5 Veri dönüşümü
5.1 Giriş
Görselleştirme, fikir üretme için önemli bir araçtır, ancak verileri tam olarak ihtiyacınız olan biçimde elde etmeniz nadirdir. Genellikle bazı yeni değişkenler veya özetler oluşturmanız gerekir, ya da sadece verilerle çalışmayı biraz daha kolay hale getirmek için değişkenleri yeniden adlandırmak veya gözlemleri yeniden sıralamak istersiniz. Tüm bunları (ve daha fazlasını!) nasıl yapacağınızı dplyr paketini kullanarak veri dönüştürmeyi ve 2013’te New York City’den kalkan uçuşları içeren bir veri setini öğretecek bu bölümde öğreneceksiniz.
5.1.1 Ön koşullar
Bu bölümde, tidyverse’un bir başka çekirdek üyesi olan dplyr paketinin nasıl kullanılacağına odaklanacağız. nycflights13 paketindeki verileri kullanarak temel fikirleri açıklayacağız ve verileri anlamamıza yardımcı olması için ggplot2’yi kullanacağız.
library(nycflights13)
library(tidyverse)tidyverse’ü yüklerken yazdırılan çakışma mesajına dikkat edin. dplyr’ın R tabanındaki bazı fonksiyonların üzerine yazdığını söyler. dplyr yüklendikten sonra bu işlevlerin temel sürümünü kullanmak istiyorsanız, tam adlarını kullanmanız gerekir: stats::filter() ve stats::lag().
5.1.2 nycflights13
dplyr’in temel veri işleme fiillerini keşfetmek için nycflights13::flights kullanacağız. Bu veri tablosu 2013’te New York City’den kalkmış olan tüm 336,776 uçuşu içerir. Veriler ABD Ulaştırma İstatistikleri Bürosu’ndan geliyor ve ?flights altında belgelendirilmiştir.
(http://www.transtats.bts.gov/DatabaseInfo.asp?DB_ID=120&Link=0)
flights
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # … with 336,770 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>Bu veri tablosunun geçmişte kullanmış olabileceğiniz diğer veri tablolarından biraz farklı yazdırıldığını fark edebilirsiniz: yalnızca ilk birkaç satırı ve bir ekrana sığan sütunları gösterir. (Veri setinin tamamını görmek için, verisetini RStudio görüntüleyicisinde açacak olan View(flights) komutunu çalıştırabilirsiniz). Farklı yazdırılıyor çünkü bu bir tibble. Tibble’lar veri tablolarıdır, ancak tidyverse ile daha iyi çalışabilmek için biraz ayarlanmıştır. Şimdilik farklar konusunda endişelenmenize gerek yok; tibble’lar konusuna daha detaylı olarak veri cambazlığı bölümünde geri döneceğiz.
Ayrıca sütun adlarının altındaki üç (veya dört) harfli kısaltma satırını da fark etmiş olabilirsiniz. Bunlar her değişkenin türünü tanımlar:
inttamsayı anlamına gelir.dbl“double” ya da gerçek sayı anlamına gelir.chrkarakter veya dizge anlamına gelir.dttmtarih-zaman (bir tarih + bir zaman) anlamına gelir.
Bu veri kümesinde kullanılmayan ancak kitapta daha sonra karşılaşacağınız üç yaygın değişken türü daha vardır:
lglmantıksal anlamına gelir, sadeceTRUEveFALSEiçeren vektörlerdir.fctrfaktör anlamına gelr, R bunları olası değerleri önceden belirlenmiş kategorik değişkenleri temsil etmek için kullanır.datetarih anlamına gelir.
5.1.3 dplyr temelleri
Bu bölümde, veri işleme zorluklarınızın büyük çoğunluğunu çözmenizi sağlayacak veren beş temel dplyr fonksiyonunu öğreneceksiniz:
- Değerlerine göre gözlemleri seçme (
filter()). - Satırları yeniden sıralama (
arrange()). - İsimlerine göre değişkenleri seçme (
select()). - Mevcut değişkenlerin fonksiyonları ile yeni değişkenler oluşturma (
mutate()). - Çok sayıda değeri tek bir özete indirgeme (
summarise()).
Bunların hepsi, her işlevin kapsamını tüm veri seti yerine gruplarda çalışacak şekilde değiştiren group_by() ile birlikte kullanılabilir. Bu altı fonksiyon, bir veri işleme dili için fiilleri sağlar.
Tüm fiiller benzer şekilde çalışır:
İlk argüman bir veri tablosudur.
Sonraki argümanlar, değişken adlarını (tırnak işaretleri olmadan) kullanarak veri tablosuyla ne yapılacağını açıklar.
Sonuç yeni bir veri tablosudur.
Bu özellikler birlikte, birden çok basit adımı birbirine zincirleyerek karmaşık sonuçlar elde etmeyi kolaylaştırır. Şimdi işe başlayalım ve bu fiillerin nasıl çalıştığını görelim.
5.2 filter() ile satırları filtreleme
filter(), gözlemleri değerlerine göre alt kümeye alarak seçmenizi sağlar. İlk argüman veri tablosunun adıdır. İkinci ve sonraki argümanlar, veri tablosunu filtreleyen ifadelerdir. Örneğin, 1 Ocak’taki tüm uçuşları şu şekilde seçebiliriz:
filter(flights, month == 1, day == 1)
#> # A tibble: 842 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # … with 836 more rows, and 11 more variables: arr_delay <dbl>, carrier <chr>,
#> # flight <int>, tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>,
#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>Bu kod satırını çalıştırdığınızda, dplyr filtreleme işlemini yürütür ve yeni bir veri tablosu verir. dplyr işlevleri girdi olarak verilen veriyi asla değiştirmez, bu nedenle sonucu kaydetmek isterseniz, atama operatörünü kullanmanız gerekir: <-:
jan1 <- filter(flights, month == 1, day == 1)R sonuçları ya yazdırır ya da bir değişkene kaydeder. Her ikisini de yapmak istiyorsanız, atama işlemini parantez içine alabilirsiniz:
(dec25 <- filter(flights, month == 12, day == 25))
#> # A tibble: 719 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 12 25 456 500 -4 649 651
#> 2 2013 12 25 524 515 9 805 814
#> 3 2013 12 25 542 540 2 832 850
#> 4 2013 12 25 546 550 -4 1022 1027
#> 5 2013 12 25 556 600 -4 730 745
#> 6 2013 12 25 557 600 -3 743 752
#> # … with 713 more rows, and 11 more variables: arr_delay <dbl>, carrier <chr>,
#> # flight <int>, tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>,
#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>5.2.1 Karşılaştırmalar
Filtrelemeyi etkili bir şekilde kullanmak için karşılaştırma operatörlerini kullanarak istediğiniz gözlemleri nasıl seçeceğinizi bilmeniz gerekir. R standart paketi sağlar: >, >=, <, <=, != (eşit değildir), ve == (eşittir).
R’a yeni başlarken, en kolay hata eşitliği test ederken == yerine = kullanmaktır. Bu olduğunda, bilgilendirici bir hata alırsınız:
filter(flights, month = 1)
#> Error in `filter()`:
#> ! We detected a named input.
#> ℹ This usually means that you've used `=` instead of `==`.
#> ℹ Did you mean `month == 1`?== kullanırken karşılaşabileceğiniz başka bir yaygın sorun daha var: gerçek sayılar. Bu sonuçlar sizi şaşırtabilir!
sqrt(2) ^ 2 == 2
#> [1] FALSE
1 / 49 * 49 == 1
#> [1] FALSEBilgisayarlar sonlu aritmetik kullanırlar (tabii ki sonsuz sayıda basamak saklayamazlar!). Bu nedenle, gördüğünüz her sayının bir tahmin olduğunu unutmayın. == operatörüne güvenmek yerine near() kullanın:
near(sqrt(2) ^ 2, 2)
#> [1] TRUE
near(1 / 49 * 49, 1)
#> [1] TRUE5.2.2 Mantıksal operatörler
filter() içindeki argümanlar “ve” ile bağlanır: çıktıda bir satırın yer alması için tüm ifadelerin doğru olması gerekir. Diğer birleştirme argümanları için, Boolean (mantıksal) operatörleri kullanmanız gerekir: & “ve”, | “veya”, ve ! “değildir”. Tüm mantıksal operatörler Figür 5.1de verilmiştir.
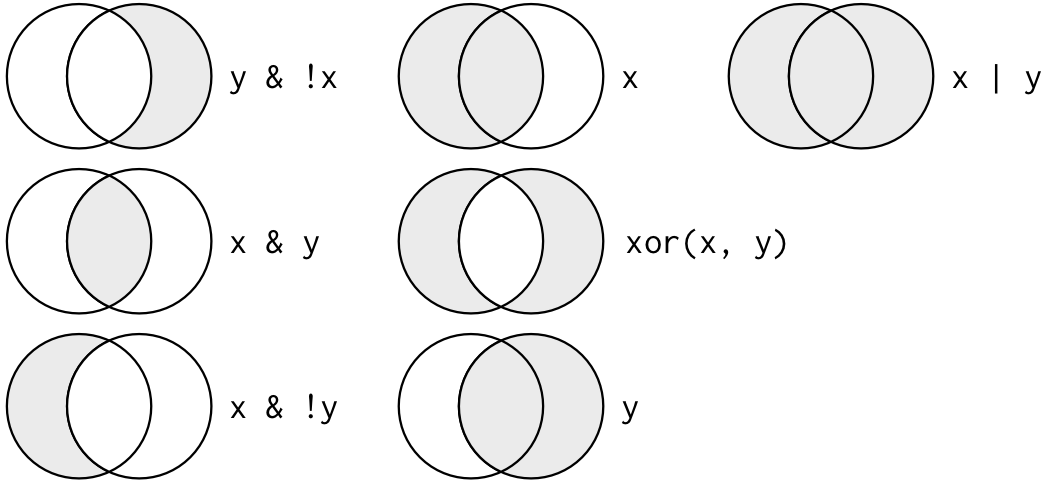
Figure 5.1: Tüm mantıksal operatörler. x sol çember, y sağ çember ve gölgeli bölge her operatörün hangi parçaları seçtiğini gösterir.
