R, sayılarla tanımlanan 25 yerleşik şekle sahiptir. Görünüşe göre bazı kopyalar var: örneğin, 0, 15 ve 22’ler kare. Fark, renk ve dolgu estetiklerinin etkileşiminden kaynaklanmaktadır. İçi boş şekiller (0–14) renk tarafından belirlenen bir sınıra sahiptir; düz şekiller ise (15-18) renk ile doldurulur; doldurulmuş şekillerin ise (21-24) bir renk sınırı vardır ve dolgu ile doldurulur.
3.3.1 Alıştırmalar
Bu kodda yanlış olan nedir? Noktalar neden mavi değil?
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy, color = "blue"))
mpg’deki hangi değişkenler kategoriktir? Hangileri süreklidir? (İpucu: veri setinin dökümentasyonunu okumak için?mpgyazın.) Bu bilgiyimpg’yi çalıştırdığınızda nasıl görebilirsiniz?Bir sürekli değişkeni
renk(color),boyut(size) vebiçim(shape) ile eşleyin. Bu estetikler sürekli ve kategorik değişkenlere göre nasıl değişiyorlar?Aynı değişkeni, birden fazla estetikle eşlerseniz ne olur?
strokeestetiği ne işe yarar? Hangi biçimlerle beraber çalışır? (İpucu:?geom_pointkullanın.)Eğer bir estetiği
aes(colour = displ < 5)gibi değişken adı dışında bir şeylere eşlerseniz ne olur? Dikkat, x ve y’yi de belirtmeniz gerekiyor.
3.4 Sıkça rastlanan problemler
R kodunu çalıştırmaya başladığınızda, sorunlarla karşılaşmanız olasıdır. Endişelenmeyin — bu herkesin başına geliyor. Yıllardır R kodu yazıyorum ve her gün hala çalışmayan bir kod yazıyorum!
Çalıştırdığınız kodu, kitaptaki kodla dikkatlice karşılaştırarak başlayın. R son derece seçicidir ve yanlış yerleştirilmiş bir karakter tümüyle farklı sonuçlar doğurabilir. Her ( ile ) ve her " bir başka " ile eşleştirilmiş olduğundan emin olun. Bazen kodu çalıştırırsınız ve hiçbir şey olmaz. Konsolunuzun sol tarafını kontrol edin: eğer bir + ise, R tamamlanmış bir ifade yazdığınızı düşünmüyordur ve bitirmenizi bekler. Bu durumda, mevcut komutu işlemekten vazgeçmek için ESCAPE düğmesine basarak yeniden sıfırdan başlamak genellikle kolaydır.
ggplot2 grafikleri oluştururken sık karşılaşılan bir sorun, + yı yanlış yere koymaktır: satırın başına değil, sonuna gelmelidir. Başka bir deyişle, yanlışlıkla aşağıdaki gibi bir kod yazmadığınızdan emin olun:
ggplot(data = mpg)
+ geom_point(mapping = aes(x = displ, y = hwy))Hala takılıyorsanız yardım sayfasını deneyin. Konsolda ?fonksiyon_adı komutunu çalıştırarak veya fonksiyon adını seçip RStudio’da F1 tuşuna basarak herhangi bir R fonksiyonu hakkında yardım alabilirsiniz. Yardım bölümü size o kadar da yardımcı olmuyorsa endişelenmeyin - bunun yerine sayfa sonundaki örneklere atlayın ve yapmaya çalıştığınız kodla eşleşen kodu arayın.
Bu da işe yaramazsa, hata mesajını dikkatlice okuyun. Bazen cevap orada saklıdır! R’da yeniyseniz, cevap hata mesajında gizli olsa da hata mesajını anlamlandırmayı bilmiyor olabilirsiniz. Bir diğer harika araç ise Google: hata mesajını Google’da aratmayı deneyin, çünkü başka birinin de aynı sorunu yaşamış ve çevrimiçi yardım almış olması çok yüksek ihtimaldir.
3.5 Ayırmalar
Estetikler, ek değişkenler eklemenin bir yoludur. Özellikle kategorik değişkenler için yararlı bir başka yol ise grafiğinizi her birini, bir veri alt kümesini gösterecek şekilde ayırma eklemektir.
Grafiğinizi tek bir değişken ile ayırmak için facet_wrap() kullanın. facet_wrap()’in ilk argümanı ~ ile yarattığınız ve ardından bir değişken adıyla oluşturduğunuz bir formül olmalıdır (burada “formül”, “denklem” ile eş anlamlı değil, R’daki bir veri yapısının adıdır). facet_wrap() öğesine ilettiğiniz değişken ayrık olmalıdır.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_wrap(~ class, nrow = 2)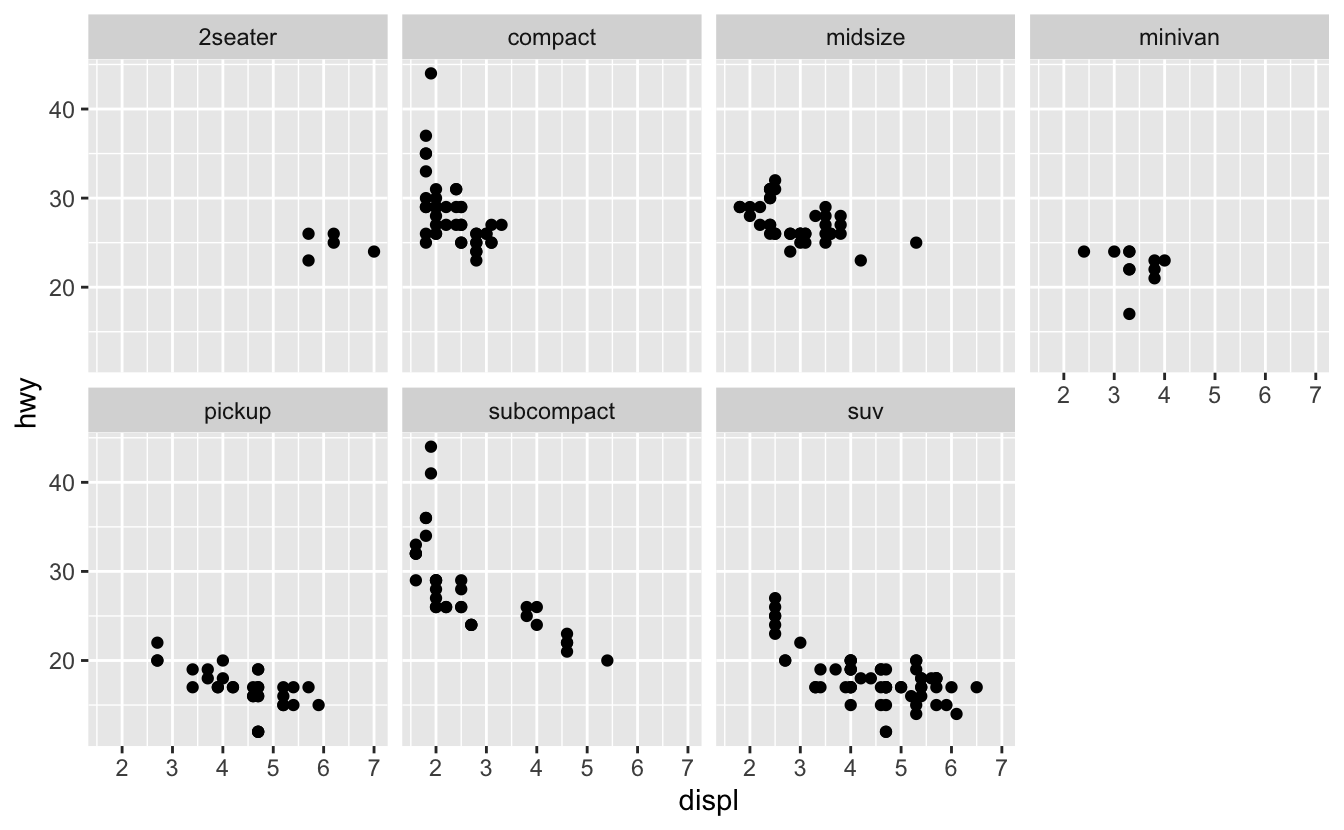
Grafiğinizi iki değişkenin birleşimi ile karşılaştırmak için, grafik komutunuza facet_grid() ekleyin. facet_grid()’in ilk argümanı da bir formüldür. Bu sefer formülde ~ ile ayrılan iki değişken ismi bulunmalıdır.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
facet_grid(drv ~ cyl)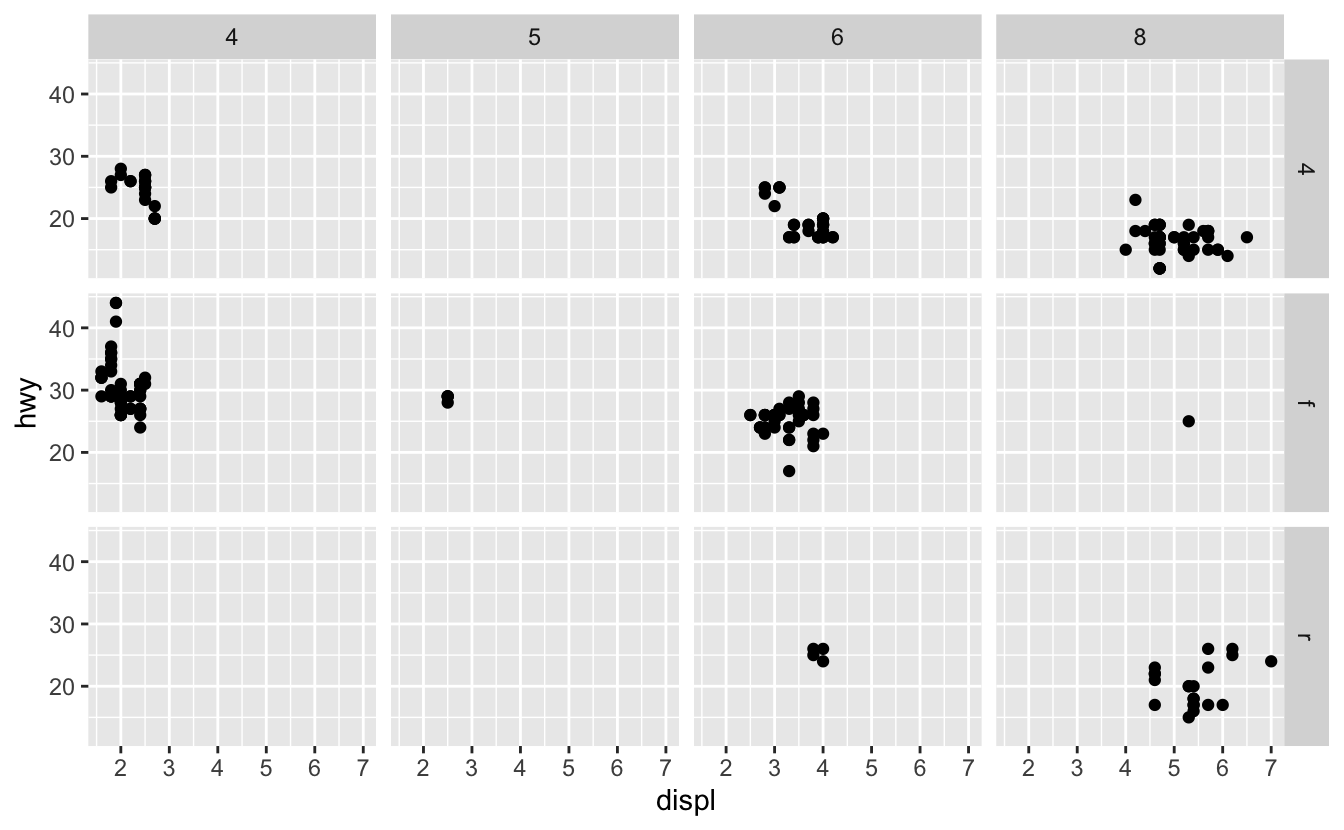
Satırlar veya sütunlara göre ayırmayı tercih etmezseniz, değişken adı yerine bir . kullanın; örneğin,+ facet_grid(. ~ cyl).
3.5.1 Alıştırmalar
Sürekli bir değişkeni ayırırsanız ne olur?
facet_grid(drv ~ cyl)ile grafikleştirdiğinizde, grafikte görünen boş hücreler ne anlama gelir? Bu grafik ile nasıl ilişkilendirilebilirler?ggplot(data = mpg) + geom_point(mapping = aes(x = drv, y = cyl))Aşağıdaki kod nasıl grafikler yapar?
.ne işe yarar?ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy)) + facet_grid(drv ~ .) ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy)) + facet_grid(. ~ cyl)Bu bölmedeki ilk ayrılmış grafiği alın:
ggplot(data = mpg) + geom_point(mapping = aes(x = displ, y = hwy)) + facet_wrap(~ class, nrow = 2)
Renk estetiği yerine ayırma kullanmanın avantajları nelerdir? Dezavantajları nelerdir? Daha büyük veri setiniz olsaydı bu denge nasıl değişebilirdi?
?facet_wrapsayfasını okuyun.nrowne işe yarar?ncolne işe yarar? Tekil panellerin düzenini kontrol eden başka hangi seçenekler var?facet_grid()’in nedennrowvencolargümanları yok?facet_grid()kullanırken, genellikle daha falza özgün kademesi olan değişkeni sütunlara koymalısınız. Neden?
3.6 Geometrik objeler
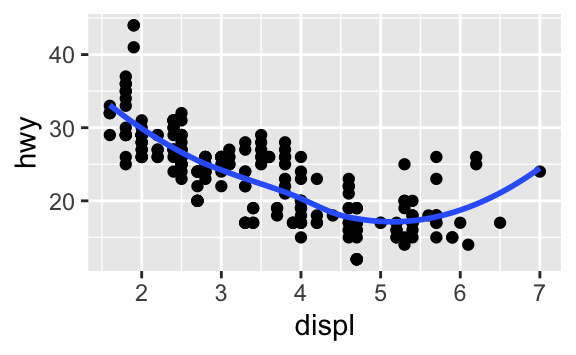
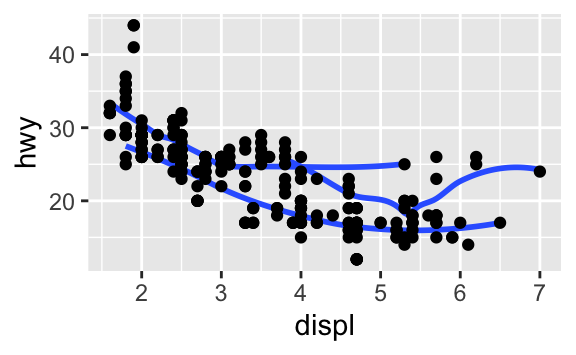
Bu iki grafik nasıl benzer olabilir?
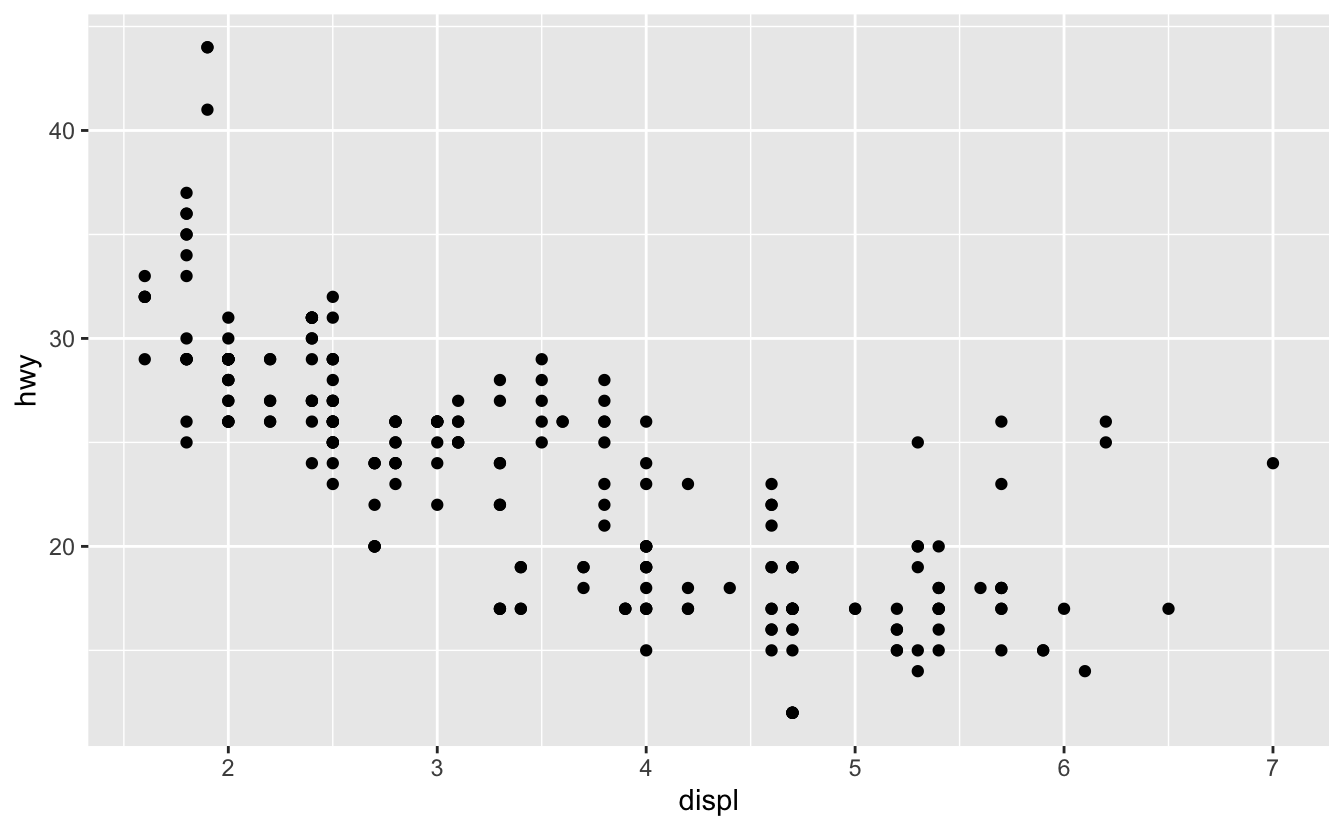
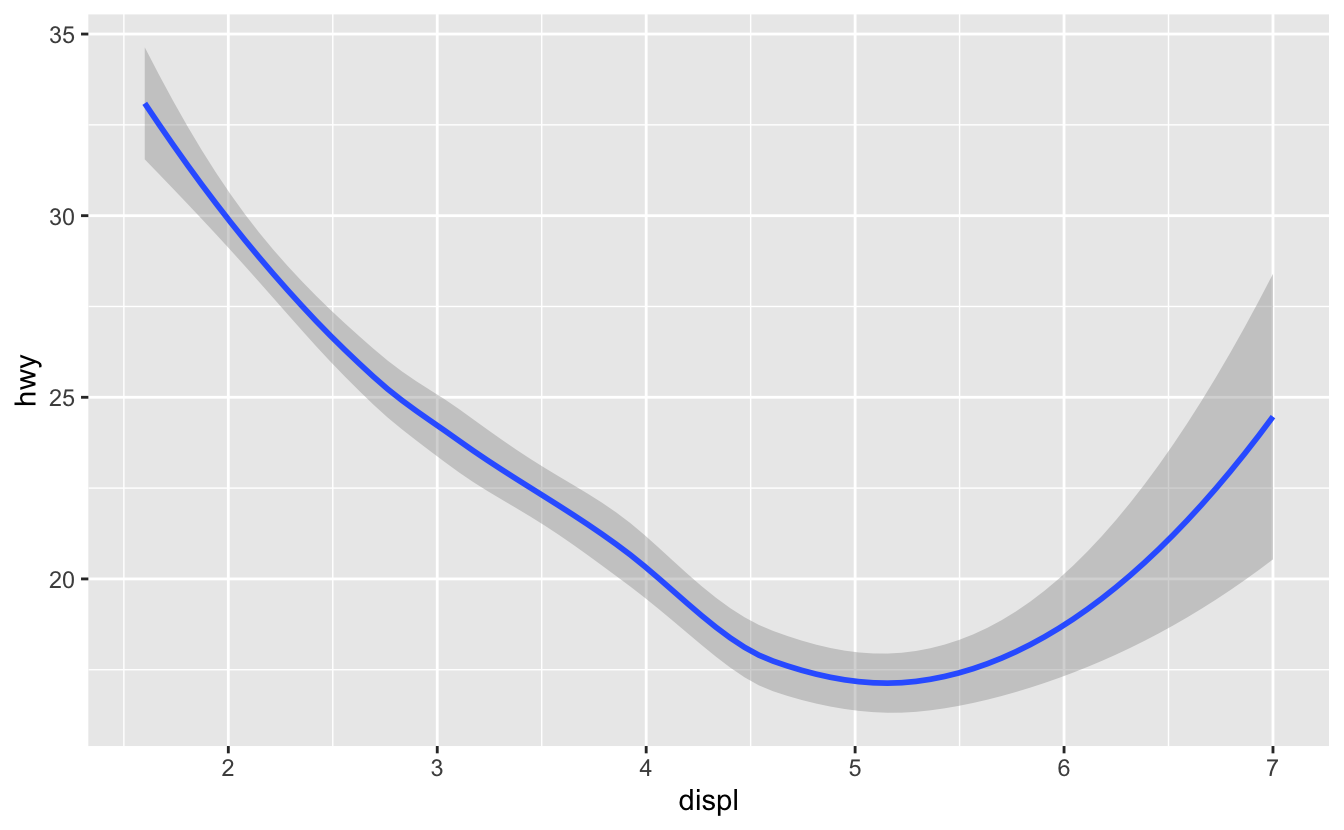
İki grafik de aynı x ve y değişkenlerine sahip, her ikisi de aynı veriyi tanımlıyor. Ama grafikler birebir aynı değil. Her grafik, veriyi temsil eden farklı bir görsel obje kullanıyor. ggplot2 sözdizimine göre farklı geomlar kullanıyorlar deriz.
Bir geom, bir grafiğin veriyi temsil etmesi için kullandığı geometrik bir objedir. İnsanlar genelde grafiklerini kullanılan geoma göre tarif ederler. Örneğin, sütun grafikleri için sütun geomları, çizgi grafikleri için çizgi geomları, kutu grafikleri için kutu geomları vs. kullanılır. Dağılım grafikleri burada istisnadır; nokta geomunu kullanırlar. Yukarıda gördüğümüz gibi, aynı veriyi farklı geomlar kullanarak grafiğe dökebilirsiniz. Soldaki grafik nokta geomunu, sağdaki grafik verinin uyduğu düz bir çizgi oluşturan düz geomunu kullanır.
Grafiğinizdeki geomu değiştirmek için, ggplot()’a eklediğiniz geom fonksiyonunu değiştirin. Mesela, yukarıdaki gibi grafikler yapmak için bu kodu kullanabilirsiniz:
# left
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy))
# right
ggplot(data = mpg) +
geom_smooth(mapping = aes(x = displ, y = hwy))ggplot2’deki her geom fonksiyonu bir mapping argümanı alır. Ancak, her estetik her geom ile çalışmaz. Bir noktanın biçimini ayarlayabilirsiniz, ama bir çizginin biçimini ayarlayamazsınız. Öte yandan, bir çizginin çizgi türünü ayarlayabilirsiniz. geom_smooth() çizgi türü ile eşlediğiniz değişkenin her özgün değeri için, farklı bir çizgi türü ile farklı bir çizgi çizecektir.
ggplot(data = mpg) +
geom_smooth(mapping = aes(x = displ, y = hwy, linetype = drv))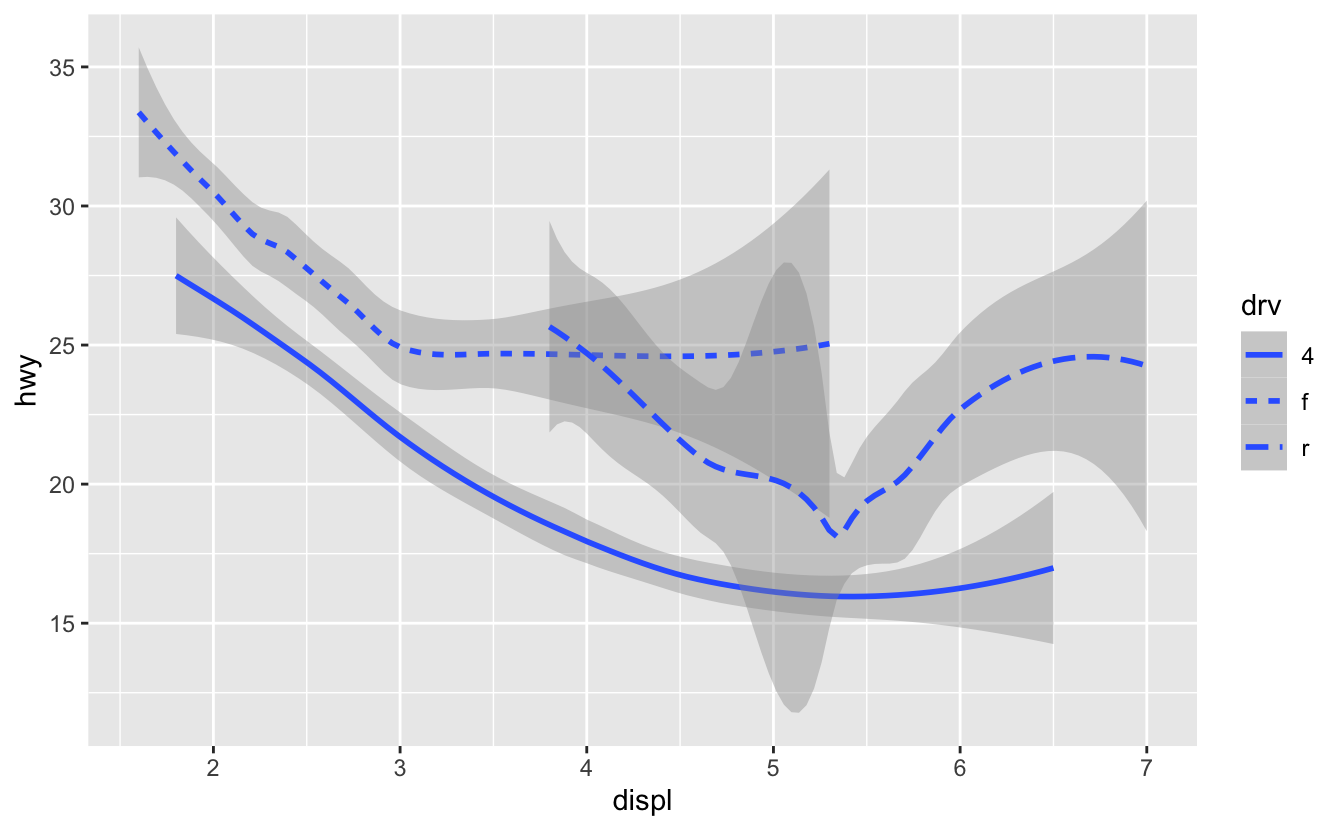
geom_smooth() burada arabaları, güç aktarımlarını anlatan drv değerlerine göre üç çizgiye ayırır. Bir çizgi 4 değerine sahip tüm noktaları, bir çizgi f değerine sahip tüm noktaları ve diğer bir çizgi de r değerine sahip tüm noktaları tanımlar. 4 burada dört çekerli, f önden çekerli ve r arkadan çekerli arabaları tanımlar.
Eğer bu size garip geliyorsa, çizgileri ham veri ile üst üste koyup, drv değerine göre renklendirdiğimizde daha açıklayıcı hale getirebiliriz.
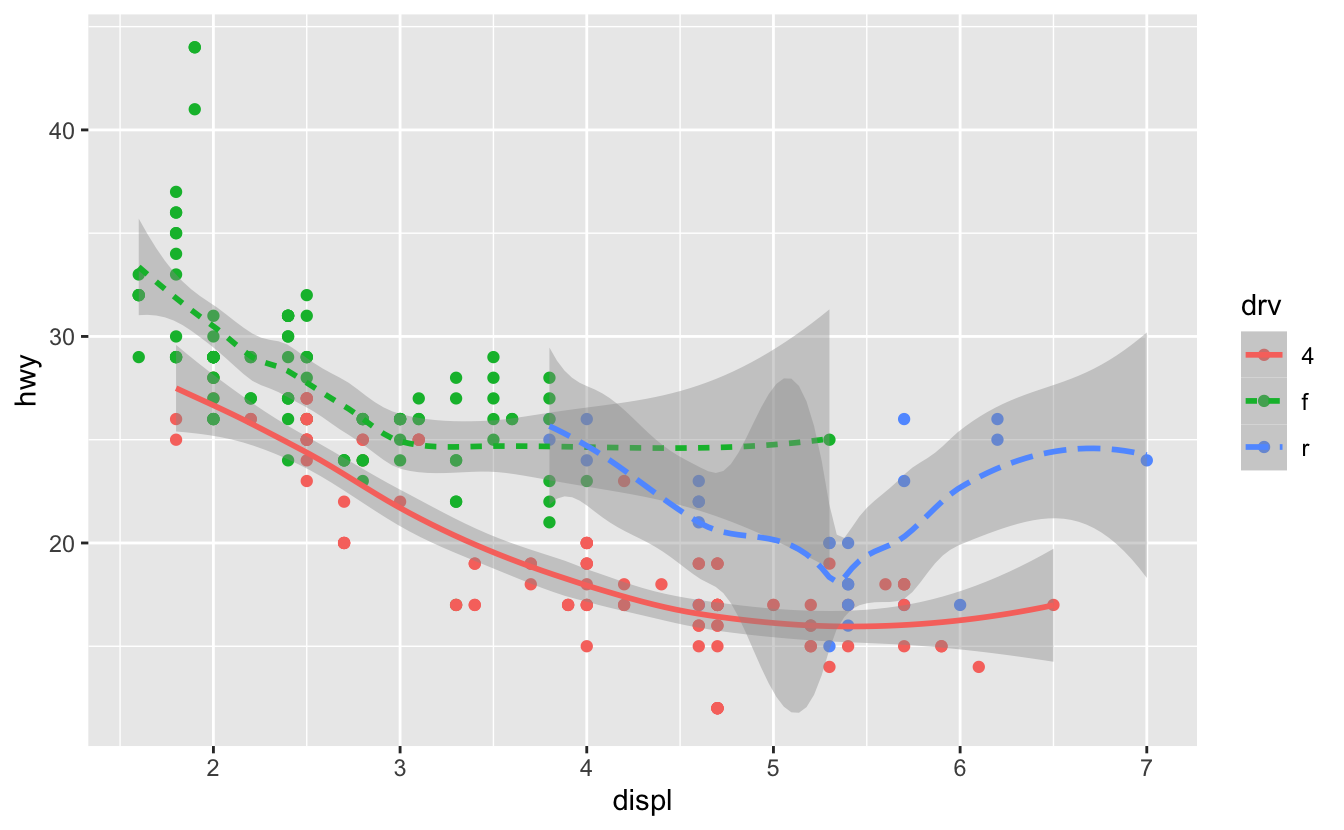
Bu grafiğin, aynı anda iki farklı geom içerdiğine dikkat edin! Eğer bu sizi heyecanlandırıyorsa, kemerlerinizi bağlayın. Çok yakında aynı grafiğe birden fazla geomu nasıl yerleştireceğimizi öğreneceğiz.
ggplot2 30’dan fazla geom temin eder, hatta ek paketleriyle daha da fazla (örnekler için bkz. https://www.ggplot2-exts.org). Kapsamlı şekilde göz atmak için ggplot2 ipuçlarına bakın, http://rstudio.com/cheatsheets adresinden ulaşabilirsiniz. Bir geom hakkında daha fazla bilgiye ulaşmak için yardım sayfalarını kullanın: ?geom_smooth.
geom_smooth() gibi birçok geom, birden fazla veri satırını görüntülemek için bir adet geometrik obje kullanır. Bu geomlar için, bir kategorik değişkene, birden fazla objeyi çizmesi için grup estetiği belirleyebilirsiniz. Uygulamada, ne zaman bir estetiği bir ayrık değişken ile eşlerseniz (linetype örneğinde olduğu gibi) ggplot2 otomatik olarak veriyi bu geomlara göre gruplayacaktır. Bu özelliğe güvenmek gayet elverişlidir; çünkü grup estetiği kendi başına bir gösterge ya da geomları ayırt edici özellikler eklemez.