Aşağıdaki kod, Kasım veya Aralık ayında kalkan tüm uçuşları bulur:
filter(flights, month == 11 | month == 12)Operatörlerin sırası Türkçe’de olduğu gibi işlemez. Kelimesi kelimesine “Kasım ya da Aralık ayındaki tüm uçuları bul” olarak çevirebileceğiniz filter(flights, month == 11 | 12) komutunu yazamazsınız. Bu onun yerine, 11 | 12ye eşit olan tüm ayları bulur, bu ifade de TRUEdır. Sayısal bir bağlamda (burada olduğu gibi) TRUE, bire dönüşür, yani bu Kasım veya Aralık ayındaki değil Ocak ayındaki tüm uçuşları bulur. Bu oldukça kafa karıştırıcı!
Bu durum için yararlı bir kısa yol x %in% y komutudur. Bu x in y içerisinde yer aldığı tüm satırları seçer. Bunu yukarıdaki kodu tekrar yazmak için kullanabiliriz:
nov_dec <- filter(flights, month %in% c(11, 12))Bazen karmaşık bir altküme operasyonunu De Morgan kuralını hatırlayarak basitleştirebilirsiniz: !(x & y) ile !x | !y aynıdır, ve !(x | y) ile !x & !y aynıdır. Örneğin, iki saatten fazla gecikmeli (varışta veya kalkışta) olmayan uçuşlar bulmak istiyorsanız, aşağıdaki iki filtreden birini kullanabilirsiniz:
filter(flights, !(arr_delay > 120 | dep_delay > 120))
filter(flights, arr_delay <= 120, dep_delay <= 120)& ve | yanı sıra, R’da ayrıca && ve || vardır. Onları burada kullanmayın! Bunları ne zaman kullanmanız gerektiğini koşullu yürütme’de öğreneceksiniz.
filter() içinde karmaşık, çok parçalı ifadeler kullanmaya başladığınızda, bunları açık değişkenler haline getirmeyi düşünün. Bu, çalışmanızı kontrol etmeyi çok daha kolay hale getirir. Kısa süre içinde yeni değişkenlerin nasıl oluşturulacağını öğreneceksiniz.
5.2.3 Eksik değerler
R’ın karşılaştırmayı zorlaştırabilen önemli bir özelliği eksik değerler veya NA’lar (“mevcut değil”). NA bilinmeyen bir değeri temsil eder, bu nedenle eksik değerler “bulaşıcı”dır: bilinmeyen bir değeri içeren hemen hemen her işlem de bilinmeyecektir.
NA > 5
#> [1] NA
10 == NA
#> [1] NA
NA + 10
#> [1] NA
NA / 2
#> [1] NAEn kafa karıştırıcı sonuç şudur:
NA == NA
#> [1] NABunun neden daha doğru olduğunu biraz daha bağlamla anlamak en kolayı:
# x, Mary'nin yaşı olsun. Kaç yaşında olduğunu bilmiyoruz.
x <- NA
# y, John'un yaşı olsun. Kaç yaşında olduğunu bilmiyoruz.
y <- NA
# John ve Mary aynı yaşta mı?
x == y
#> [1] NA
# Bilmiyoruz!Bir değerin eksik olup olmadığını belirlemek istiyorsanız, is.na() kullanın:
is.na(x)
#> [1] TRUEfilter() yalnızca koşulun TRUE olduğu satırları içerir; hem FALSE hem de NA değerlerini çıkarır. Eksik değerleri korumak istiyorsanız, bunları açıkça isteyin:
df <- tibble(x = c(1, NA, 3))
filter(df, x > 1)
#> # A tibble: 1 × 1
#> x
#> <dbl>
#> 1 3
filter(df, is.na(x) | x > 1)
#> # A tibble: 2 × 1
#> x
#> <dbl>
#> 1 NA
#> 2 35.2.4 Alıştırmalar
Aşağıdaki koşulları sağlayan tüm uçuşları bulun
- İki veya daha fazla saatlik varış gecikmesi olan
- Houston’a uçan (
IAHorHOU) - United, American, veya Delta tarafından işletilen
- Yazın kalkan (Temmuz, Ağustos, ve Eylül)
- İki saatten fazla gecikmeyle gelen ancak gecikmesiz kalkan
- En az bir saat gecikmeli olan ancak 30 dakikadan fazlasını uçuşta telafi eden
- Gece yarısı ile 06:00 (dahil) arasında kalkan
Bir diğer yararlı dplyr filtreleme yardımcısı da
between()dir. Bu ne işe yarıyor? Önceki soruları yanıtlamak için gereken kodu basitleştirmek için kullanabilir misiniz?Kaç uçuşta “dep_time” eksik? Başka hangi değişkenler eksik? Bu satırlar neyi temsil ediyor olabilir?
Neden
NA ^ 0eksik değildir? NedenNA | TRUEeksik değildir? NedenFALSE & NAeksik değildir? Genel kuralı bulabilir misiniz? (NA * 0zorlu bir karşı örnek!)
5.3 arrange() ile satırları düzenleme
arrange(), satırları seçmek yerine sıralarını değiştirmesi dışında filter() ile benzer şekilde çalışır. Bir veri tablosu ve sıralama için bir dizi sütun adı (veya daha karmaşık ifadeler) alır. Birden fazla sütun adı girerseniz, her bir ek sütun, önceki sütunların değerlerindeki eşit değerleri koparmak için kullanılır:
arrange(flights, year, month, day)
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # … with 336,770 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>Bir sütuna göre azalan sırada yeniden sıralamak için desc() kullanın:
arrange(flights, desc(dep_delay))
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 9 641 900 1301 1242 1530
#> 2 2013 6 15 1432 1935 1137 1607 2120
#> 3 2013 1 10 1121 1635 1126 1239 1810
#> 4 2013 9 20 1139 1845 1014 1457 2210
#> 5 2013 7 22 845 1600 1005 1044 1815
#> 6 2013 4 10 1100 1900 960 1342 2211
#> # … with 336,770 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>Eksik değerler her zaman en sonda sıralanır:
df <- tibble(x = c(5, 2, NA))
arrange(df, x)
#> # A tibble: 3 × 1
#> x
#> <dbl>
#> 1 2
#> 2 5
#> 3 NA
arrange(df, desc(x))
#> # A tibble: 3 × 1
#> x
#> <dbl>
#> 1 5
#> 2 2
#> 3 NA5.3.1 Alıştırmalar
Tüm eksik değerleri başlangıca sıralamak için
arrange()i nasıl kullanabilirsiniz? (İpucu:is.na ()kullanın).flightsı en gecikmeli uçuşları bulmak için sıralayın. En erken kalan uçuşları bulun.En hızlı uçuşları bulmak için
flightssıralayın.Hangi uçuşlar en uzun seyahat etmiştir? Hangileri en kısa seyahat etmiştir?
5.4 select() ile sütunları seçme
Yüzlerce hatta binlerce değişken içeren veri kümeleri elde etmek nadir değildir. Bu durumda, ilk zorluk genellikle değişkenleri ilgilendiklerinize daraltmaktır. select(), değişkenlerin isimlerine dayalı işlemler kullanarak, yararlı bir altkümeye hızlı bir şekilde yakınlaşmanızı sağlar.
select(), flights verisiyle çok kullanışlı değil çünkü yalnızca 19 değişkenimiz var, ancak yine de genel fikri edinebilirsiniz:
# İsimle sütunları seçin
select(flights, year, month, day)
#> # A tibble: 336,776 × 3
#> year month day
#> <int> <int> <int>
#> 1 2013 1 1
#> 2 2013 1 1
#> 3 2013 1 1
#> 4 2013 1 1
#> 5 2013 1 1
#> 6 2013 1 1
#> # … with 336,770 more rows
# Yıldan güne kadar (dahil) tüm sütunları seçin
select(flights, year:day)
#> # A tibble: 336,776 × 3
#> year month day
#> <int> <int> <int>
#> 1 2013 1 1
#> 2 2013 1 1
#> 3 2013 1 1
#> 4 2013 1 1
#> 5 2013 1 1
#> 6 2013 1 1
#> # … with 336,770 more rows
# Yıldan güne kadar (dahil) olanlar hariç sütunları seçin
select(flights, -(year:day))
#> # A tibble: 336,776 × 16
#> dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay carrier
#> <int> <int> <dbl> <int> <int> <dbl> <chr>
#> 1 517 515 2 830 819 11 UA
#> 2 533 529 4 850 830 20 UA
#> 3 542 540 2 923 850 33 AA
#> 4 544 545 -1 1004 1022 -18 B6
#> 5 554 600 -6 812 837 -25 DL
#> 6 554 558 -4 740 728 12 UA
#> # … with 336,770 more rows, and 9 more variables: flight <int>, tailnum <chr>,
#> # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
#> # minute <dbl>, time_hour <dttm>select() içinde kullanabileceğiniz bir dizi yardımcı fonksiyon vardır:
starts_with("abc"): “abc” ile başlayan isimlerle eşleşir.ends_with("xyz"): “xyz” ile biten isimlerle eşleşir.contains("ijk"): “ijk” içeren isimlerle eşleşir.matches("(.)\\1"): kurallı ifadelerle (regular expression) eşleşen değişkenleri seçer. Bu, tekrarlanan karakterler içeren değişkenlerle eşleşir. dizgeler bölümünde düzenli ifadeler hakkında daha fazla bilgi edineceksiniz.num_range("x", 1:3):x1,x2vex3ile eşleşir.