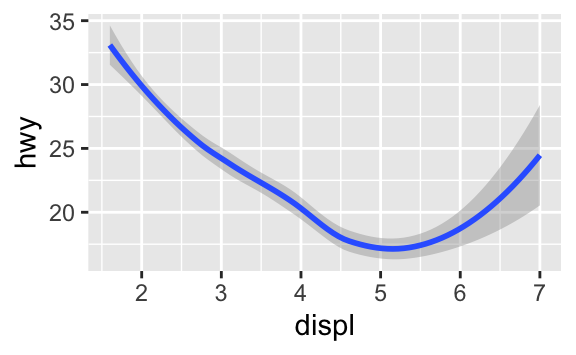
ggplot(data = mpg) +
geom_smooth(mapping = aes(x = displ, y = hwy))
ggplot(data = mpg) +
geom_smooth(mapping = aes(x = displ, y = hwy, group = drv))
ggplot(data = mpg) +
geom_smooth(
mapping = aes(x = displ, y = hwy, color = drv),
show.legend = FALSE
)
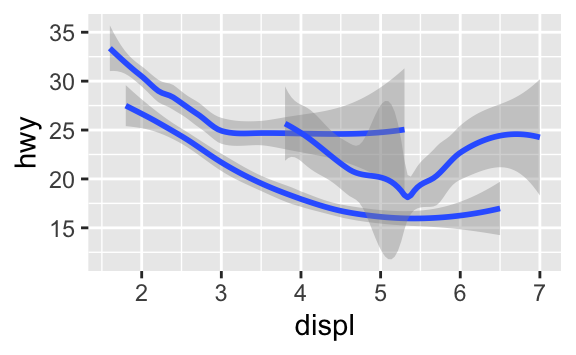
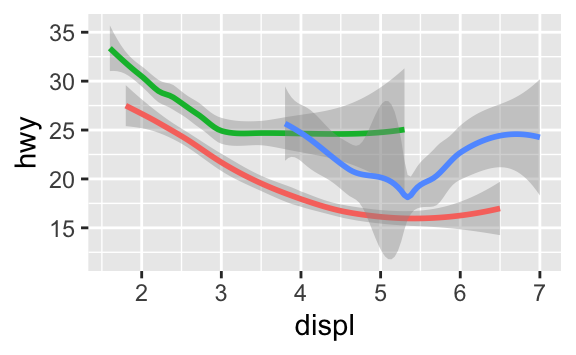
Birden fazla geomu aynı grafik üzerinde göstermek için ggplot()’a birden fazla geom fonksiyonu ekleyin:
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy)) +
geom_smooth(mapping = aes(x = displ, y = hwy))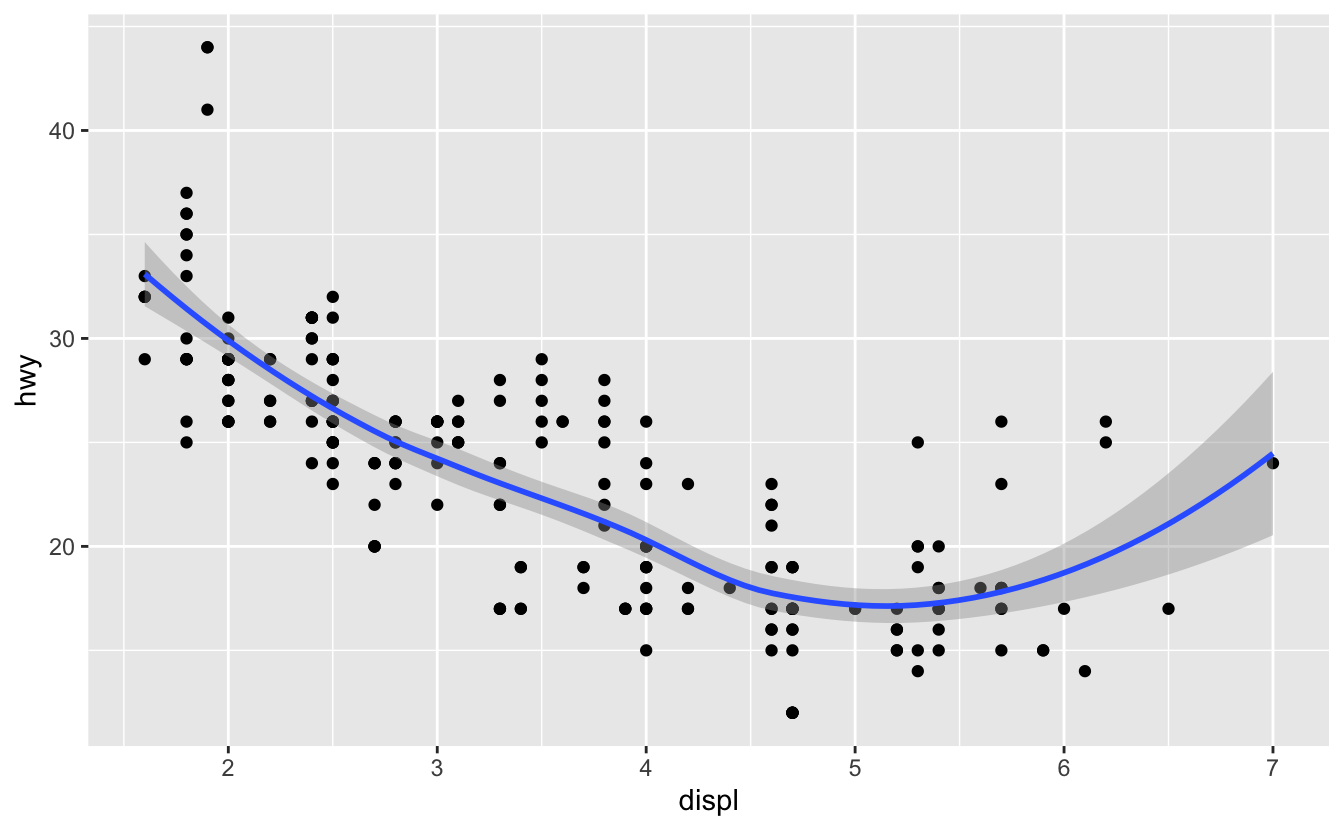
Ancak bu kodunuzda tekrarlamaya sebep olur. y eksenini hwy yerine cty değerini gösterecek şekilde değiştirmek istediğinizi düşünün. Bu değişkeni iki yerde değiştirmeniz gerekir ve bir tanesini güncellemeyi unutabilirsiniz. Bu tarz tekrarları ggplot()’a bir eşleme seti atayarak önleyebilirsiniz. ggplot2 bu eşlemelere, grafikteki her geoma uygulacak şekilde, global eşlemeler gibi davranacaktır. Başka bir deyişle, bu kod, bir önceki kod ile aynı grafiği üretecektir:
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point() +
geom_smooth()Eşlemeleri bir geom fonksiyonunun içine koyarsanız, ggplot2 buna, o katmanın yerel eşlemesi olarak davranacaktır. Bu eşlemeleri sadece o katman için, global eşlemelerini genişletmek ya da üzerine yazmak için kullanacaktır. Böylece farklı katmanlarda farklı estetik gösterimleri yapabilirsiniz.
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point(mapping = aes(color = class)) +
geom_smooth()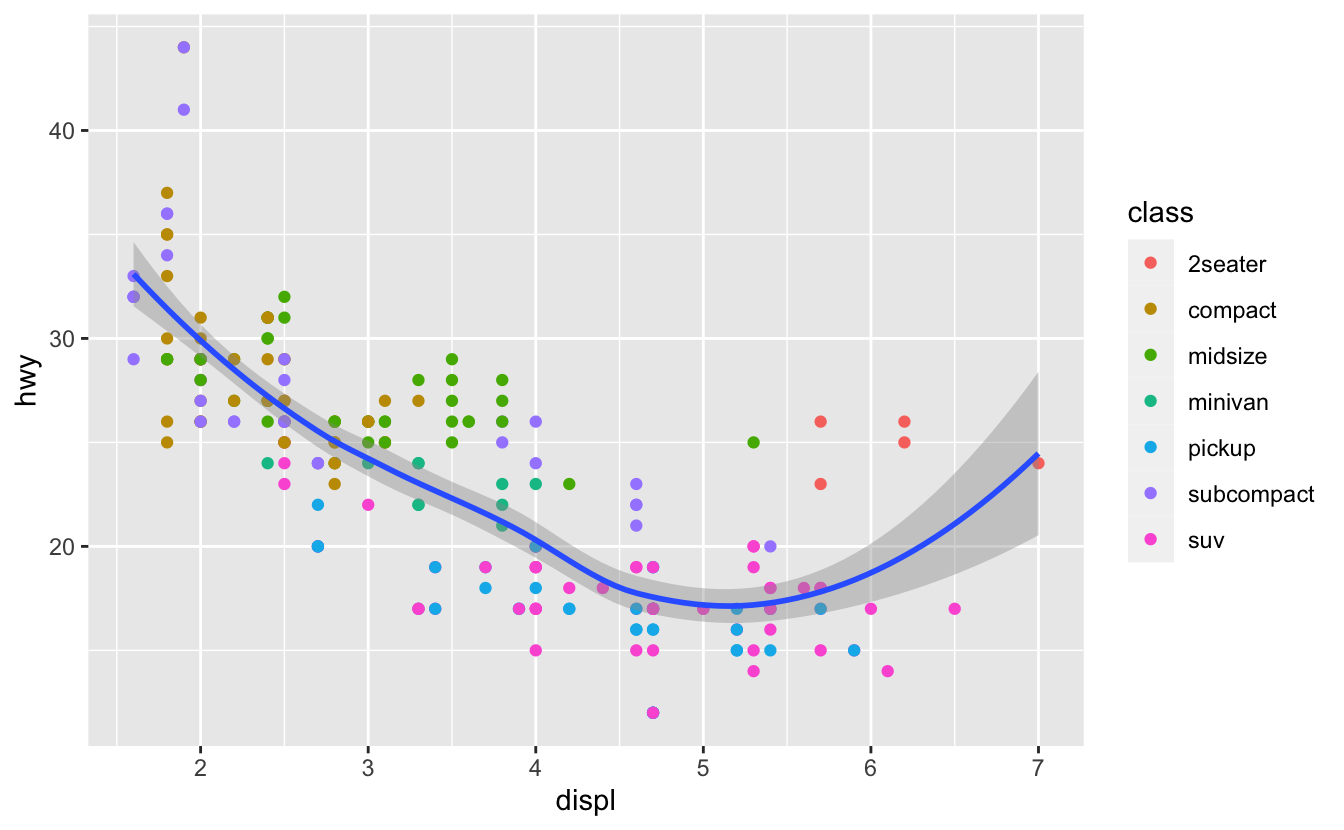
Aynı yöntemi, her katmanda farklı data belirtmek için de kullanabilirsiniz. Burada, düz çizgimiz sadece mpg veri setinin bir alt kümesi olan yarı-kompakt arabaları gösteriyor. Sadece bu katman için, geom_smooth()’taki yerel veri argümanı, ggplot()’un global veri argümanının geçersiz kılıyor.
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) +
geom_point(mapping = aes(color = class)) +
geom_smooth(data = filter(mpg, class == "subcompact"), se = FALSE)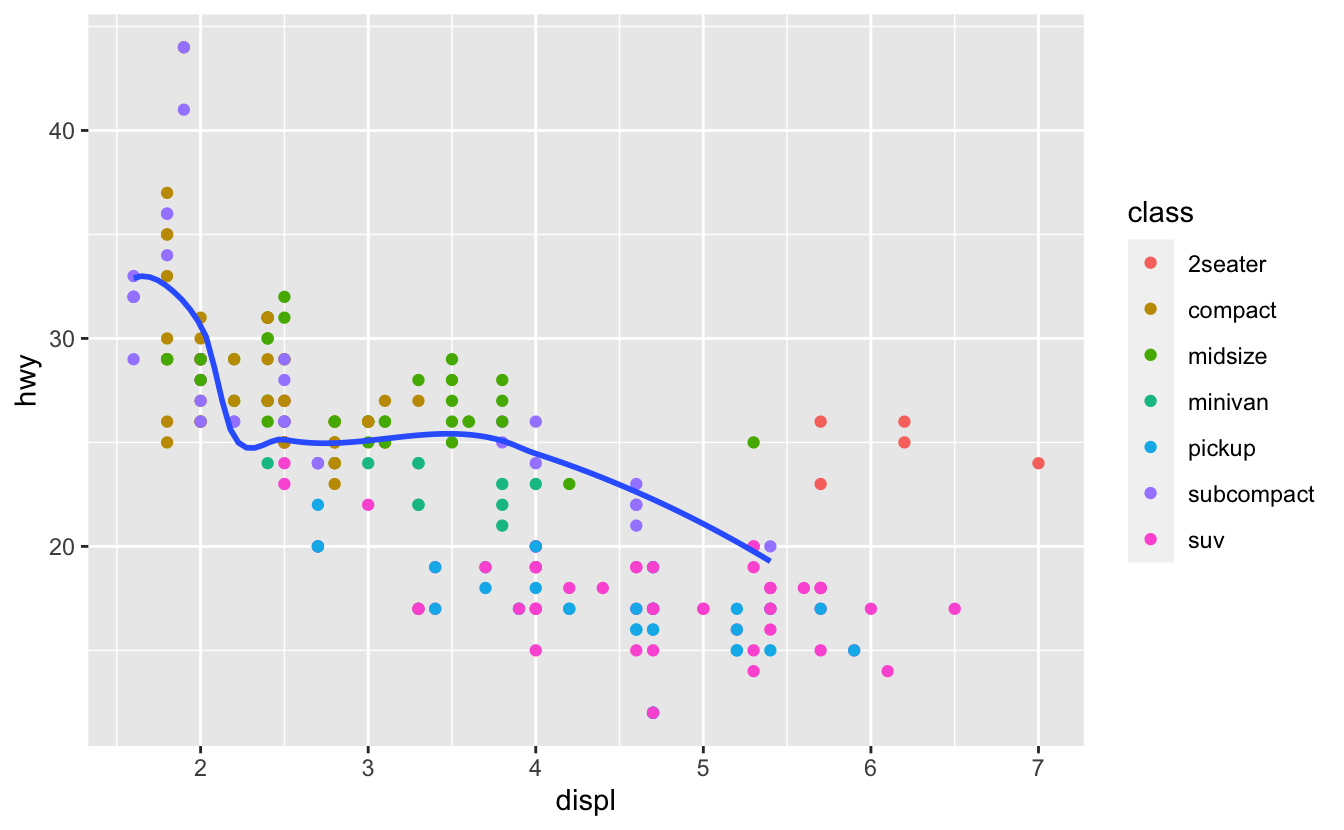
(Veri dönüşümleri üzerine olan bölümde filter() fonksiyonunun nasıl çalıştığını öğreneceksiniz: Şimdilik sadece bu komutun yarı-kompakt arabaları seçtiğini bilin.)
3.6.1 Alıştırmalar
Çizgi grafiği çizmek için hangi geom kullanılır? Kutu grafiği için? Histogram? Alan grafiği?
Bu kodu zihninizde çalıştırın ve çıktısının nasıl görüneceğini tahmin etmeye çalışın. Sonra, kodu R’da çalıştırın ve tahmininizi kontrol edin.
ggplot(data = mpg, mapping = aes(x = displ, y = hwy, color = drv)) + geom_point() + geom_smooth(se = FALSE)show.legend = FALSEne işe yarar? Kaldırınca ne olur? Sizce neden daha önce bu bölümde bunu kullandım?seargümanıgeom_smooth()fonksiyonuna ne yaptırır?Bu iki grafik farklı görünecek mi? Neden?
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) + geom_point() + geom_smooth() ggplot() + geom_point(data = mpg, mapping = aes(x = displ, y = hwy)) + geom_smooth(data = mpg, mapping = aes(x = displ, y = hwy))Aşağıdaki grafiği oluşturacak olan gerekli R kodunu yazın.
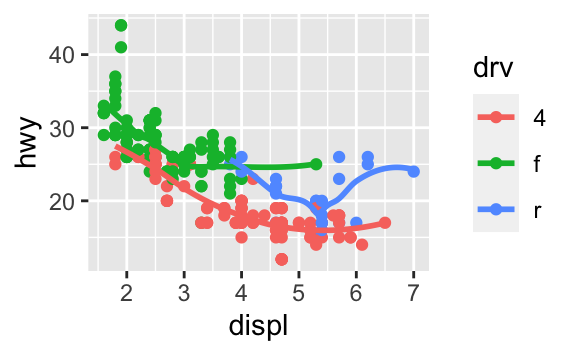
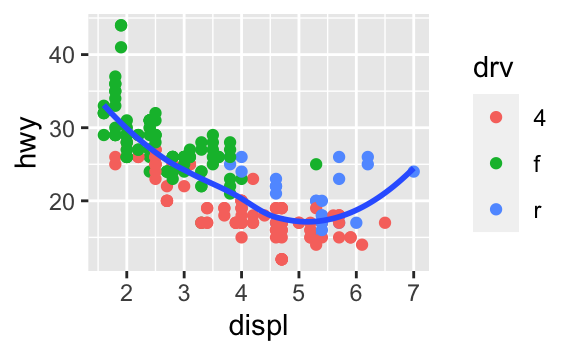
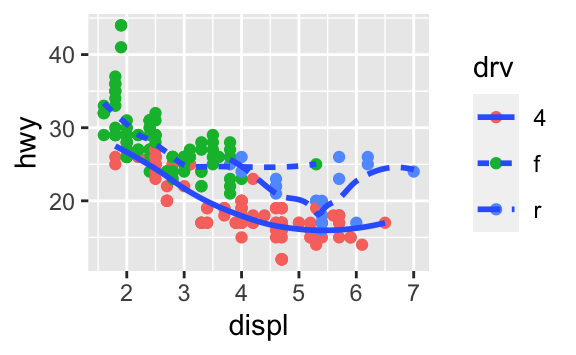
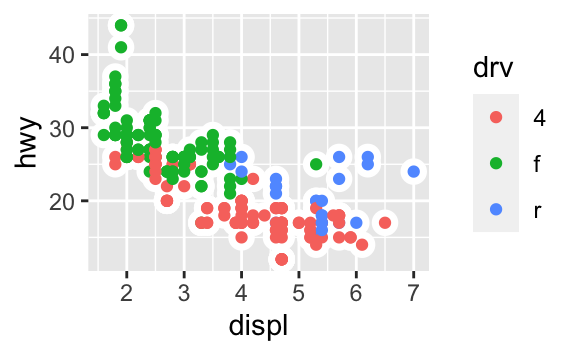
3.7 İstatistiksel dönüşümler
Şimdi bir sütun grafiğine bakalım. Sütun grafikleri kolay görünebilir, ama aslında ilginçtirler; çünkü grafikler hakkında göze çarpmayan şeyleri ortaya çıkarırlar. geom_bar() ile çizilmiş, basit bir sütun grafiği ele alalım. Aşağıdaki grafik diamonds veri seti içinde, cut değişkenine göre gruplandırılmış olarak toplam elmas sayısını gösteriyor. diamonds veri seti ggplot2 ile beraber gelir ve ~54,000 elmas hakkında price, color, clarity ve cut değişkenleri hakkında bilgi içerir. Grafiğe göre yüksek kalite kesimli elmasların sayısı, düşük kalite kesimli elmasların sayısından fazladır.
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut))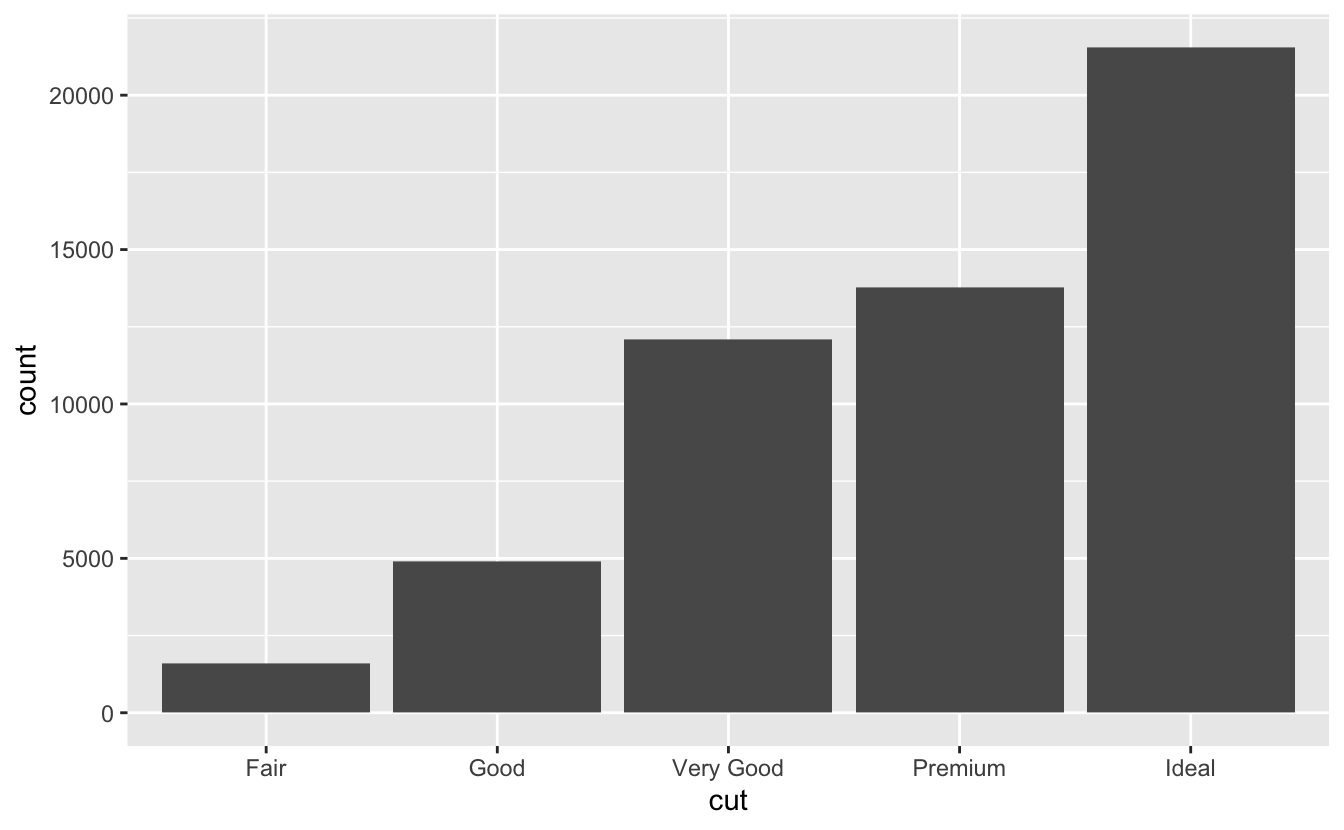
x ekseninde, grafik diamonds veri setinden cut değişkenini gösterir. y ekseninde ise sayıyı gösterir, ancak sayı diamonds veri setinin içinde bir değişken değil! Sayı nereden geldi? Dağılım grafiği gibi birçok grafik, veri setinizin ham değerlerini gösterir. Diğer grafikler, sütun grafikleri gibi, yeni değerleri grafik için hesaplar:
sütun grafikleri, histogramlar ve sıklık poligonları verilerinizi kutulara bölüyor ve daha sonra her bir bölmeye düşen noktaların sayısı olan kutuları çizer.
smoothers verilerinizi bir modele uydurur ve ardından modelden çıkan tahminleri grafiğe döker.
kutu grafikleri dağılımın sağlam bir özetini hesaplar ve ardından özel olarak biçimlendirilmiş bir kutu gösterir.
Bir grafik için yeni veriler hesaplamaya yarayan algoritmaya stat denir, istatistiksel dönüşümün kısaltılmış halidir. Aşağıdaki görsel bu işlemin geom_bar() ile nasıl yapıldıgını anlatıyor.
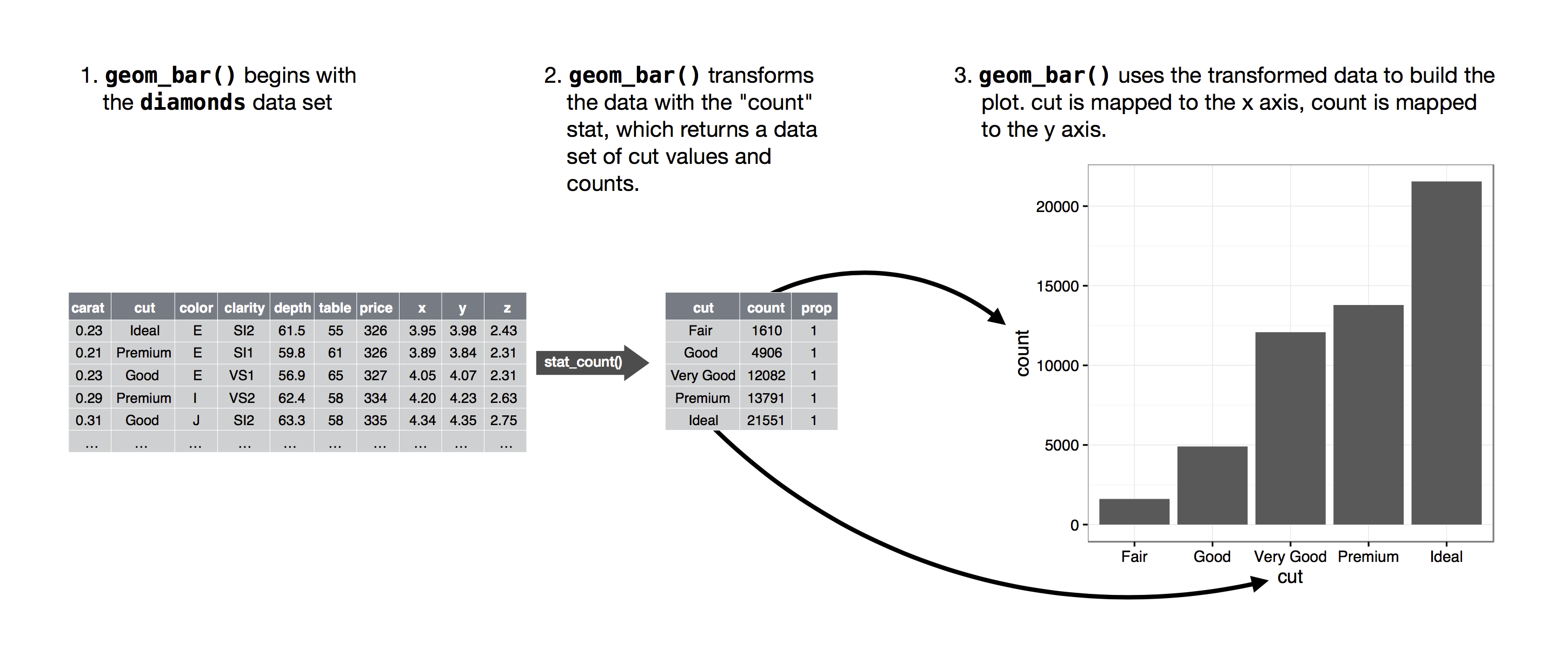
Bir geomun hangi stat değerini kullandığını, bu argümanın varsayılan haline bakarak görebilirsiniz. Örneğin, ?geom_bar’ın varsayılan stat değeri “sayıdır” (“count”), yani, geom_bar() stat_count()’u kullanır. stat_count() ile geom_bar() aynı sayfada anlatılmıştır, eğer aşağıya doğru giderseniz “Hesaplanmış değerler” isimli bölümü bulabilirsiniz. Bu, iki yeni değişkenin, count ve prop, nasıl hesaplandığını anlatır.
Genel olarak geom ve stat argümanlarınıı değişimli kullanabilirsiniz. Örneğin, önceki grafiği geom_bar() yerine stat_count() kullanarak oluşturabilirsiniz.
ggplot(data = diamonds) +
stat_count(mapping = aes(x = cut))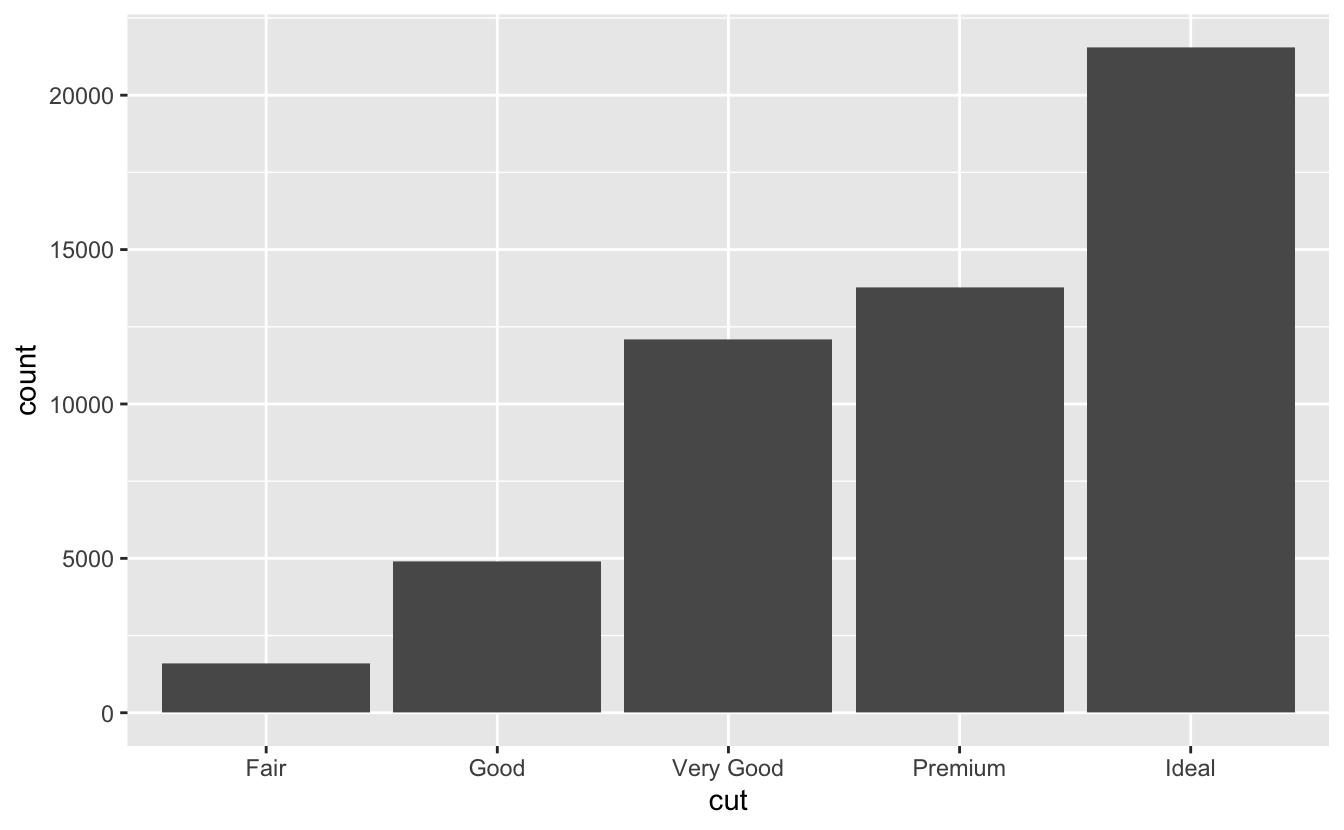
Her geomun varsayılan bir stat argümanı olmasından ötürü bu gayet iyi çalışır; aynı zamanda her stat argümanının da bir geomu vardır. Bunun anlamı, geomları altındaki istatistiksel dönüşümü dert etmeksizin kullanabilirsiniz. Özellikle stat kullanmanızı gerektirebilecek üç neden vardır:
Varsayılan stat argümanını geçersiz kılmak isteyebilirsiniz. Aşağıdaki kodda
geom_bar()’ın stat argümanını sayıdan (varsayılan) birime çevirdim. Bu, benim sütun boylarını ham \(y\) değişkenine göre eşlememe izin verdi. Maalesef, bazen insanlar sütun grafiklerinden bahsettiklerinde, sütun uzunluğu hali hazırda verinin içinde bulunan ya da önceki sütun grafiği gibi sütun uzunluğunun satır sayısı ile oluşturulduğu grafikleri kastediyor olabilirler.demo <- tribble( ~cut, ~freq, "Fair", 1610, "Good", 4906, "Very Good", 12082, "Premium", 13791, "Ideal", 21551 ) ggplot(data = demo) + geom_bar(mapping = aes(x = cut, y = freq), stat = "identity")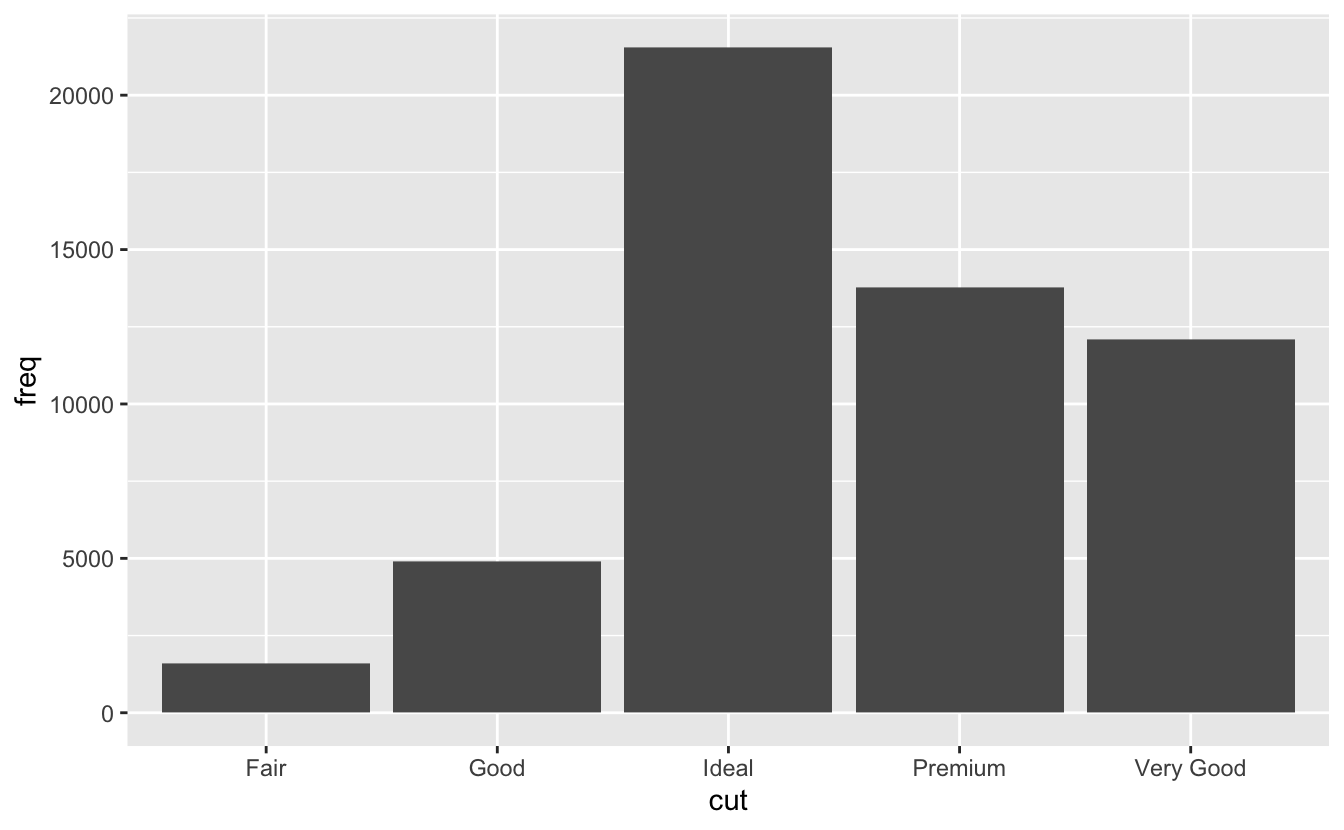
(Daha önce <- ya da tribble() fonksiyonunu görmediniz, endişelenmeyin! İçerikten anlamlarını aşağı yukarı anlayabilirsiniz, tam olarak ne yaptıklarını da yakında öğreneceksiniz!)