Detaylar için ?selecte bakın.
select() değişkenleri yeniden isimlendirmek için kullanılabilir, ancak açıkça belirtilmeyen tüm değişkenleri dışarıda bıraktığı için nadiren kullanışlıdır. Bunun yerine, açıkça belirtilmeyen tüm değişkenleri koruyan select()in bir varyantı olan rename()i kullanın:
rename(flights, tail_num = tailnum)
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # … with 336,770 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tail_num <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>Bir diğer seçenek de everything() yardımcısı ile select()i kullanmaktır. Bu, veri tablosunun başlangıcına taşımak istediğiniz birkaç değişkeniniz olduğunda kullanışlıdır.
select(flights, time_hour, air_time, everything())
#> # A tibble: 336,776 × 19
#> time_hour air_time year month day dep_time sched_dep_time
#> <dttm> <dbl> <int> <int> <int> <int> <int>
#> 1 2013-01-01 05:00:00 227 2013 1 1 517 515
#> 2 2013-01-01 05:00:00 227 2013 1 1 533 529
#> 3 2013-01-01 05:00:00 160 2013 1 1 542 540
#> 4 2013-01-01 05:00:00 183 2013 1 1 544 545
#> 5 2013-01-01 06:00:00 116 2013 1 1 554 600
#> 6 2013-01-01 05:00:00 150 2013 1 1 554 558
#> # … with 336,770 more rows, and 12 more variables: dep_delay <dbl>,
#> # arr_time <int>, sched_arr_time <int>, arr_delay <dbl>, carrier <chr>,
#> # flight <int>, tailnum <chr>, origin <chr>, dest <chr>, distance <dbl>,
#> # hour <dbl>, minute <dbl>5.4.1 Alıştırmalar
flightstandep_time,dep_delay,arr_time, vearr_delayi seçmek için mümkün yolları bulmak için beyin fırtınası yapın.Bir değişkenin adını bir
select()çağrısında birden çok kez eklerseniz ne olur?one_of()işlevi ne yapar? Bu vektörle birlikte yardımcı olma sebebi ne olabilir?vars <- c("year", "month", "day", "dep_delay", "arr_delay")Aşağıdaki kodu çalıştırmanın sonucu sizi şaşırtıyor mu? Seçme yardımcıları varsayılan olarak büyük-küçük harf ile nasıl ilgilenir? Bu varsayılanı nasıl değiştirebilirsiniz?
select(flights, contains("TIME"))
5.5 mutate() ile yeni değişkenler ekleme
Mevcut sütun kümelerini seçmenin yanı sıra, mevcut sütunların işlevleri olan yeni sütunlar eklemek genellikle yararlıdır. Bu mutate() işidir.
mutate() yeni sütunları her zaman veri setinizin sonuna ekler. Bu yüzden yeni değişkenleri görebilmemiz için daha dar bir veri seti oluşturarak başlayacağız. RStudio’dayken, tüm sütunları görmenin en kolay yolunun View() olduğunu unutmayın.
flights_sml <- select(flights,
year:day,
ends_with("delay"),
distance,
air_time
)
mutate(flights_sml,
gain = dep_delay - arr_delay,
speed = distance / air_time * 60
)
#> # A tibble: 336,776 × 9
#> year month day dep_delay arr_delay distance air_time gain speed
#> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 2013 1 1 2 11 1400 227 -9 370.
#> 2 2013 1 1 4 20 1416 227 -16 374.
#> 3 2013 1 1 2 33 1089 160 -31 408.
#> 4 2013 1 1 -1 -18 1576 183 17 517.
#> 5 2013 1 1 -6 -25 762 116 19 394.
#> 6 2013 1 1 -4 12 719 150 -16 288.
#> # … with 336,770 more rowsYeni oluşturduğunuz sütunları kullanabileceğinizi unutmayın:
mutate(flights_sml,
gain = dep_delay - arr_delay,
hours = air_time / 60,
gain_per_hour = gain / hours
)
#> # A tibble: 336,776 × 10
#> year month day dep_delay arr_delay distance air_time gain hours
#> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 2013 1 1 2 11 1400 227 -9 3.78
#> 2 2013 1 1 4 20 1416 227 -16 3.78
#> 3 2013 1 1 2 33 1089 160 -31 2.67
#> 4 2013 1 1 -1 -18 1576 183 17 3.05
#> 5 2013 1 1 -6 -25 762 116 19 1.93
#> 6 2013 1 1 -4 12 719 150 -16 2.5
#> # … with 336,770 more rows, and 1 more variable: gain_per_hour <dbl>Yalnızca yeni değişkenleri korumak istiyorsanız, transmute() kullanın:
transmute(flights,
gain = dep_delay - arr_delay,
hours = air_time / 60,
gain_per_hour = gain / hours
)
#> # A tibble: 336,776 × 3
#> gain hours gain_per_hour
#> <dbl> <dbl> <dbl>
#> 1 -9 3.78 -2.38
#> 2 -16 3.78 -4.23
#> 3 -31 2.67 -11.6
#> 4 17 3.05 5.57
#> 5 19 1.93 9.83
#> 6 -16 2.5 -6.4
#> # … with 336,770 more rows5.5.1 Yararlı oluşturma fonksiyonları
Yeni değişkenler oluşturmak için mutate() ile kullanabileceğiniz birçok fonksiyon vardır. Anahtar özelliği, fonksiyonun vektörleştirilmesi gerektiğidir: girdi olarak bir değerler vektörü almalı, çıktı ile aynı sayıda değere sahip bir vektör oluşturmalıdır. Kullanabileceğiniz her olası fonksiyonu listelemek mümkün değil, ancak burada sık kullanılan fonksiyonların bir seçimi vardır:
Aritmetik operatörler:
+,-,*,/,^. Bunların hepsi “geri dönüşüm kuralları” kullanılarak vektörleştirilmiştir. Bir parametre diğerinden daha kısaysa, otomatik olarak aynı uzunlukta olacak şekilde genişletilir. Bu, bağımsız değişkenlerden biri tek bir sayı olduğunda yararlıdır:air_time / 60,hours * 60 + minute, etc.Aritmetik işleçler, daha sonra öğreneceğiniz yığın fonksiyonlarıyla birlikte de yararlıdır. Örneğin,
x / sum(x)toplamın oranını hesaplar vey - mean(y)ortalamadan farkı hesaplar.Modüler aritmetik:
x == y * (x %/% y) + (x %% y)ifadesinde%/%(tamsayı bölümü) and%%(kalan). Modüler aritmetik kullanışlı bir araçtır, çünkü tam sayıları parçalara ayırmanıza izin verir. Örneğin,flightsverisetindedep_timedanhour(saat) veminute(dakika) hesaplayabilirsiniz:transmute(flights, dep_time, hour = dep_time %/% 100, minute = dep_time %% 100 ) #> # A tibble: 336,776 × 3 #> dep_time hour minute #> <int> <dbl> <dbl> #> 1 517 5 17 #> 2 533 5 33 #> 3 542 5 42 #> 4 544 5 44 #> 5 554 5 54 #> 6 554 5 54 #> # … with 336,770 more rowsLogaritmalar:
log(),log2(),log10(). Logaritmalar, birden fazla büyüklük aralığında değişen verilerle uğraşmak için inanılmaz derecede faydalı bir dönüşümdür. Ayrıca, modellemede geri döneceğimiz bir özellik olan çarpımsal ilişkileri toplamlara dönüştürüyorlar.Diğer her şey sabit olduğunda,
log2()kullanımını öneririm çünkü yorumlaması kolaydır: logaritmik ölçekteki 1lik bir fark orjinal ölçekte iki kat almaya denk gelir ve -1 yarıya inmeye denk gelir.Kaydırmalar:
lead()velag()önde gelen veya geciken değerleri kullanmanıza olanak tanır. Bu vektörlerdeki ardaşık değerler arasındaki farkları hesaplamanıza (örn.x - lag(x)) ya da değerlerin ne zaman değiştiğini bulmanıza (x != lag(x)) olanak tanır. Kısa sürede öğreneceğinizgroup_by()ile birlikte kullanıldıklarında en yararlıdırlar.(x <- 1:10) #> [1] 1 2 3 4 5 6 7 8 9 10 lag(x) #> [1] NA 1 2 3 4 5 6 7 8 9 lead(x) #> [1] 2 3 4 5 6 7 8 9 10 NAKümülatif ve yuvarlanan yığınlar: R, kümülatif toplamlar, çarpımlar, minimum ve maksimumlar için fonksiyonlar sağlar:
cumsum(),cumprod(),cummin(),cummax(); ve dplyr birikimli ortalama içincummean()fonksiyonunu sağlar. Yuvarlanan birleştirmelere (yani, yuvarlanan bir pencerede hesaplanan bir fomksiyon) ihtiyacınız varsa, RcppRoll paketini deneyin.x #> [1] 1 2 3 4 5 6 7 8 9 10 cumsum(x) #> [1] 1 3 6 10 15 21 28 36 45 55 cummean(x) #> [1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5Daha önceden öğrendiğiniz mantıksal karşılaştırmalar,
<,<=,>,>=,!=, ve==. Karmaşık bir mantıksal işlem dizisi yapıyorsanız, ara değerlerin yeni değişkenlerde saklanması genellikle iyi bir fikirdir, böylece her adımın beklendiği gibi çalışıp çalışmadığını kontrol edebilirsiniz.Sıralama: birden fazla sıralama fonksiyonu vardır, ancak
min_rank()ile başlamalısınız. En genel sıralama türünü yapar (örneğin 1., 2., 2., 4.). Varsayılan olarak en küçük değerlere küçük sıralar verir; en büyük değerlere en küçük değerleri vermek içindesc(x)kullanın.y <- c(1, 2, 2, NA, 3, 4) min_rank(y) #> [1] 1 2 2 NA 4 5 min_rank(desc(y)) #> [1] 5 3 3 NA 2 1
Eğer min_rank() ihtiyacınız olanı yapmazsa, varyantları olan row_number(), dense_rank(), percent_rank(), cume_dist(), ntile()a bakın. Detaylar için yardım sayfalarına bakın.
```r
row_number(y)
#> [1] 1 2 3 NA 4 5
dense_rank(y)
#> [1] 1 2 2 NA 3 4
percent_rank(y)
#> [1] 0.00 0.25 0.25 NA 0.75 1.00
cume_dist(y)
#> [1] 0.2 0.6 0.6 NA 0.8 1.0
```5.5.2 Alıştırmalar
Şu anda
dep_timevesched_dep_timedeğerlerine bakmak uygundur, ancak gerçekten sürekli sayılar olmadıkları için hesaplama için kullanılması zordur. Gece yarısından bu yana geçen dakikaya karşılık gelecek daha uygun bir gösterimine dönüştürün.air_timeıarr_time - dep_timeile karşılaştırın. Ne görmeyi umuyorsununz? Ne görüyorsunuz? Düzeltmek için ne yapmanız gerekiyor?dep_time,sched_dep_time, vedep_delayı karşılaştırın. Bu üç sayının birbiriyle nasıl ilişkili olmasını beklersiniz?Bir sıralama fonksiyonu kullanarak en çok geciken 10 uçuşu bulun. Aynı değeri olanları nasıl ele almak istiyorsun?
min_rank()dökümantasyonunu dikkatlice okuyun.1:3 + 1:10ne sonuç verir? neden?R hangi trigonometrik fonksiyonları sağlar?
5.6 summarise() ile gruplandırılmış özetler
Son anahtar fiil summarise(). Bir veri tablosunu tek bir satıra daraltır:
summarise(flights, delay = mean(dep_delay, na.rm = TRUE))
#> # A tibble: 1 × 1
#> delay
#> <dbl>
#> 1 12.6(na.rm = TRUE ifadesinin ne anlama geldiğine çok kısa sürede geri döneceğiz.)
summarise(), group_by() ile eşleştirmediğimiz sürece çok yararlı değildir. Bu, analiz birimini tüm verisetinden tek tek gruplara değiştirir. Ardından, gruplanmış bir veri tablosunda dplyr fiillerini kullandığınızda, bunlar otomatik olarak “gruba göre” uygulanır. Örneğin, tarihe göre gruplandırılmış bir veri tablosuna aynı kodu uygularsak, tarih başına ortalama gecikmeyi alırız:
by_day <- group_by(flights, year, month, day)
summarise(by_day, delay = mean(dep_delay, na.rm = TRUE))
#> `summarise()` has grouped output by 'year', 'month'. You can override using the
#> `.groups` argument.
#> # A tibble: 365 × 4
#> # Groups: year, month [12]
#> year month day delay
#> <int> <int> <int> <dbl>
#> 1 2013 1 1 11.5
#> 2 2013 1 2 13.9
#> 3 2013 1 3 11.0
#> 4 2013 1 4 8.95
#> 5 2013 1 5 5.73
#> 6 2013 1 6 7.15
#> # … with 359 more rowsgroup_by() ve summarise() birlikte, dplyr ile çalışırken en sık kullanacağınız araçlardan birini sağlar: gruplandırılmış özetler. Ancak bu konuda daha ileri gitmeden önce, güçlü yeni bir fikir sunmamız gerekiyor: pipe operatörü.
5.6.1 Pipe ile birden fazla işlemi birleştirmek
Her bir konum için mesafe ve ortalama gecikme arasındaki ilişkiyi keşfetmek istediğimizi düşünün. dplyrda bildiklerinizi kullanarak şöyle bir kod yazabilirsiniz:
by_dest <- group_by(flights, dest)
delay <- summarise(by_dest,
count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)
)
delay <- filter(delay, count > 20, dest != "HNL")
# Görünüşe göre gecikmeler ~ 750 mil mesafeye kadar artıyor ve
# sonra azalıyor. Belki uçuşlar uzadıkça havada gecikmeleri
# telafi etme yeteneği daha fazladır?
ggplot(data = delay, mapping = aes(x = dist, y = delay)) +
geom_point(aes(size = count), alpha = 1/3) +
geom_smooth(se = FALSE)
#> `geom_smooth()` using method = 'loess' and formula 'y ~ x'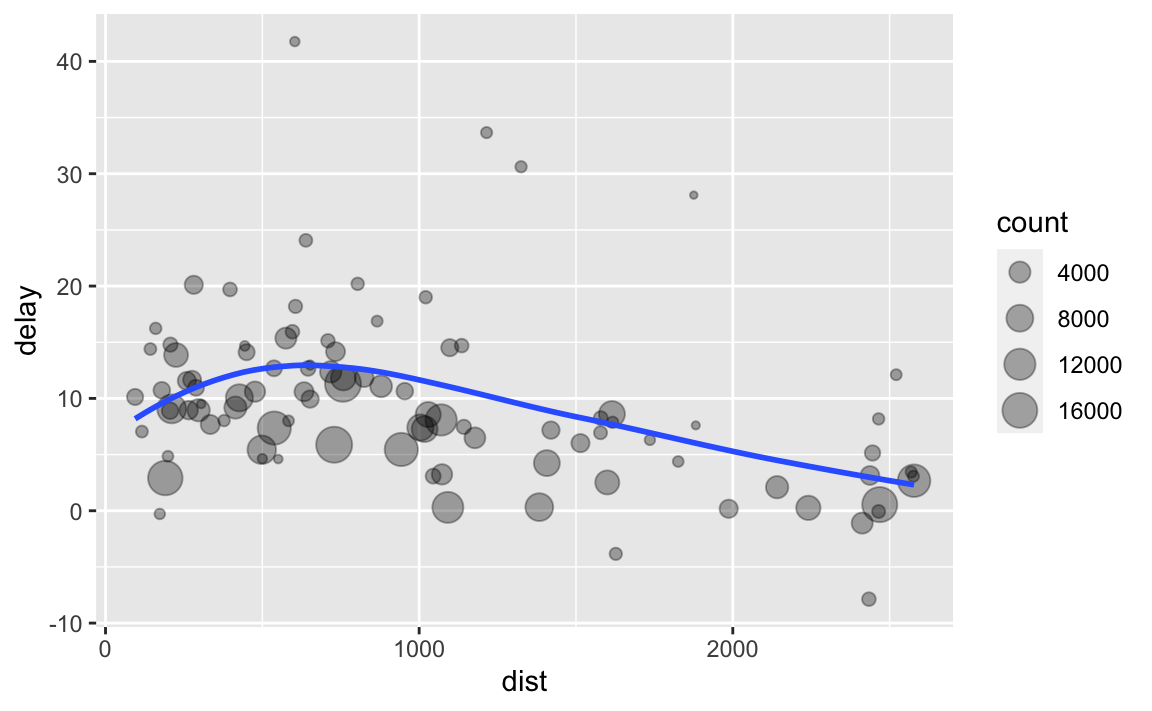
Bu verileri hazırlamak için üç adım vardır:
Uçuşları varış noktasına göre gruplandırın.
Mesafe, ortalama gecikme ve uçuş sayısını hesaplamak için özetleyin.
Gürültülü noktaları ve bir sonraki en yakın havaalanına neredeyse iki kat daha uzak olan Honolulu havaalanını kaldırmak için filtreleyin.
Bu kodun yazılması biraz sinir bozucu, çünkü umursamasak da her ara veri tablosuna bir isim vermemiz gerekiyor. Bir şeyleri isimlendirmek zor, bu da analizlerimizi yavaşlatıyor.
Pipe operatörü (%>%) ile aynı problemi çözmenin başka bir yolu var:
delays <- flights %>%
group_by(dest) %>%
summarise(
count = n(),
dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)
) %>%
filter(count > 20, dest != "HNL")Bu dönüştürülene değil dönüşümlere odaklanarak kodun daha kolay okunmasını sağlar. Bunu bir dizi emir kipinde ifade olarak okuyabilirsiniz: gruplandır, sonra özetle, sonra filtrele. Bu okumadan da çıkarıldığı gibi, %>% operatörünü okumanın güzel bir yolu, “sonra”dır.
Arkaplanda x %>% f(y) ifadesi f(x, y)a, x %>% f(y) %>% g(z) ifadesi g(f(x, y), z)a dönüşür ve bunun gibi devam eder. Pipe operatörünü birçok işlemi soldan sağa okuyacağınız şekilde yukarıdan aşağıya yazabilirsiniz. Bundan sonra pipe operatörlerini sık sık kullanacağız, çünkü kodun okunabilirliğini önemli ölçüde artırıyor ve [pipes]’da daha ayrıntılı olarak buna geri döneceğiz.
Pipe operatörü ile çalışmak tidyverse’e aitlik için anahtar kriterlerden biridir. Tek istisna ggplot2’dir: çünkü pipe operatörünün keşfinden önce yazılmıştı. Ne yazık ki, ggplot2 nin bir sonraki sürümü olan ve pipe operatörünü kullanan ggvis henüz başlatılmaya hazır değil.
5.6.2 Eksik değerler
Yukarıda kullandığımız na.rm argümanını merak etmiş olabilirsiniz. Onu kullanmazsak ne olur?
flights %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay))
#> `summarise()` has grouped output by 'year', 'month'. You can override using the
#> `.groups` argument.