Varsayılan eşlemeyi dönüştürülmüş değişkenlerden estetiklere değiştirmek isteyebilirsiniz. Örneğin, sayı yerine oran gösteren bir sütun grafiği oluşturmak isteyebilirsiniz:
ggplot(data = diamonds) + geom_bar(mapping = aes(x = cut, y = ..prop.., group = 1))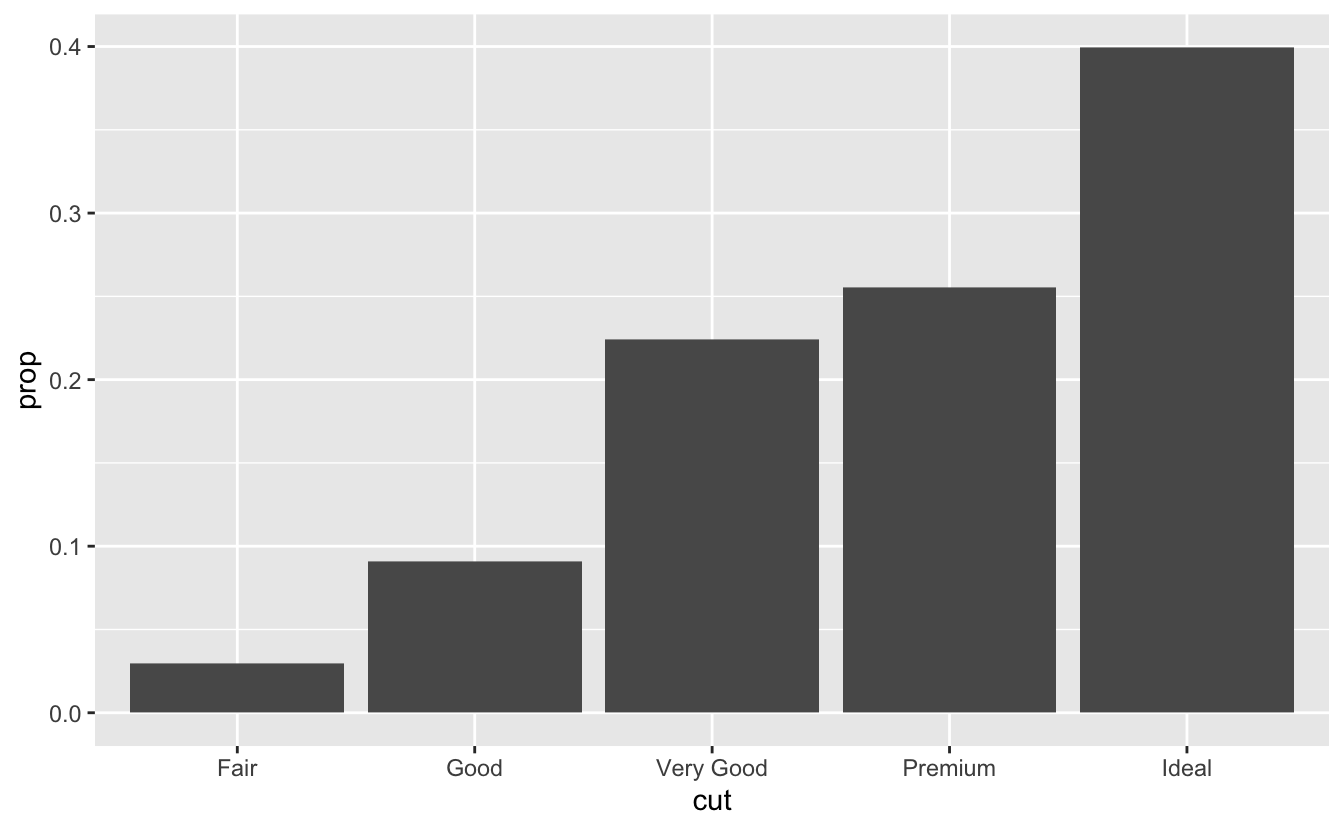
stat ile hesaplanan değişkenleri bulmak için “hesaplanan değişkenler” başlıklı yardım bölümüne bakın.
Kodunuzda, yaptığınız istatistiksel dönüşümlere daha fazla dikkat çekmek isteyebilirsiniz. Bunun için
stat_summary ()fonksiyonunu kullanabilirsiniz; her özgün x değerine karşılık hesapladığınız y değerini sunan özet bilgiye dikkat çeker.ggplot(data = diamonds) + stat_summary( mapping = aes(x = cut, y = depth), fun.ymin = min, fun.ymax = max, fun.y = median ) #> Warning: `fun.y` is deprecated. Use `fun` instead. #> Warning: `fun.ymin` is deprecated. Use `fun.min` instead. #> Warning: `fun.ymax` is deprecated. Use `fun.max` instead.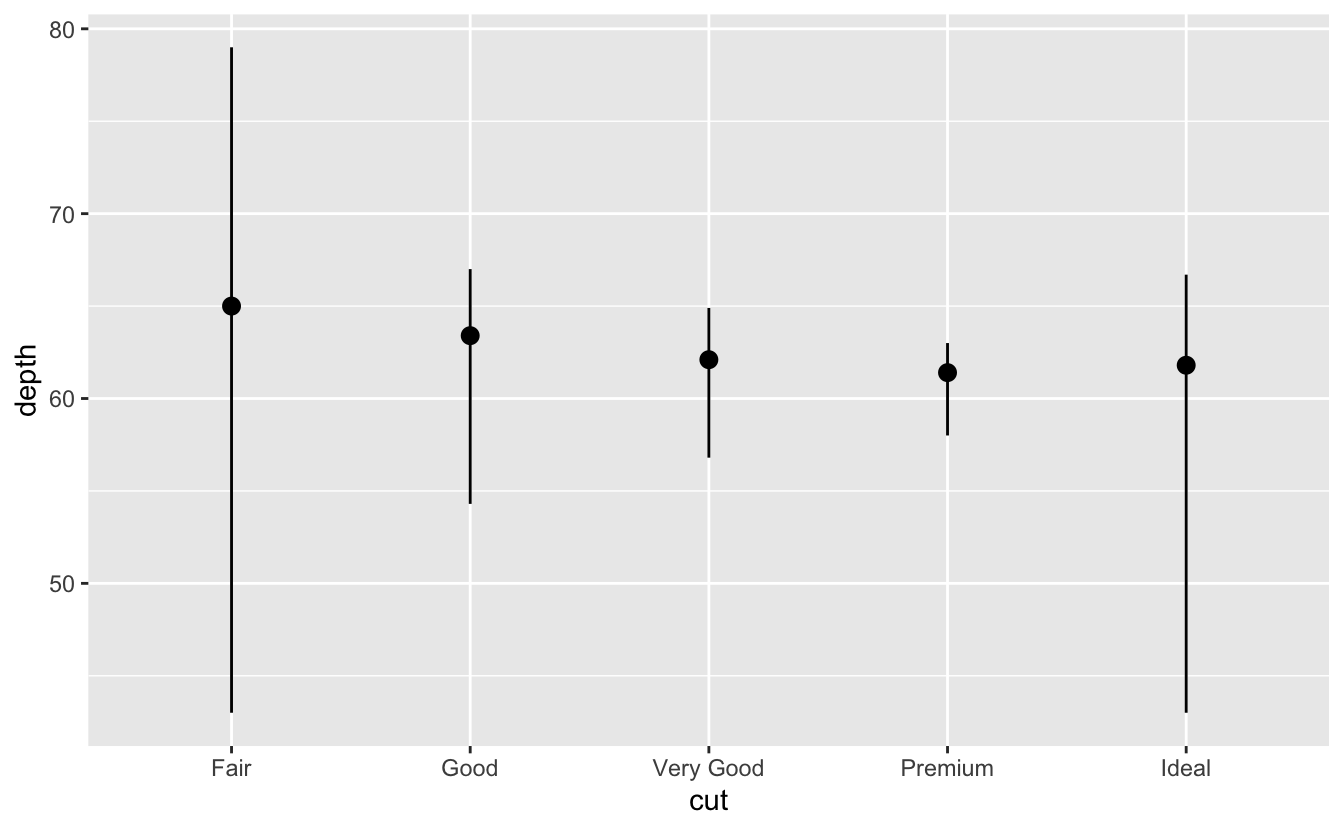
ggplot2, kullanmanız için 20’den fazla stat sunar. Her stat bir fonksiyondur, bu yüzden her zamanki gibi yardım alabilirsiniz; ör. ?stat_bin. Statların tam bir listesini görmek için ggplot2 ipuçlarına bakabilirsiniz (linki bu bölümün başlarında verilmişti).
3.7.1 Alıştırmalar
stat_summary()ile ilişkilendirilmiş varsayılan geom nedir? Bir önceki grafiğin kodunu stat yerine geom fonksiyonu kullanarak nasıl yazabilirsiniz?geom_col()fonksiyonu ne yapar?geom_bar()fonksiyonundan farkı nedir?Birçok geom ve stat, sıkça birlikte kullanılan çiftler olarak gelirler. Bunun hakkındaki belgeyi okuyup tüm çiftlerin bir listesini yapın. Ortak özellikleri nedir?
stat_smooth()fonksiyonu hangi değişkenleri hesaplar? Hangi parametreler bu fonksiyonun davranışını kontrol eder?Oran sütun grafiğimizde
group = 1ayarlamamız gerekiyor. Neden? Diğer bir deyişle, bu iki grafiğin sorunu nedir?ggplot(data = diamonds) + geom_bar(mapping = aes(x = cut, y = ..prop..)) ggplot(data = diamonds) + geom_bar(mapping = aes(x = cut, fill = color, y = ..prop..))
3.8 Konum ayarlamaları
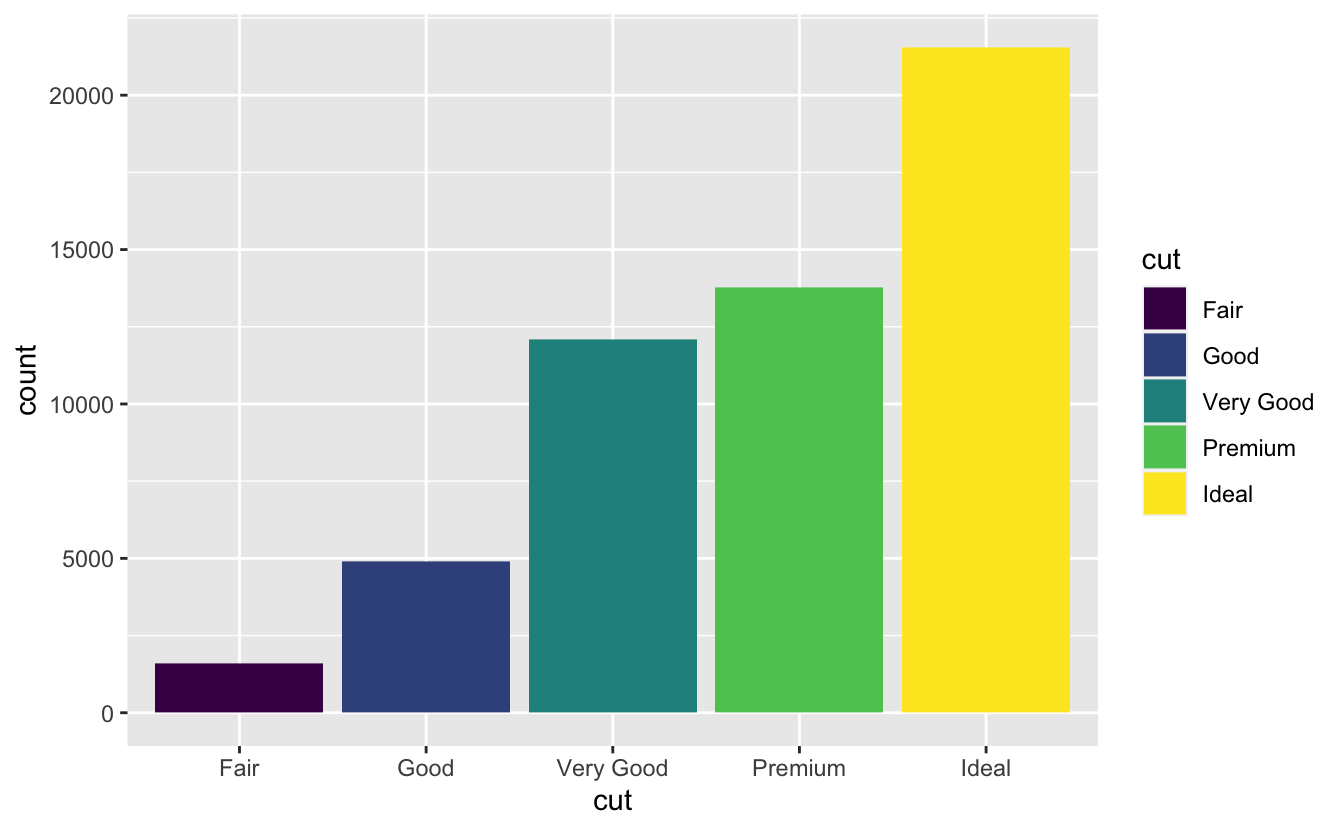
Sütun grafikleriyle ilgili sihirli bir durum daha var. ‘Renk’ estetiğini veya daha faydalı bir şekilde ‘dolgu’ seçeneğini kullanarak bir sütun grafiğini renklendirebilirsiniz:
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, colour = cut))
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, fill = cut))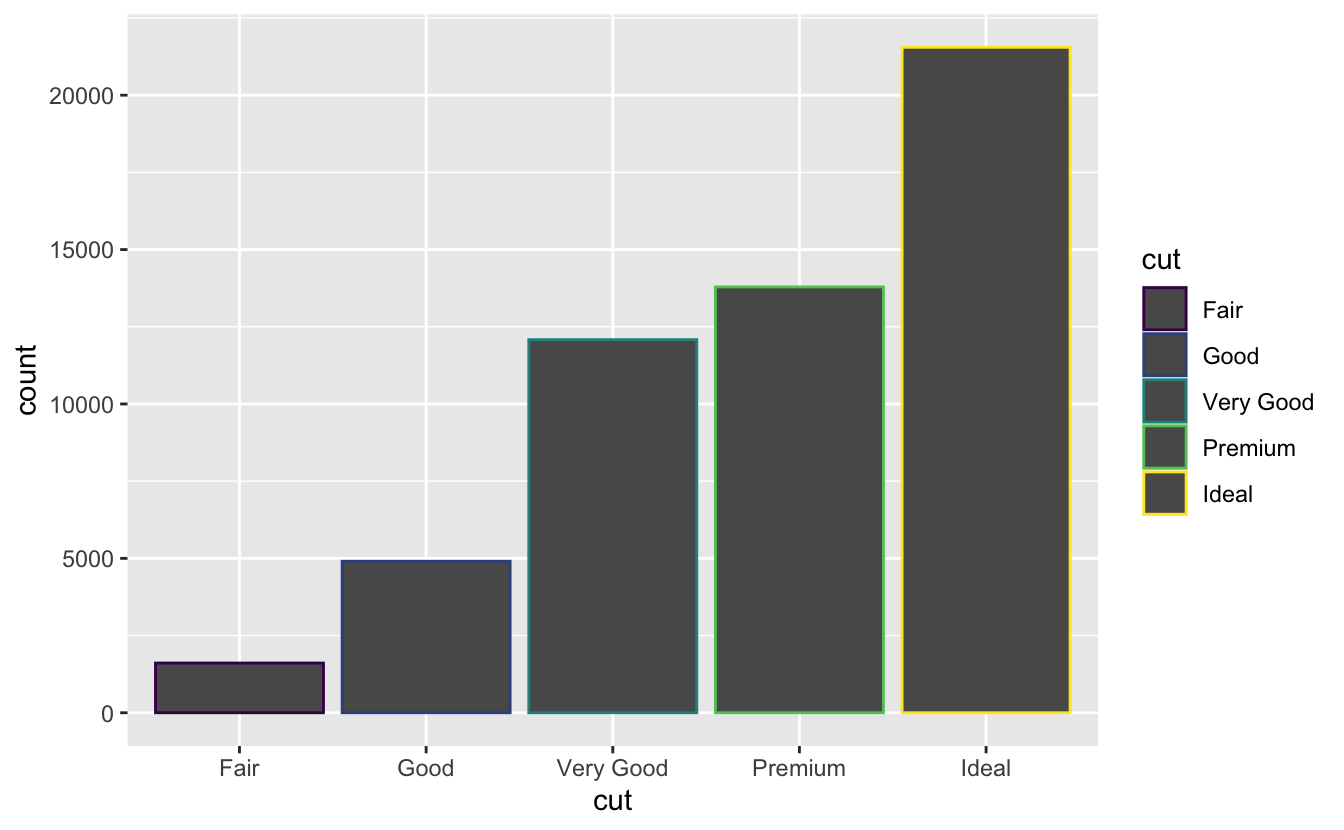
Dolgu estetiğini clarity gibi başka bir değişkene eşlerseniz ne olacağını unutmayın: Sütunlar otomatik olarak istiflenir. Her renkli dikdörtgen cut ve clarity kombinasyonunu temsil eder.