#> # A tibble: 365 × 4
#> # Groups: year, month [12]
#> year month day mean
#> <int> <int> <int> <dbl>
#> 1 2013 1 1 NA
#> 2 2013 1 2 NA
#> 3 2013 1 3 NA
#> 4 2013 1 4 NA
#> 5 2013 1 5 NA
#> 6 2013 1 6 NA
#> # … with 359 more rowsÇok fazla sayıda eksik değer alırız! Bunun sebebi yığın fonksiyonlarının eksik değerlerin genel kuralına uymasıdır: eğer girdide eksik değer varsa, çıktı da eksik değer olur. Şanslıyız ki, tüm birleştirme fonksiyonları hesaplamadan önce eksik değerleri eleyen na.rm argümanına sahiptir.
flights %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay, na.rm = TRUE))
#> `summarise()` has grouped output by 'year', 'month'. You can override using the
#> `.groups` argument.
#> # A tibble: 365 × 4
#> # Groups: year, month [12]
#> year month day mean
#> <int> <int> <int> <dbl>
#> 1 2013 1 1 11.5
#> 2 2013 1 2 13.9
#> 3 2013 1 3 11.0
#> 4 2013 1 4 8.95
#> 5 2013 1 5 5.73
#> 6 2013 1 6 7.15
#> # … with 359 more rowsEksik değerlerin iptal edilen uçuşları temsil ettiği bu durumda, öncelikle iptal edilen uçuşları kaldırarak da sorunu çözebiliriz. Bu veri setini sonraki birkaç örnekte tekrar kullanabilmek için kaydedeceğiz.
not_cancelled <- flights %>%
filter(!is.na(dep_delay), !is.na(arr_delay))
not_cancelled %>%
group_by(year, month, day) %>%
summarise(mean = mean(dep_delay))
#> `summarise()` has grouped output by 'year', 'month'. You can override using the
#> `.groups` argument.
#> # A tibble: 365 × 4
#> # Groups: year, month [12]
#> year month day mean
#> <int> <int> <int> <dbl>
#> 1 2013 1 1 11.4
#> 2 2013 1 2 13.7
#> 3 2013 1 3 10.9
#> 4 2013 1 4 8.97
#> 5 2013 1 5 5.73
#> 6 2013 1 6 7.15
#> # … with 359 more rows5.6.3 Sayımlar
Herhangi bir yığın işlemi yaptığınızda, bir sayım (n()) veya eksik olmayan değerlerin sayımını (sum(!is.na(x))) eklemek her zaman iyi bir fikirdir. Bu şekilde, çok az miktarda verilere dayanarak sonuç çıkarmadığınızı kontrol edebilirsiniz. Örneğin, en yüksek ortalama gecikmelere sahip olan uçaklara (kuyruk numaralarıyla tanımlanan) bakalım:
delays <- not_cancelled %>%
group_by(tailnum) %>%
summarise(
delay = mean(arr_delay)
)
ggplot(data = delays, mapping = aes(x = delay)) +
geom_freqpoly(binwidth = 10)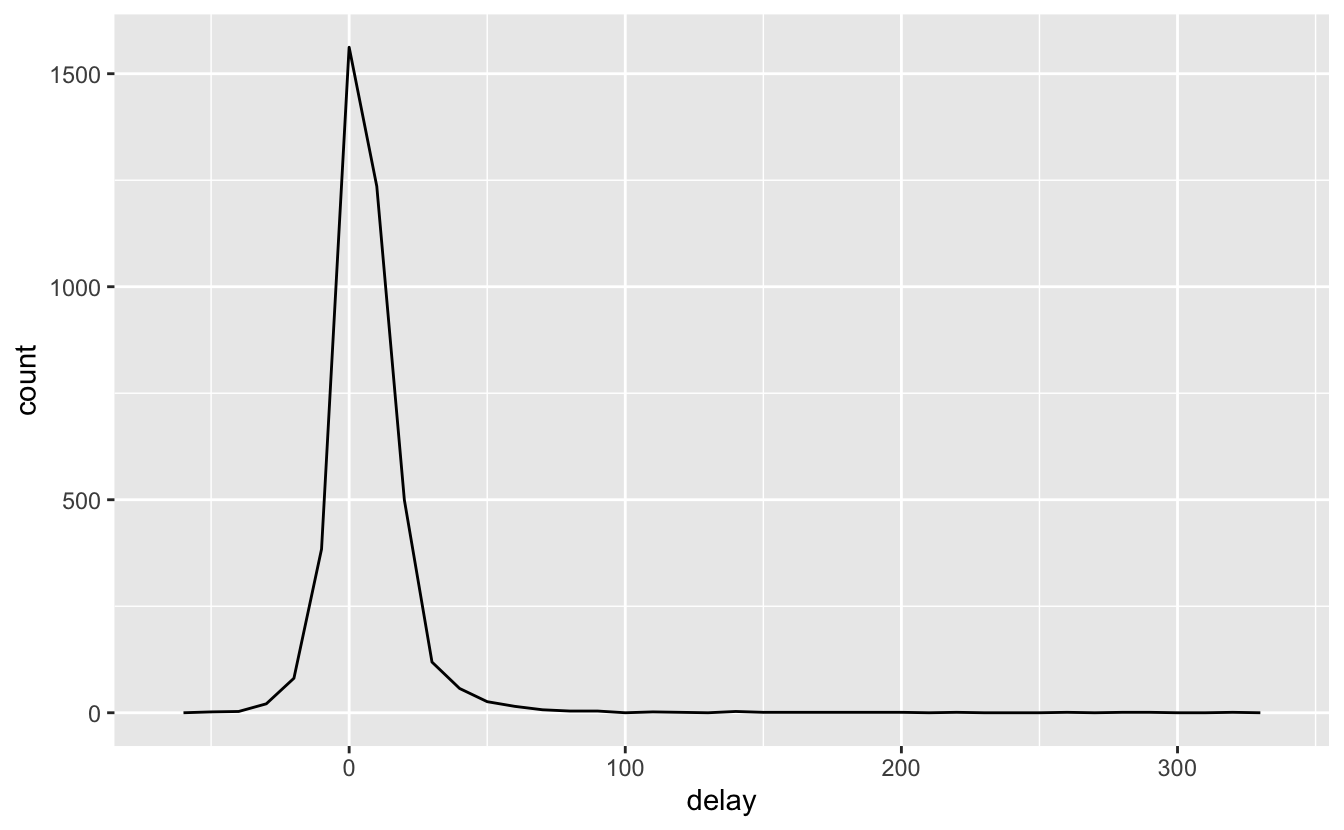
Vay be, ortalama gecikmesi 5 saat (300 dakika) olan uçaklar var!
Hikayede aslında biraz daha nüans var. Ortalama gecikmeye karşı uçuş sayısının dağılım grafiğini çizersek daha fazla bilgi edinebiliriz:
delays <- not_cancelled %>%
group_by(tailnum) %>%
summarise(
delay = mean(arr_delay, na.rm = TRUE),
n = n()
)
ggplot(data = delays, mapping = aes(x = n, y = delay)) +
geom_point(alpha = 1/10)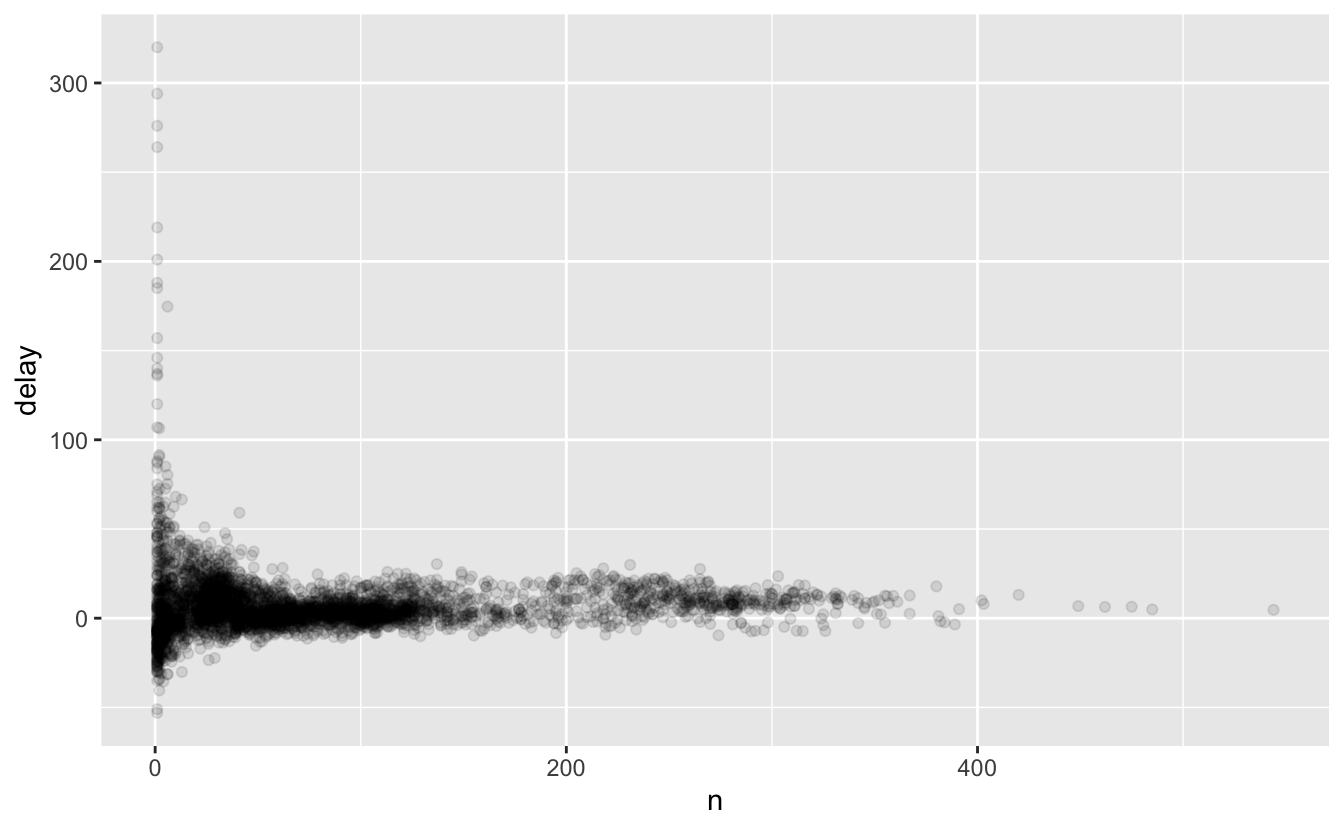
Şaşırtıcı olmayan bir şekilde, az sayıda uçuş olduğunda ortalama gecikmede çok daha fazla değişiklik var. Bu grafiğin şekli çok karakteristiktir: ortalamayı (veya başka bir özeti) grup boyutuna karşı çizdiğinizde, örnek boyutu arttıkça varyasyonun azaldığını görürsünüz.