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, fill = clarity))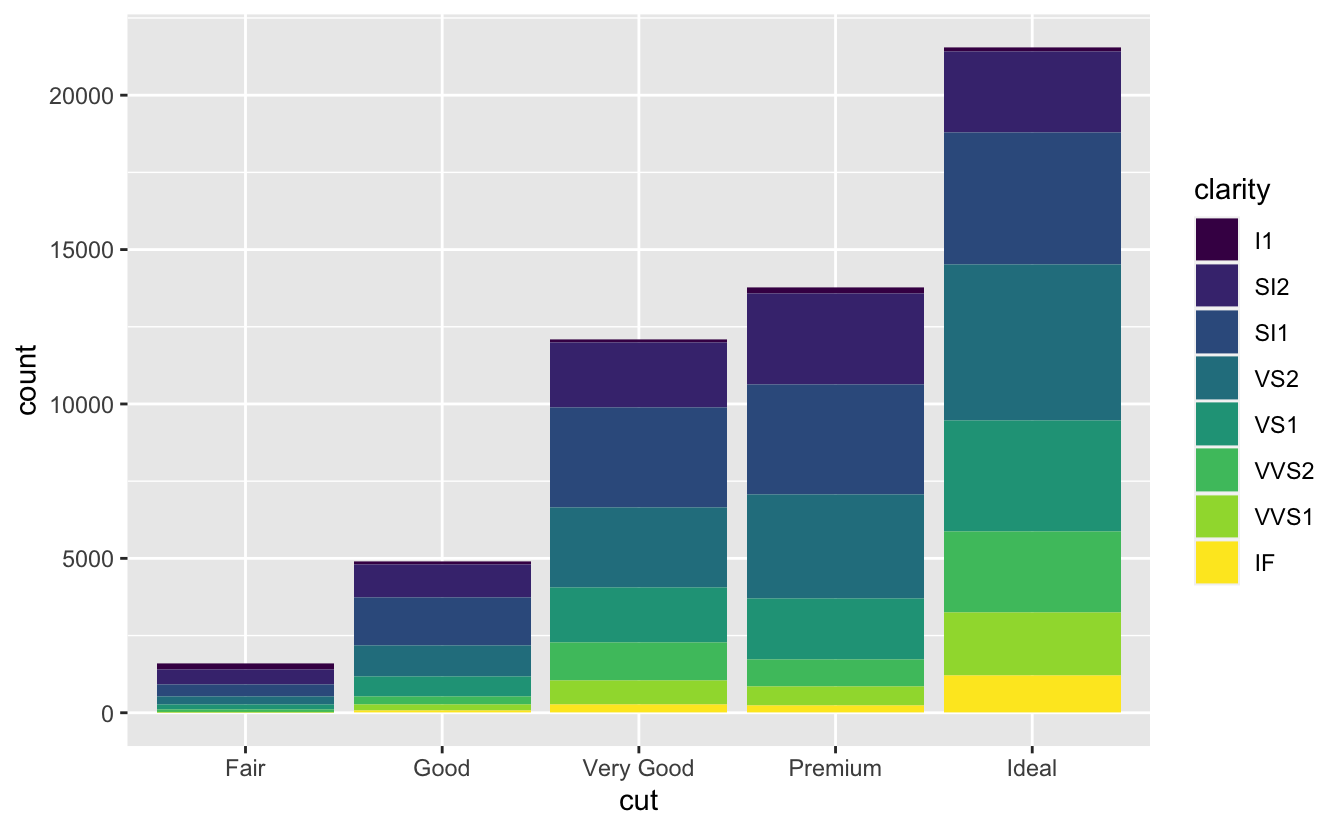
İstifleme, position argümanı tarafından belirtilen konum ayarı ile otomatik olarak gerçekleştirilir. İstifli bir sütun grafik istemiyorsanız, diğer üç seçenekten birini kullanabilirsiniz: "identity", "dodge" veya "fill".
position = "identity"her nesneyi tam olarak grafik içinde nereye denk geliyorsa oraya yerleştirir. Bu, sütunlar için çok kullanışlı değildir, çünkü üst üste binmelerine sebep olur. Üst üste binenleri görmek için ya sütunlarıalphadeğerini küçük tutarak kısmen saydam yapmamız ya dafill = NAayarını yaparak tamamen saydam yapmamız gerekir.ggplot(data = diamonds, mapping = aes(x = cut, fill = clarity)) + geom_bar(alpha = 1/5, position = "identity") ggplot(data = diamonds, mapping = aes(x = cut, colour = clarity)) + geom_bar(fill = NA, position = "identity")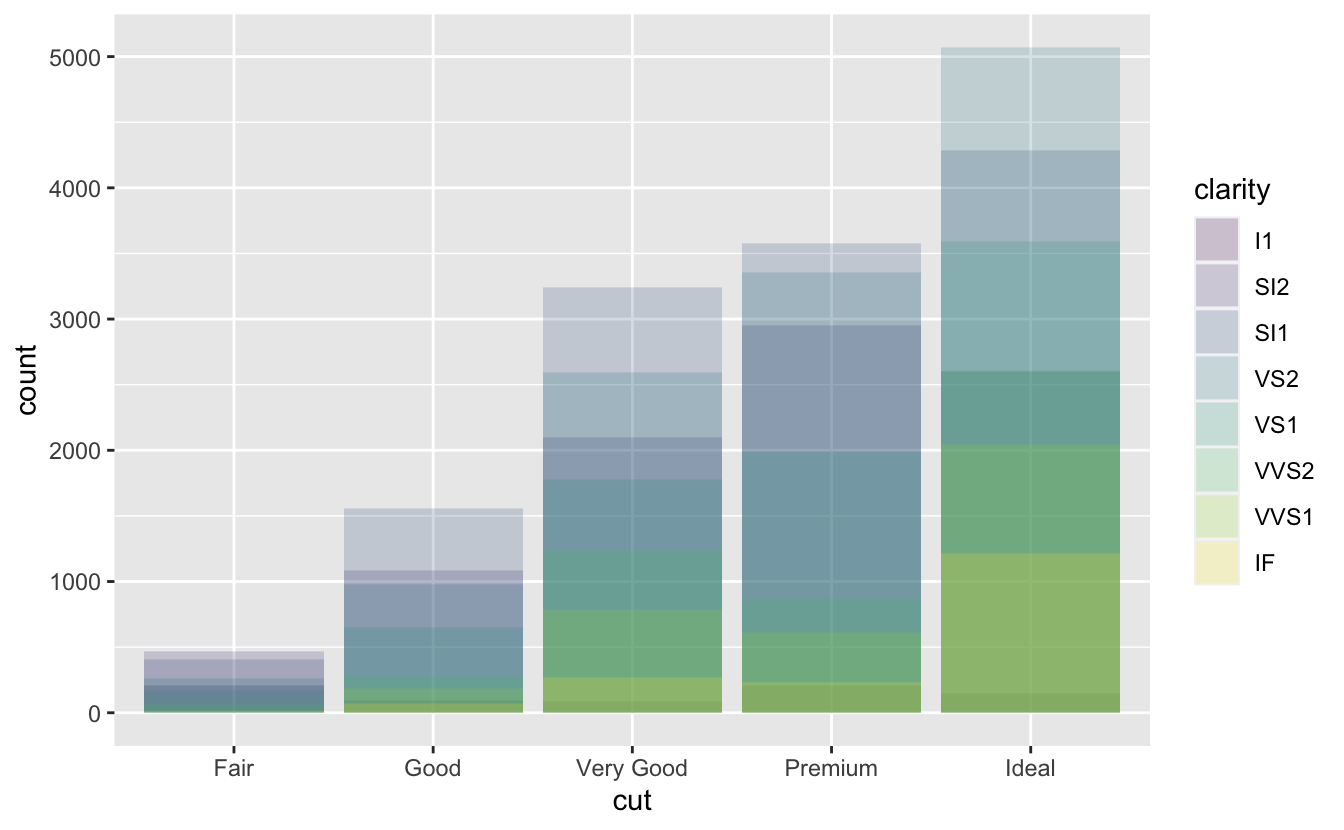
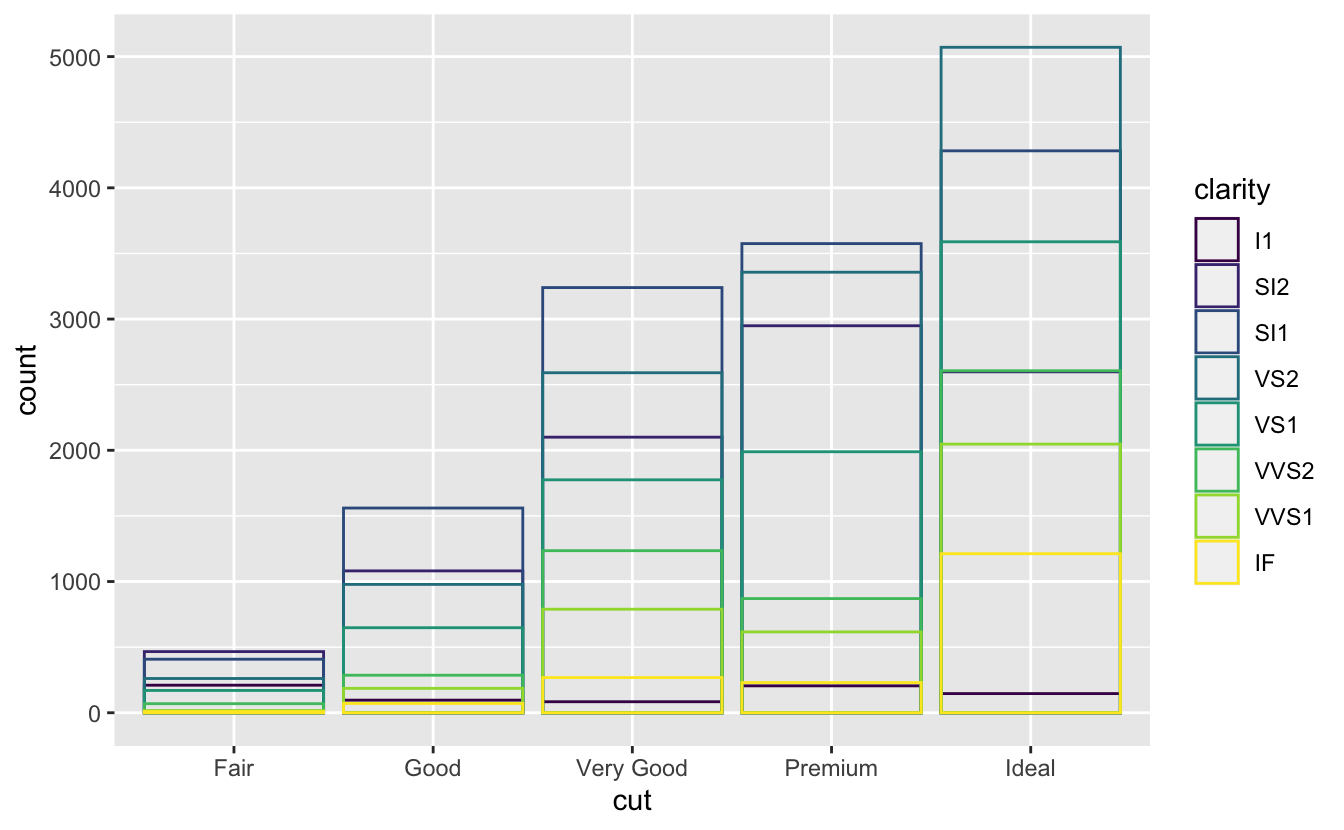
Birim konum ayarı genellikle nokta gibi 2 boyutlu geomların varsayılanıdır, onlar için daha kullanışlıdır.
position ="fill" istifleme gibi çalışır, ancak her istiflenmiş sütun setini aynı boyda oluşturur. Bu, gruplar arasındaki oranların karşılaştırılmasını kolaylaştırır.
```r
ggplot(data = diamonds) +
geom_bar(mapping = aes(x = cut, fill = clarity), position = "fill")
```
<img src="visualize_files/figure-html/unnamed-chunk-39-1.png" width="70%" style="display: block; margin: auto;" />position ="dodge"çakışan nesneleri doğrudan yan yana yerleştirir. Bu, bireysel değerleri karşılaştırmayı kolaylaştırır.ggplot(data = diamonds) + geom_bar(mapping = aes(x = cut, fill = clarity), position = "dodge")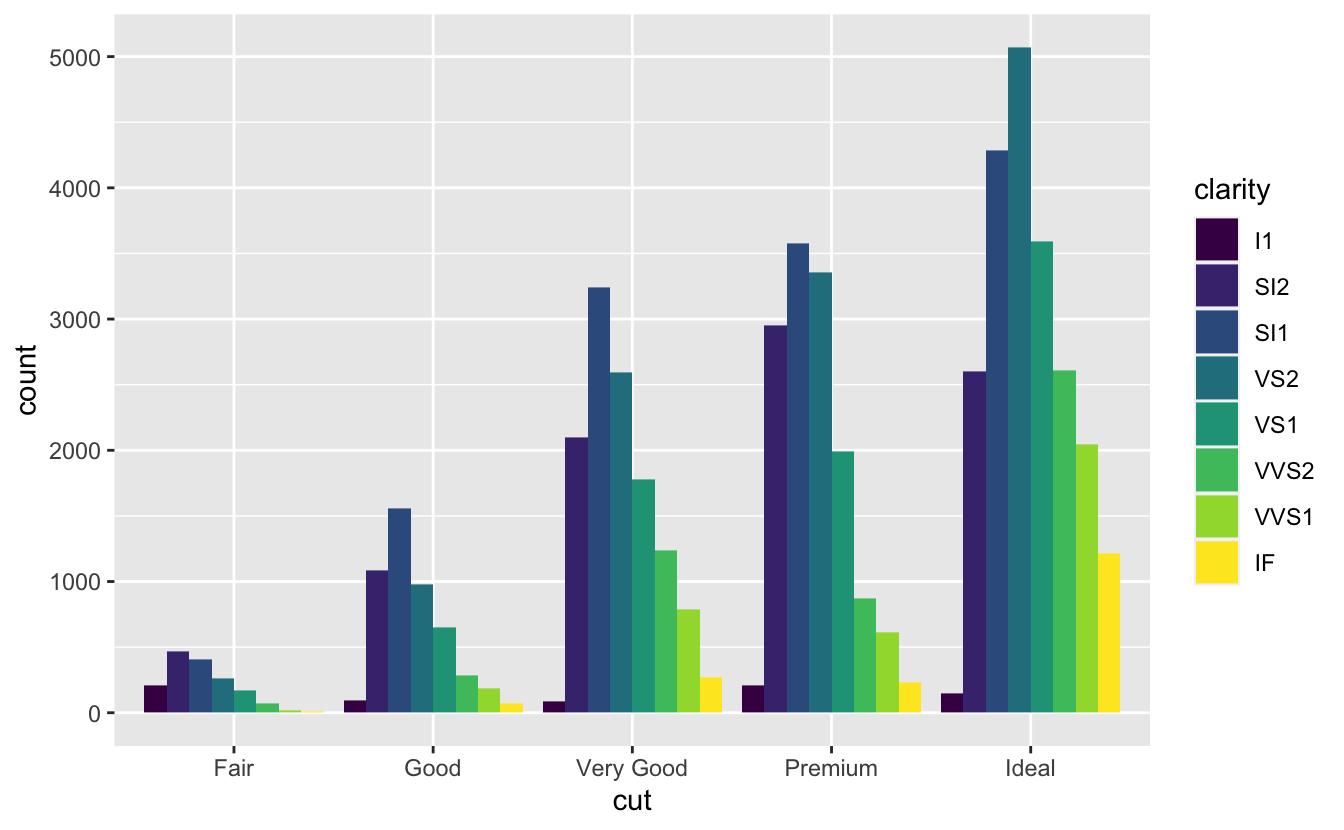
Sütun grafikler için pek kullanışlı olmayan başka bir ayarlama daha var, ancak dağılım grafikleri için çok yararlı olabilir. İlk dağılım grafiğimizi hatırlayın. Veri setinde 234 gözlem olmasına rağmen, grafiğin sadece 126 nokta gösterdiğini fark ettiniz mi?