Bu tür bir figüre bakarken, en az sayıda gözlem içeren grupları filtrelemek genellikle yararlıdır, böylece en küçük gruplarda daha fazla örüntü ve daha az ekstrem varyasyon görebilirsiniz. Aşağıdaki kod ggplot2 ve dplyr akışını entegre etmek için kullanışlı bir örüntü göstermenin yanı sıra bunu gerçekleştirir. %>%dan +ya geçiş biraz acı verici, ancak bir kez kavradıktan sonra oldukça uygun.
delays %>%
filter(n > 25) %>%
ggplot(mapping = aes(x = n, y = delay)) +
geom_point(alpha = 1/10)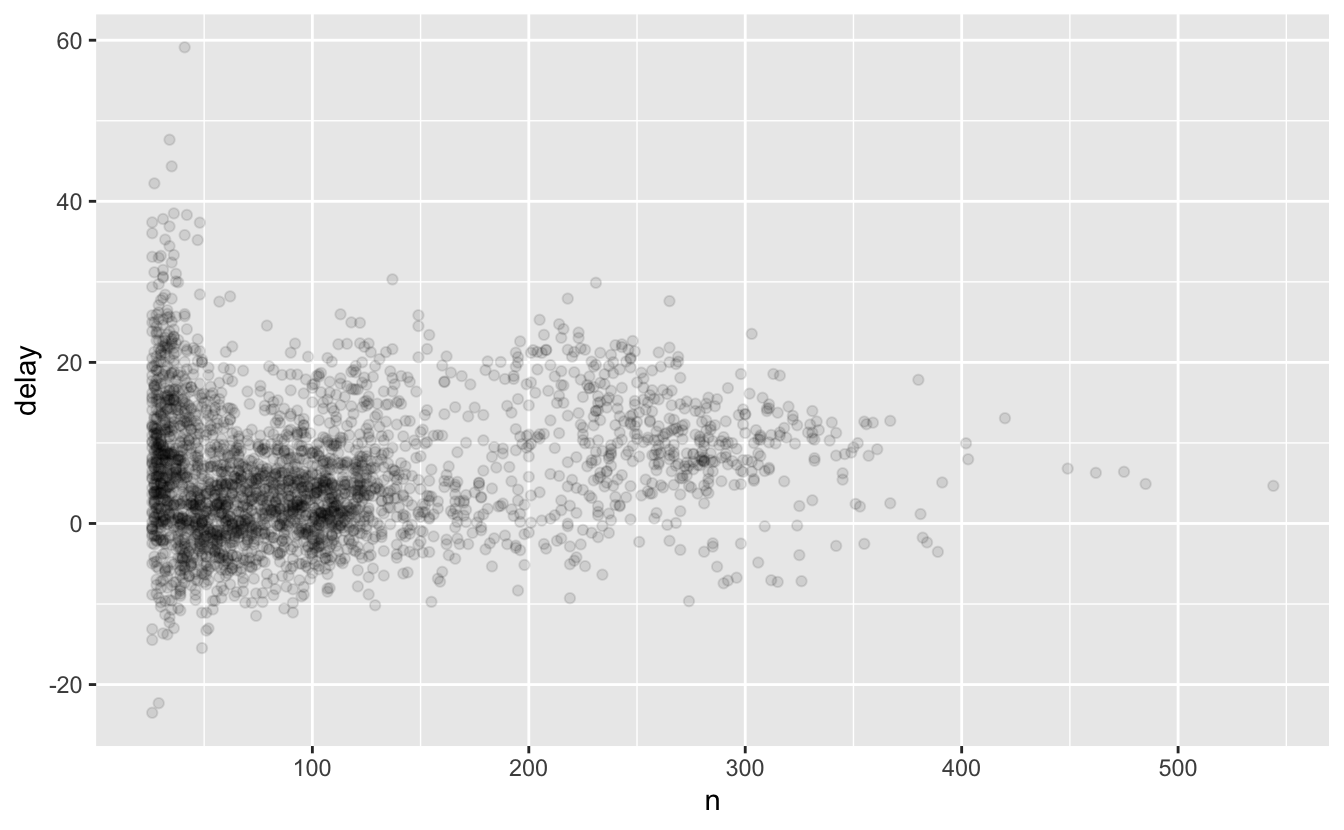
RStudio püf noktası: kullanışlı bir klavye kısayolu Cmd / Ctrl + Shift + P’dir. Bu, önceden gönderilen parçayı düzenleyiciden konsola yeniden gönderir. Yukarıdaki örnekte n değerini incelediğinizde (örneğin) çok kullanışlıdır. Tüm bloğu bir kez Cmd / Ctrl + Enter ile gönderebilir, ardından n değerini değiştirip ve tüm bloğu yeniden göndermek için Cmd / Ctrl + Shift + P tuşlarına basabilirsiniz.
Bu tip örüntünün bir çeşidi daha var. Beyzboldaki vurucuların ortalama performansının vuruş sayısı ile nasıl ilişkili olduğuna bakalım. Burada her ana lig beyzbol oyuncusunun vuruş ortalamasını (isabet sayısı / deneme sayısı) hesaplamak için lahman paketindeki verileri kullanıyorum.
Vurucu yeteneğini (vuruş ortalaması,ba ile ölçülen) topa vurmak için yakalanan fırsat sayısına (vuruş sayısı, ab ile ölçülen) göre çizdiğimde, iki desen görürsünüz:
Yukarıdaki gibi, daha fazla veri noktası elde ettikçe yığın işlemindeki değişiklik azalır.
Beceri (
ba) ve topa vurma fırsatları (ab) arasında pozitif korelasyon vardır. Bunun sebebi takımların kimin oynayacağını kontrol etmesi ve belli ki en iyi oyuncularını seçmeleridir.
# Tibble'a çevirin ki güzel yazdırılsın
batting <- as_tibble(Lahman::Batting)
batters <- batting %>%
group_by(playerID) %>%
summarise(
ba = sum(H, na.rm = TRUE) / sum(AB, na.rm = TRUE),
ab = sum(AB, na.rm = TRUE)
)
batters %>%
filter(ab > 100) %>%
ggplot(mapping = aes(x = ab, y = ba)) +
geom_point() +
geom_smooth(se = FALSE)
#> `geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'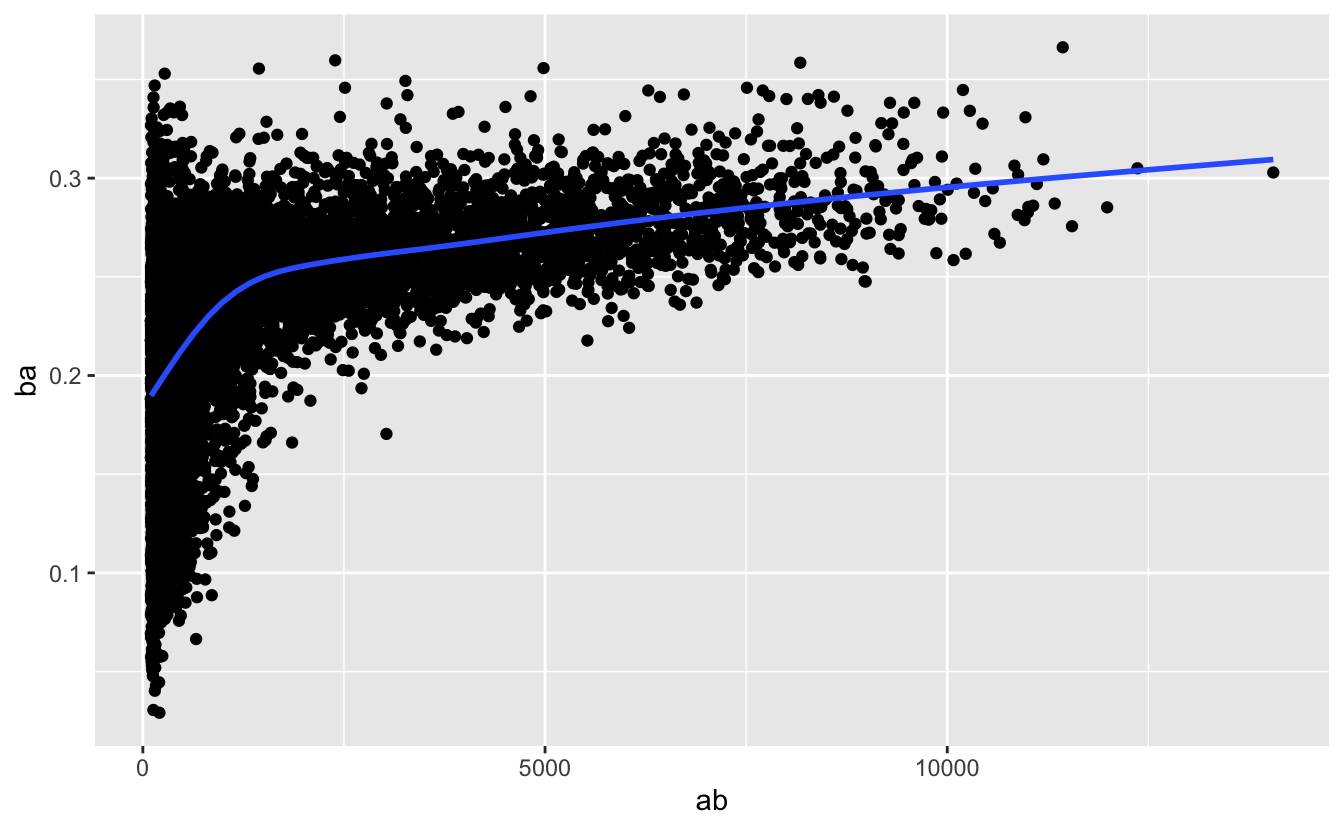
Bunun sıralama için de önemli etkileri vardır. Naif bir şekilde azalan beceriye (desc(ba)) göre sıralarsanız, en iyi vuruş ortalamalarına sahip insanlar açıkça şanslıdır, yetenekli değildir:
batters %>%
arrange(desc(ba))
#> # A tibble: 20,166 × 3
#> playerID ba ab
#> <chr> <dbl> <int>
#> 1 abramge01 1 1
#> 2 alberan01 1 1
#> 3 banisje01 1 1
#> 4 bartocl01 1 1
#> 5 bassdo01 1 1
#> 6 birasst01 1 2
#> # … with 20,160 more rowsBu problemin güzel bir açıklamasını http://varianceexplained.org/r/empirical_bayes_baseball/ ve http://www.evanmiller.org/how-not-to-sort-by-average-rating.html adreslerinde bulabilirsiniz.
5.6.4 Yararlı özet fonksiyonları
Sadece ortalamaları, sayımları ve toplamı kullanmak yol katetmenizi sağlayabilir, ancak R diğer birçok yararlı özet fonksiyonu sağlar:
Konum ölçüleri:
mean(x)kullandık, amamedian(x)da yararlıdır. Ortalama (mean) toplamın uzunluğa (length) bölümüdür; medyan (median) isexdeğerlerinin %50sinin daha yüksek, %50sininse daha düşük olduğu değerdir.Bazen, yığın işlemlerini mantıksal altkümeleme işlemleri ile kullanmak yararlıdır. Bu çeşit kümelemeden henüz bahsetmedik, ancak [altkümeleme]de daha fazlasını öğreneceksiniz.
not_cancelled %>% group_by(year, month, day) %>% summarise( avg_delay1 = mean(arr_delay), avg_delay2 = mean(arr_delay[arr_delay > 0]) # the average positive delay ) #> `summarise()` has grouped output by 'year', 'month'. You can override using the #> `.groups` argument. #> # A tibble: 365 × 5 #> # Groups: year, month [12] #> year month day avg_delay1 avg_delay2 #> <int> <int> <int> <dbl> <dbl> #> 1 2013 1 1 12.7 32.5 #> 2 2013 1 2 12.7 32.0 #> 3 2013 1 3 5.73 27.7 #> 4 2013 1 4 -1.93 28.3 #> 5 2013 1 5 -1.53 22.6 #> 6 2013 1 6 4.24 24.4 #> # … with 359 more rowsYayılım ölçüleri:
sd(x),IQR(x),mad(x). Kök-ortalama-kare-sapma, ya da standart sapma,sd(x), yayılımın standart ölçüsüdür. Çeyrekler arası açıklık,IQR(x), ve ortalama mutlak sapma,mad(x), dirençli (robust) eşdeğerlerdir ve uç değerler (outlier) bulunması durumunda daha kullanışlı olabilir.# Neden bazı varış noktalarına olan uzaklık diğerlerinden daha değişken? not_cancelled %>% group_by(dest) %>% summarise(distance_sd = sd(distance)) %>% arrange(desc(distance_sd)) #> # A tibble: 104 × 2 #> dest distance_sd #> <chr> <dbl> #> 1 EGE 10.5 #> 2 SAN 10.4 #> 3 SFO 10.2 #> 4 HNL 10.0 #> 5 SEA 9.98 #> 6 LAS 9.91 #> # … with 98 more rowsSıra ölçüleri:
min(x),quantile(x, 0.25),max(x). Kantiller medyanın genelleştirilmesidir. Örneğin,quantile(x, 0.25)değerlerin %25inden daha yüksek, %75inden daha düşük olanxdeğerini bulur.# Bir gün içerisinde şlk ve son uçuşlar ne zaman kalkıyor? not_cancelled %>% group_by(year, month, day) %>% summarise( first = min(dep_time), last = max(dep_time) ) #> `summarise()` has grouped output by 'year', 'month'. You can override using the #> `.groups` argument. #> # A tibble: 365 × 5 #> # Groups: year, month [12] #> year month day first last #> <int> <int> <int> <int> <int> #> 1 2013 1 1 517 2356 #> 2 2013 1 2 42 2354 #> 3 2013 1 3 32 2349 #> 4 2013 1 4 25 2358 #> 5 2013 1 5 14 2357 #> 6 2013 1 6 16 2355 #> # … with 359 more rowsPozisyon ölçüleri:
first(x),nth(x, 2),last(x). Bunlarx[1],x[2], vex[length(x)]e benzer çalışır, ancak eğer o pozisyon mevcut değilse varsayılan bir değer belirlemeyi sağlar (yani 2 elemanı bulunan bir gruptan 3.elemanı almaya çalışırsanız). Örneğin, her günün ilk ve son kalkışını bulabiliriz:not_cancelled %>% group_by(year, month, day) %>% summarise( first_dep = first(dep_time), last_dep = last(dep_time) ) #> `summarise()` has grouped output by 'year', 'month'. You can override using the #> `.groups` argument. #> # A tibble: 365 × 5 #> # Groups: year, month [12] #> year month day first_dep last_dep #> <int> <int> <int> <int> <int> #> 1 2013 1 1 517 2356 #> 2 2013 1 2 42 2354 #> 3 2013 1 3 32 2349 #> 4 2013 1 4 25 2358 #> 5 2013 1 5 14 2357 #> 6 2013 1 6 16 2355 #> # … with 359 more rowsBu işlevler, sıralamaların filtrelenmesine tamamlayıcı niteliktedir. Filtreleme, tüm gözlemler ayrı bir satırda olacak şekilde tüm değişkenleri verir:
not_cancelled %>% group_by(year, month, day) %>% mutate(r = min_rank(desc(dep_time))) %>% filter(r %in% range(r)) #> # A tibble: 770 × 20 #> # Groups: year, month, day [365] #> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time #> <int> <int> <int> <int> <int> <dbl> <int> <int> #> 1 2013 1 1 517 515 2 830 819 #> 2 2013 1 1 2356 2359 -3 425 437 #> 3 2013 1 2 42 2359 43 518 442 #> 4 2013 1 2 2354 2359 -5 413 437 #> 5 2013 1 3 32 2359 33 504 442 #> 6 2013 1 3 2349 2359 -10 434 445 #> # … with 764 more rows, and 12 more variables: arr_delay <dbl>, carrier <chr>, #> # flight <int>, tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, #> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, r <int>Sayımlar: Argüman almayan grubun büyüklüğünü veren
n()i daha önceden gördünüz. Eksik olmayan değerlerin sayımı için,sum(!is.na(x))kullanın. Birbirinden farklı (biricik) değerlerin sayısı için,n_distinct(x)kullanın.# Hangi rota en çok taşıyıcıya sahip? not_cancelled %>% group_by(dest) %>% summarise(carriers = n_distinct(carrier)) %>% arrange(desc(carriers)) #> # A tibble: 104 × 2 #> dest carriers #> <chr> <int> #> 1 ATL 7 #> 2 BOS 7 #> 3 CLT 7 #> 4 ORD 7 #> 5 TPA 7 #> 6 AUS 6 #> # … with 98 more rowsSayımlar o kadar kullanışlıdır ki, istediğiniz tek şey bir sayımsa dplyr basit bir yardımcı sağlar:
not_cancelled %>% count(dest) #> # A tibble: 104 × 2 #> dest n #> <chr> <int> #> 1 ABQ 254 #> 2 ACK 264 #> 3 ALB 418 #> 4 ANC 8 #> 5 ATL 16837 #> 6 AUS 2411 #> # … with 98 more rowsİsteğe bağlı olarak bir ağırlık değişkeni sağlayabilirsiniz. Örneğin, bunu bir uçağın uçtuğu toplam mil sayısını “saymak” (toplamak) için kullanabilirsiniz:
not_cancelled %>% count(tailnum, wt = distance) #> # A tibble: 4,037 × 2 #> tailnum n #> <chr> <dbl> #> 1 D942DN 3418 #> 2 N0EGMQ 239143 #> 3 N10156 109664 #> 4 N102UW 25722 #> 5 N103US 24619 #> 6 N104UW 24616 #> # … with 4,031 more rowsMantıksal değerlerin sayı ve oranları:
sum(x > 10),mean(y == 0). Numerik fonksiyonlarla birlikte kullanıldığında,TRUE1’e veFALSE0’a dönüştürülür. Bu dasum()vemean()i çok kullanışlı kılar:sum(x)toplamTRUEsayısını, vemean(x)oranını verir.# Sabah 5'ten önce kaç uçuş kalktı? (bunlar genellikle bir önceki günün # gecikmeli uçuşlarını gösterir) not_cancelled %>% group_by(year, month, day) %>% summarise(n_early = sum(dep_time < 500)) #> `summarise()` has grouped output by 'year', 'month'. You can override using the #> `.groups` argument. #> # A tibble: 365 × 4 #> # Groups: year, month [12] #> year month day n_early #> <int> <int> <int> <int> #> 1 2013 1 1 0 #> 2 2013 1 2 3 #> 3 2013 1 3 4 #> 4 2013 1 4 3 #> 5 2013 1 5 3 #> 6 2013 1 6 2 #> # … with 359 more rows # Uçuşların yüzde kaçı bir saatten fazla gecikiyor? not_cancelled %>% group_by(year, month, day) %>% summarise(hour_perc = mean(arr_delay > 60)) #> `summarise()` has grouped output by 'year', 'month'. You can override using the #> `.groups` argument. #> # A tibble: 365 × 4 #> # Groups: year, month [12] #> year month day hour_perc #> <int> <int> <int> <dbl> #> 1 2013 1 1 0.0722 #> 2 2013 1 2 0.0851 #> 3 2013 1 3 0.0567 #> 4 2013 1 4 0.0396 #> 5 2013 1 5 0.0349 #> 6 2013 1 6 0.0470 #> # … with 359 more rows
5.6.5 Birden fazla değişken ile gruplama
Birden çok değişkene göre gruplandırdığınızda, her özet gruplamanın bir düzeyini oluşturur. Bu, bir veri setinin aşamalı olarak toparlanmasını kolaylaştırır:
daily <- group_by(flights, year, month, day)
(per_day <- summarise(daily, flights = n()))
#> `summarise()` has grouped output by 'year', 'month'. You can override using the
#> `.groups` argument.