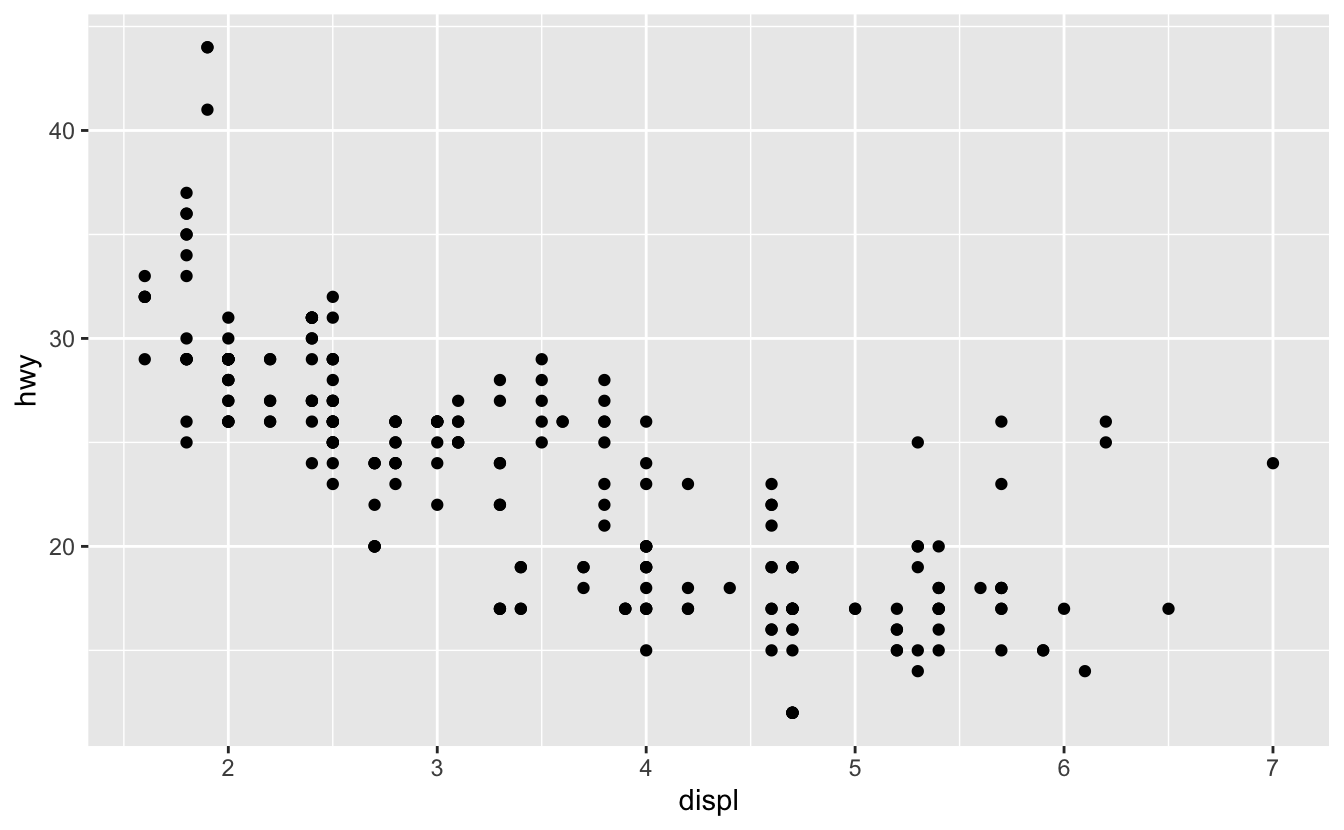
hwy ve displ değerleri yuvarlanır, böylece noktalar bir ağ üzerinde görünür ve birçok nokta birbiriyle örtüşür. Bu sorun overplotting olarak bilinir. Bu düzenleme, veri kütlesinin nerede yoğunlaştığını görmeyi zorlaştırmaktadır. Veri noktaları grafik boyunca eşit bir şekilde yayılmış mı, yoksa 109 değer içeren özel birhwy ve displ kombinasyonu mu var?
Konum ayarını “jitter”a ayarlayarak bu ağlardan kaçınabilirsiniz. position = "jitter" her noktaya az miktarda rastgele gürültü (noise) ekler. Bu, noktaları yaymaktadır çünkü iki noktanın rastgele aynı gürültü değerini alması muhtemel değildir.
ggplot(data = mpg) +
geom_point(mapping = aes(x = displ, y = hwy), position = "jitter")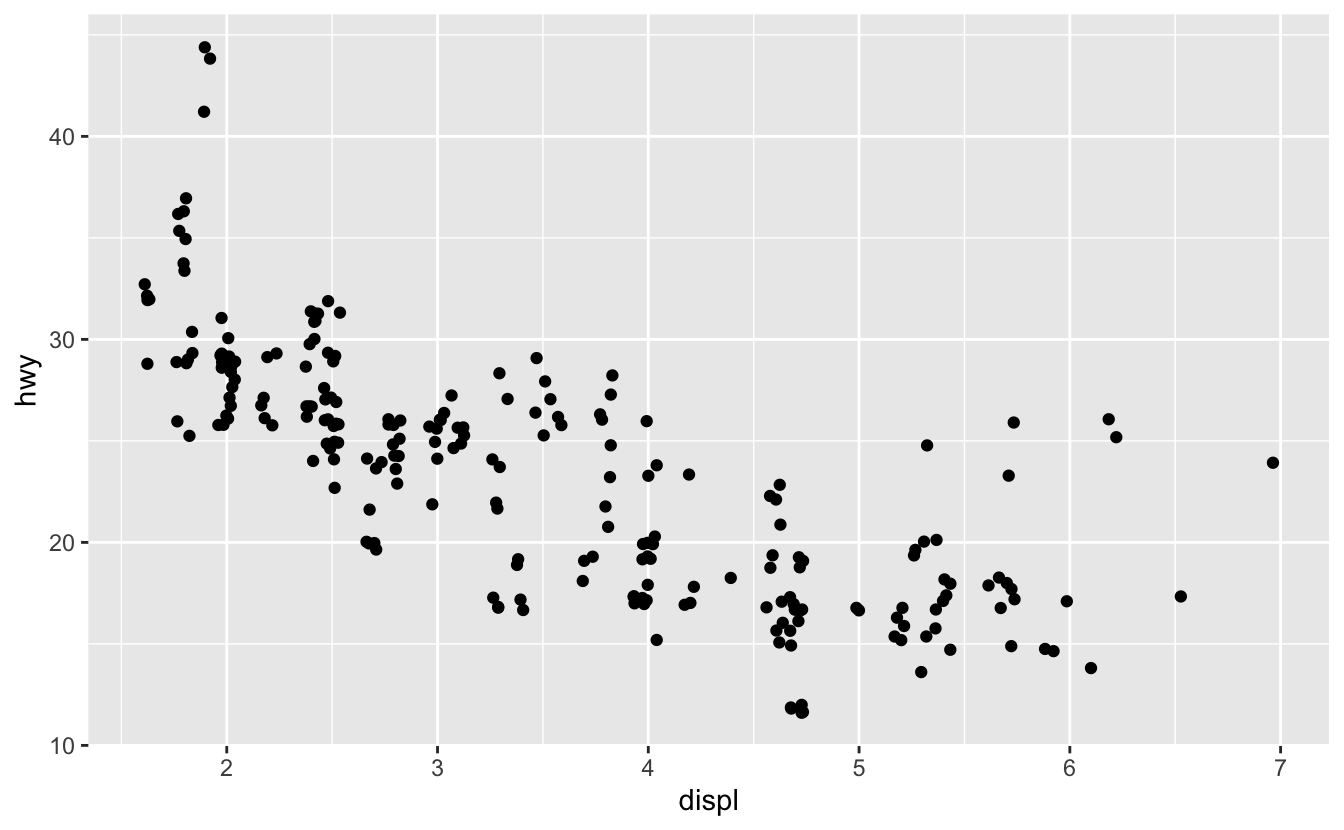
Rastgelelik eklemek grafiğinizi geliştirmek için garip bir yol gibi gözükebilir, ancak grafiğinizin küçük ölçeklerde doğruluğunu azaltmasına rağmen grafiğinizi büyük ölçeklerde daha çok ortaya çıkarır. Bu çok faydalı bir işlem olduğundan, ggplot2 geom_point(position = "jitter") için bir kısa yola sahiptir: geom_jitter().
Bir pozisyon ayarlaması hakkında daha fazla bilgi edinmek için, her bir ayarlamayla ilgili yardım sayfasına bakın: ?position_dodge, ?position_fill, ?position_identity, ?position_jitter ve ?position_stack.
3.8.1 Alıştırmalar
Bu grafikteki problem nedir? Nasıl geliştirebilirsiniz?
ggplot(data = mpg, mapping = aes(x = cty, y = hwy)) + geom_point()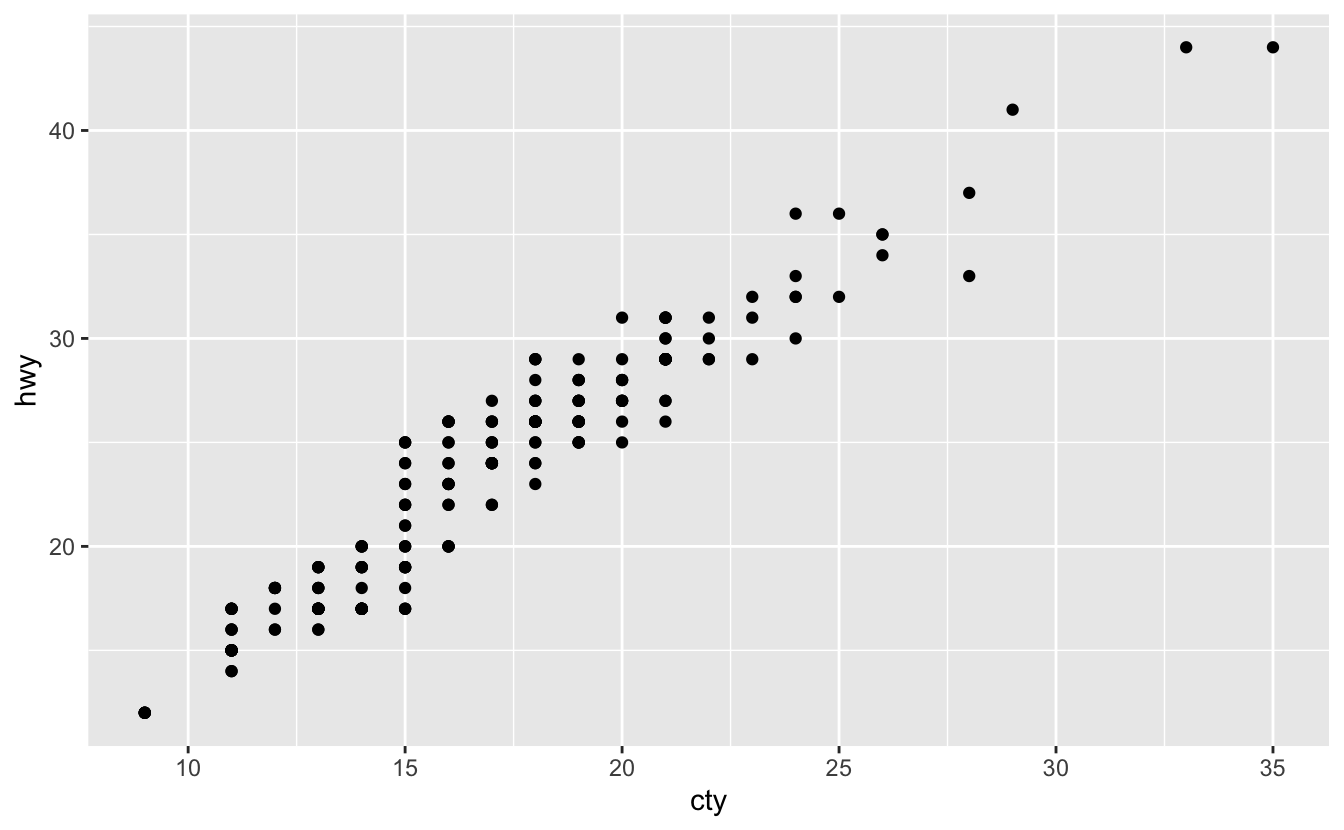
geom_jitter()’daki dağıtma ayarını hangi parametreler kontrol eder?geom_jitter()ilegeom_count()fonksiyonlarını karşılaştırın.geom_boxplot()için varsayılan konum ayarı nedir?mpgveri setini kullanarak bunu gösteren bir görsel oluşturun.
3.9 Koordinat sistemleri
Koordinat sistemleri muhtemelen ggplot2’nin en karışık kısmıdır. Varsayılan koordinat sistemi Kartezyen koordinat sistemidir, x ve y konumları her bir noktanın yerini belirlemek için bağımsız hareket ederler. Yardımcı olabilecek bir takım başka koordinat sistemleri de bulunur.