#> # A tibble: 365 × 4
#> # Groups: year, month [12]
#> year month day flights
#> <int> <int> <int> <int>
#> 1 2013 1 1 842
#> 2 2013 1 2 943
#> 3 2013 1 3 914
#> 4 2013 1 4 915
#> 5 2013 1 5 720
#> 6 2013 1 6 832
#> # … with 359 more rows
(per_month <- summarise(per_day, flights = sum(flights)))
#> `summarise()` has grouped output by 'year'. You can override using the
#> `.groups` argument.
#> # A tibble: 12 × 3
#> # Groups: year [1]
#> year month flights
#> <int> <int> <int>
#> 1 2013 1 27004
#> 2 2013 2 24951
#> 3 2013 3 28834
#> 4 2013 4 28330
#> 5 2013 5 28796
#> 6 2013 6 28243
#> # … with 6 more rows
(per_year <- summarise(per_month, flights = sum(flights)))
#> # A tibble: 1 × 2
#> year flights
#> <int> <int>
#> 1 2013 336776Özetleri aşamalı olarak toplarken dikkatli olun: toplamlar ve sayımlar için sorun değil, ancak ağırlıklı ortalamalar ve varyanslar için düşünmeniz gerekir ve bunu medyan gibi sıra tabanlı istatistikler için tam olarak yapmak mümkün değildir. Başka bir deyişle, grupsal toplamların toplamı genel toplamdır, ancak grupsal medyanların medyanı genel medyan değildir.
5.6.6 Grupların bozulması
Gruplamayı bozmanız ve grupsuz veride işlevler çalıştırmanız gerekirse, ungroup() kullanın.
daily %>%
ungroup() %>% # artık tarihle gruplu değil
summarise(flights = n()) # tüm uçuşlar
#> # A tibble: 1 × 1
#> flights
#> <int>
#> 1 3367765.6.7 Alıştırmalar
Bir grup uçuşun tipik gecikmesini değerlendirmek için en az 5 değişik yöntem bulun. Şu senaryoları düşünün:
Bir uçuş uçuşlarının %50sinde 15 dakika erken, ve %50sinde 15 dakika geç.
Hep 10 dakika geç kalan bir uçuş
Bir uçuş, tüm uçuşlarının %50sinde 30 dakika erken, %50sinde 30 dakika geç.
Uçuşların %99unda zamanında olan, %1inde 2 saat geç kalan bir uçuş.
Hangisi daha önemlidir: varış gecikmesi mi yoksa kalkış gecikmesi mi?
not_cancelled %>% count(dest)venot_cancelled %>% count(tailnum, wt = distance)ile aynı sonucu verecek başka bir yaklaşım bulun (count()kullanmadan).İptal edilen uçuşlar tanımımız (
is.na(dep_delay) | is.na(arr_delay)) biraz standart altı. Neden? En önemli sütun hangisidir?Günlük iptal edilen uçuş sayısına bakın. Bir örüntü var mı? İptal edilen uçuşların oranı ortalama gecikmeyle ilgili mi?
Hangi taşıyıcı en kötü gecikmelere sahip? Meydan okuma: Kötü havaalanı ve kötü taşıyıcı etkisini birbirinden ayırabilir misiniz? Neden? (İpucu:
flights %>% group_by(carrier, dest) %>% summarise(n())düşünün)sortargümanıcount()a ne yapar? Onu ne zaman kullanabilirsiniz?
5.7 Gruplanmış mutasyon (ve filtreler)
Gruplandırma en çok summarise() ile birlikte kullanıldığında kullanışlıdır, ancak mutate() ve filter() ile uygun işlemler yapabilirsiniz.
Her grubun en kötü üyelerini bulun:
flights_sml %>% group_by(year, month, day) %>% filter(rank(desc(arr_delay)) < 10) #> # A tibble: 3,306 × 7 #> # Groups: year, month, day [365] #> year month day dep_delay arr_delay distance air_time #> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> #> 1 2013 1 1 853 851 184 41 #> 2 2013 1 1 290 338 1134 213 #> 3 2013 1 1 260 263 266 46 #> 4 2013 1 1 157 174 213 60 #> 5 2013 1 1 216 222 708 121 #> 6 2013 1 1 255 250 589 115 #> # … with 3,300 more rowsBir eşikten büyük tüm grupları bulun:
popular_dests <- flights %>% group_by(dest) %>% filter(n() > 365) popular_dests #> # A tibble: 332,577 × 19 #> # Groups: dest [77] #> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time #> <int> <int> <int> <int> <int> <dbl> <int> <int> #> 1 2013 1 1 517 515 2 830 819 #> 2 2013 1 1 533 529 4 850 830 #> 3 2013 1 1 542 540 2 923 850 #> 4 2013 1 1 544 545 -1 1004 1022 #> 5 2013 1 1 554 600 -6 812 837 #> 6 2013 1 1 554 558 -4 740 728 #> # … with 332,571 more rows, and 11 more variables: arr_delay <dbl>, #> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>, #> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>Grup başına ölçümleri hesaplamak için standart hale getirin:
popular_dests %>% filter(arr_delay > 0) %>% mutate(prop_delay = arr_delay / sum(arr_delay)) %>% select(year:day, dest, arr_delay, prop_delay) #> # A tibble: 131,106 × 6 #> # Groups: dest [77] #> year month day dest arr_delay prop_delay #> <int> <int> <int> <chr> <dbl> <dbl> #> 1 2013 1 1 IAH 11 0.000111 #> 2 2013 1 1 IAH 20 0.000201 #> 3 2013 1 1 MIA 33 0.000235 #> 4 2013 1 1 ORD 12 0.0000424 #> 5 2013 1 1 FLL 19 0.0000938 #> 6 2013 1 1 ORD 8 0.0000283 #> # … with 131,100 more rows
Gruplandırılmış bir filtre, gruplandırılmış bir mutasyon, ardından gruplanmamış bir filtredir. Ben acele ve kötü manipülasyonlar dışında genellikle onlardan kaçınıyorum: aksi takdirde manipülasyonu doğru yaptığınızı kontrol etmek zordur.
Gruplanmış mutasyonlarda ve filtrelerde en doğal şekilde çalışan fonksiyonlar, pencere fonksiyonları olarak bilinir (özetler için kullanılan özet fonksiyonlara karşılık). İlgili vinyette yararlı pencere işlevleri hakkında daha fazla bilgi edinebilirsiniz: vignette("window-functions").
5.7.1 Alıştırmalar
Yararlı mutasyon ve filtreleme işlevleri listelerine bakın. Gruplandırmayla birleştirdiğinizde her işlemin nasıl değiştiğini açıklayın.
Hangi uçak (
tailnum) en kötü zamanında olma kaydına sahip?Gecikmeleri mümkün olduğunca önlemek istiyorsanız günün hangi saatinde uçmalısınız?
Her hedef için toplam gecikme dakikalarını hesaplayın. Her uçuşun varış yeri için toplam gecikme oranını hesaplayın.
Gecikmeler tipik olarak zamansal olarak ilişkilidir: ilk gecikmeye neden olan sorun çözüldüğünde bile, daha erken uçuşların kalkmasına izin vermek için sonraki uçuşlar da gecikir.
lag()kullanarak, bir uçuşun gecikmesinin hemen önceki uçuşun gecikmesiyle nasıl ilişkili olduğunu keşfedin.Her bir hedef yerine bakın. Şüpheli derecede hızlı uçuşlar bulabilir misiniz? (yani, potansiyel bir veri giriş hatasını temsil eden uçuşlar). Uçuş süresini, varış noktasına olan en kısa uçuşa göre hesaplayın. Havada en çok hangi uçuşlar gecikti?
En az iki taşıyıcı tarafından yönlendirilen tüm varış noktalarını bulun. Bu bilgileri operatörleri sıralamak için kullanın.
Her uçak için, 1 saatten daha fazla olan ilk gecikmeden önceki uçuş sayısını hesaplayın.