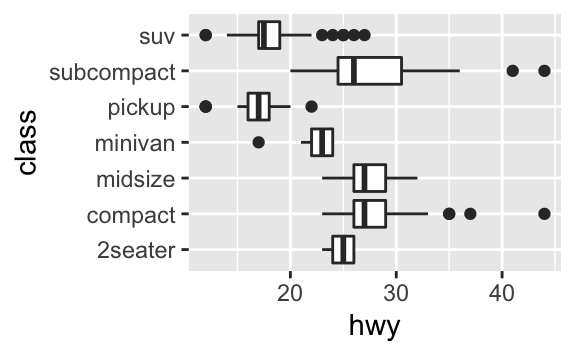
coord_flip()fonksiyonu, x ve y eksenlerinin yerlerini değiştirir. Eğer yatay kutu grafikleri istiyorsanız, bu oldukça kullanışlıdır. Aynı zamanda uzun etiketler için de yararlıdır: x ekseninde etikletleri üst üste binmeden sığdırmak zordur –>ggplot(data = mpg, mapping = aes(x = class, y = hwy)) + geom_boxplot() ggplot(data = mpg, mapping = aes(x = class, y = hwy)) + geom_boxplot() + coord_flip()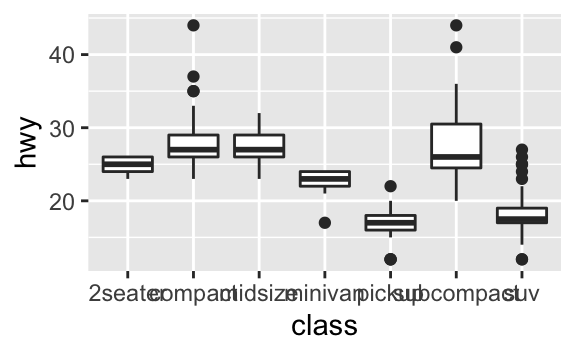
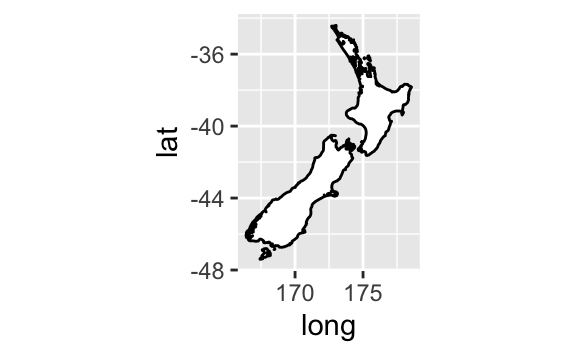
coord_quickmap(), haritalar için en-boy oranını doğru ayarlar. Eğer mekansal verileri ggplot2 ile çiziyorsanız bu çok önemlidir (maalesef bu kitapta kapsayacak yerimiz yok).nz <- map_data("nz") ggplot(nz, aes(long, lat, group = group)) + geom_polygon(fill = "white", colour = "black") ggplot(nz, aes(long, lat, group = group)) + geom_polygon(fill = "white", colour = "black") + coord_quickmap()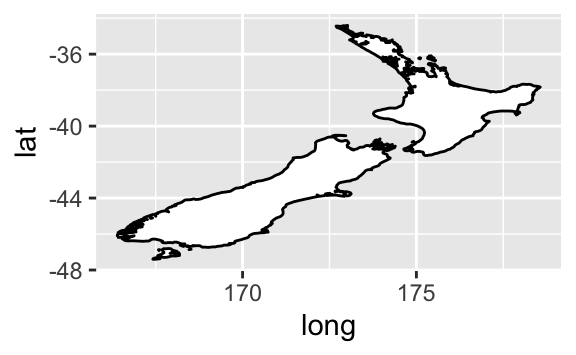
coord_polar()kutupsal koordinatları kullanır. Kutupsal koordinatları sütun grafikleri ile Coxcomb (Kutupsal Daire) grafikleri arasında ilginç bir bağlantı ortaya çıkarır.bar <- ggplot(data = diamonds) + geom_bar( mapping = aes(x = cut, fill = cut), show.legend = FALSE, width = 1 ) + theme(aspect.ratio = 1) + labs(x = NULL, y = NULL) bar + coord_flip() bar + coord_polar()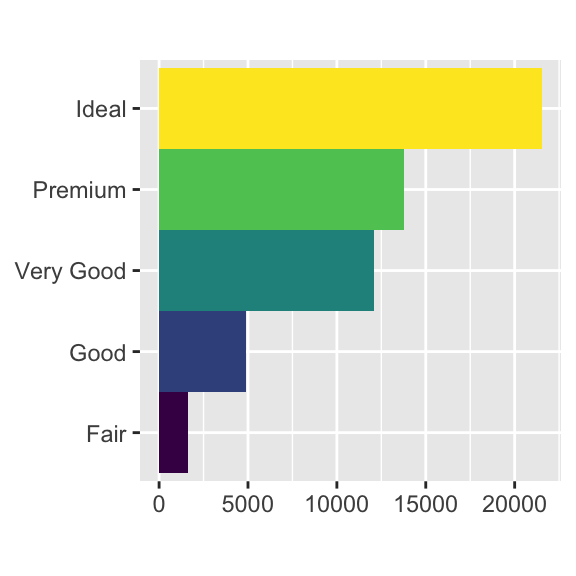
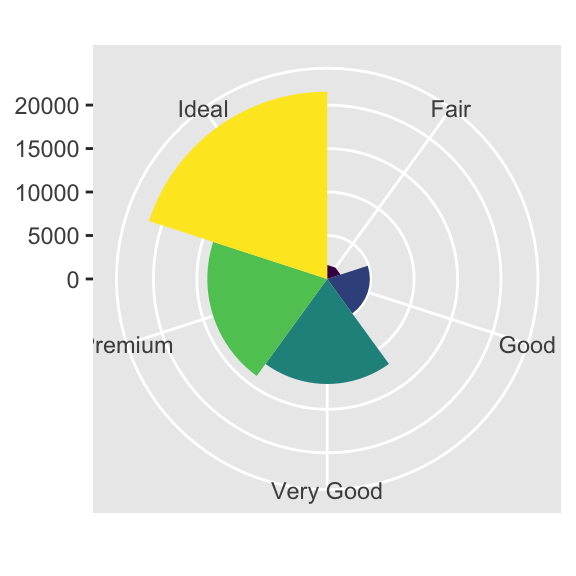
3.9.1 Alıştırmalar
İstiflenmiş bir sütun grafiğini
coord_polar()kullanarak bir pasta grafiğine çevirin.labs()fonksiyonu ne yapar?coord_quickmap()vecoord_map()arasındaki fark nedir?Aşağıdaki grafik mpg verisindeki şehir ve otoban ilişkisi hakkında ne anlatır?
coord_fixed()neden önemlidir?geom_abline()ne işe yarar?ggplot(data = mpg, mapping = aes(x = cty, y = hwy)) + geom_point() + geom_abline() + coord_fixed()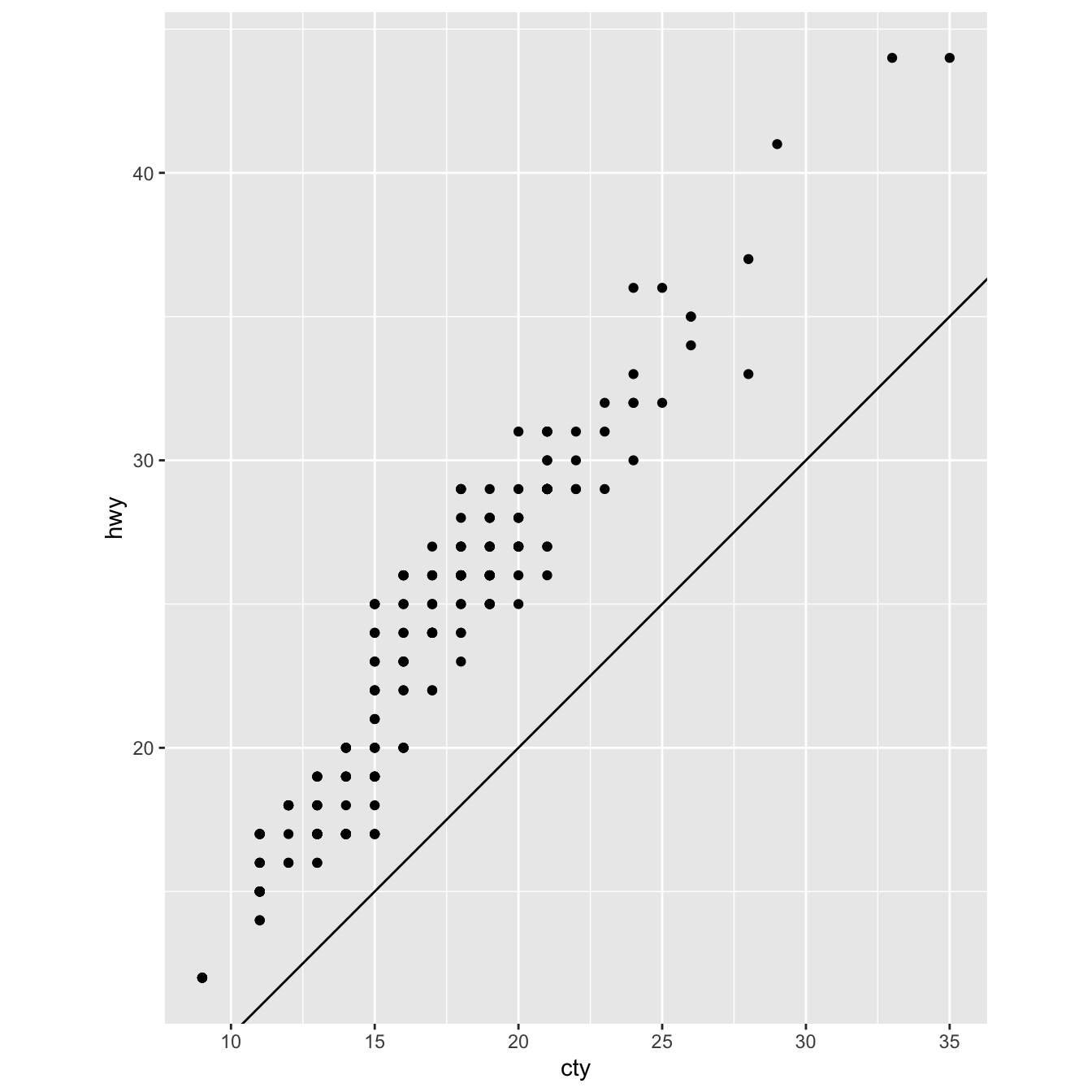
3.10 Katmanlı grafik dil bilgisi
Önceki bölümlerde, dağılım grafiklerinden, sütun ve kutu grafiklerinin nasıl yapıldığından çok daha fazlasını öğrendiniz. ggplot2 ile herhangi bir grafik yapmak için kullanabileceğiniz bir temel öğrendiniz. Bunu görmek için kod şablonumuza konum ayarlamaları, stat, koordinat sistemleri ve ayırma ekleyelim:
ggplot(data = <DATA>) +
<GEOM_FUNCTION>(
mapping = aes(<MAPPINGS>),
stat = <STAT>,
position = <POSITION>
) +
<COORDINATE_FUNCTION> +
<FACET_FUNCTION>Yeni şablonumuzda, parantez içindeki kelimelerle berlirtilen yedi parametre var. Uygulamada, bir grafik oluşturmak için nadiren yedi parametrenin tümünü sağlamanız gerekir, çünkü ggplot2 veri, eşlemeler ve geom fonksiyonu dışındaki her şey için varsayılan ayarları sağlar.
Şablondaki yedi parametre, grafikleri oluşturmak için resmi bir sistem olan grafiklerin gramerini oluşturur. Grafiklerin dilbilgisi, herhangi bir grafiği bir veri kümesi, bir geom, bir dizi eşleme, bir stat, bir konum ayarlaması, bir koordinat sistemi ve bir ayırma şeması kombinasyonu olarak özgün bir şekilde tanımlayabileceğiniz anlayışına dayanmaktadır.
Bunun nasıl çalıştığını görmek için, sıfırdan basit bir grafiği nasıl yapabileceğinizi düşünün: Bir veri setiyle başlayıp ardından onu (bir stat ile) görüntülemek istediğiniz bilgilere dönüştürebilirsiniz.

Daha sonra, dönüştürülen verilerdeki her bir gözlemi temsil etmek için geometrik bir nesne seçebilirsiniz. Sonra verilerdeki değişkenleri temsil etmek için geomların estetik özelliklerini kullanabilirsiniz. Her değişkenin değerlerini estetik kademelerle eşleştirebilirsiniz.
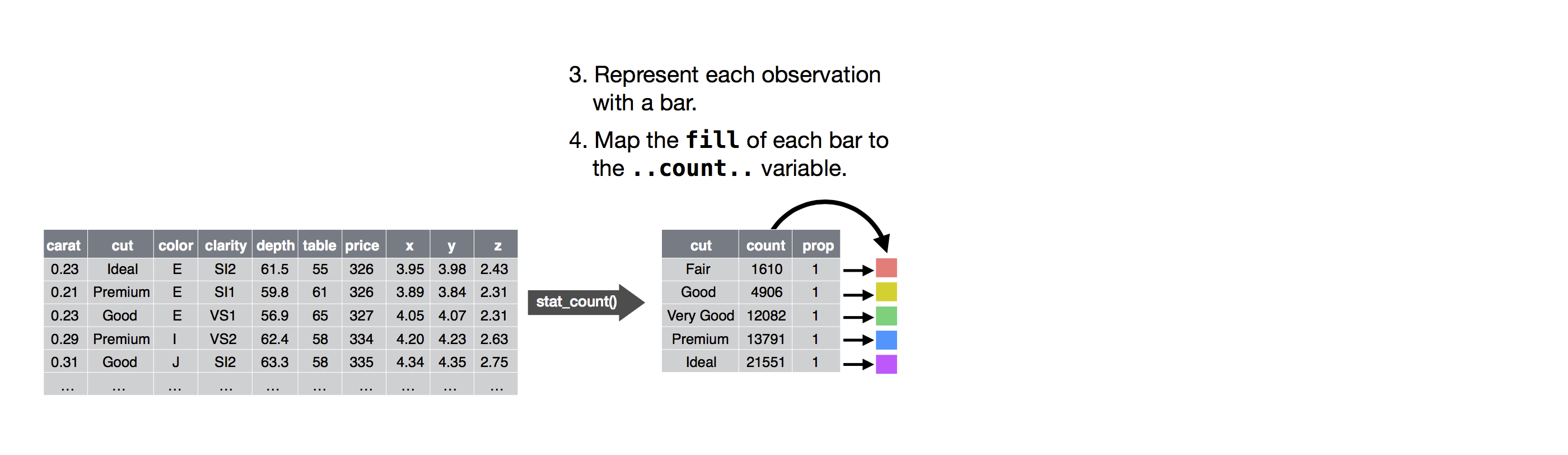
Daha sonra geomları yerleştirmek için bir koordinat sistemi seçersiniz. x ve y değişkenlerinin değerlerini görüntülemek için nesnelerin konumunu (kendisi estetik bir özelliktir) kullanırsınız. Bu noktada tam bir grafiğiniz olacaktır, ancak koordinat sistemi içindeki geomların konumlarını daha da ayarlayabilir (bir konum ayarı ile) ya da grafiği alt grafiklere (ayırma ile) bölebilirsiniz. Grafiği, her bir ek veri kümesinin, bir geomun, bir dizi eşlemenin, bir statın ve bir konum ayarının kullanıldığı bir veya daha fazla ek katman ekleyerek de genişletebilirsiniz.
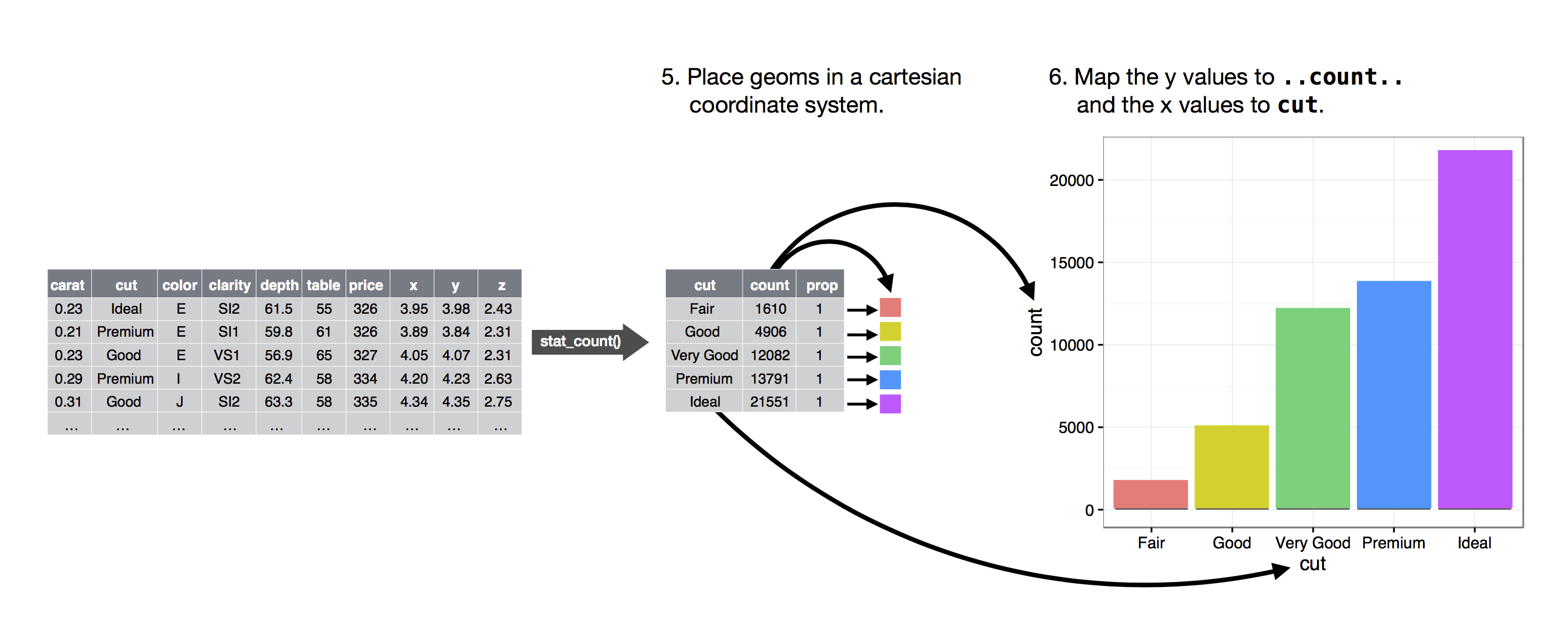
Bu yöntemi, hayal ettiğiniz herhangi bir grafiği oluşturmak için kullanabilirsiniz. Başka bir deyişle, bu bölümde öğrendiğiniz kod şablonunu, yüz binlerce benzersiz çizim oluşturmak için kullanabilirsiniz.