13 İlişkisel veri
13.1 Giriş
Veri analizinin tek bir veri tablosundan oluştuğu durumlar nadirdir. Genelde birçok veri tablonuz olur ve ilgilendiğiniz soruları cevaplamak için onları birleştirmeniz gerekir. Birçok veri tablosu toplu olarak ilişkisel veri olarak adlandırılır çünkü önemli olan şey veri setleri arasındaki ilişkidir, tekil veri setleri değil.
İlişkiler her zaman bir çift tablo arasında belirlenir. Tüm diğer ilişkiler de bu basit fikirden geliştirilir: üç ya da daha fazla tablonun arasındaki ilişki her zaman her bir çift tablo arasındaki ilişkinin bir özelliğidir. Bazen bir çiftin bütün elemanları aynı tablo olabilir! Örneğin bu, insanlardan oluşan bir tablonuz olduğunda ve her insanın ebeveynlerine referansı olduğunda gereklidir.
İlişkisel veriyle çalışmak için veri çiftleriyle çalışan fiillere ihtiyacınız var. Bunun için tasarlanmış üç fiil ailesi vardır:
Değiştiren birleştirmeler, bir veri tablosundaki eşleşen gözlemlerden bir diğer veri tablosuna yeni değişkenler ekler.
Filtreleyen birleştirmeler, bir veri tablosundaki gözlemleri, öteki veri tablosundaki gözlemle eşleşmesine bağlı olarak filtreler.
Takım operasyonları, gözlemleri takım elemanlarıymış gibi değerlendirir.
İlişkisel veriyle en sık karşılaşılacağınız yer neredeyse bütün güncel veritabanlarını kapsayan bir terim olan ilişkisel veritabanı yönetim sistemidir (relational database management system, RDBMS). Daha önce bir veritabanı kullandıysanız, muhtemelen SQL kullanmışsınızdır. O zaman bu bölümdeki kavramlar, her ne kadar dplyr’daki ifadeleri farklı olsa da size tanıdık gelecektir. Genelde dplyr’ı kullanması SQL’e göre daha kolaydır çünkü dplyr veri analizi yapmak için özelleşmiştir: veri analizinde çoklukla ihtiyaç duyulmayan işlemleri daha zor kılmak pahasına yaygın olan veri analizi işlemlerini kolaylaştırır.
13.2 nycflights13
İlişkisel veriyi öğrenmek için nycflights13 paketini kullanacağız.
nycflights13, veri dönüşümü’nde kullandığınız flights tablosuna bağlı dört tane tibble içerir:
airlineskısaltılmış kodundan tam uçak ismini bulmanızı sağlar:airlines #> # A tibble: 16 × 2 #> carrier name #> <chr> <chr> #> 1 9E Endeavor Air Inc. #> 2 AA American Airlines Inc. #> 3 AS Alaska Airlines Inc. #> 4 B6 JetBlue Airways #> 5 DL Delta Air Lines Inc. #> 6 EV ExpressJet Airlines Inc. #> # … with 10 more rowsairports, her havalimanıyla ilgilifaahavalimanı koduyla tanımlanmış bilgileri verir:airports #> # A tibble: 1,458 × 8 #> faa name lat lon alt tz dst tzone #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr> #> 1 04G Lansdowne Airport 41.1 -80.6 1044 -5 A America/Ne… #> 2 06A Moton Field Municipal Airport 32.5 -85.7 264 -6 A America/Ch… #> 3 06C Schaumburg Regional 42.0 -88.1 801 -6 A America/Ch… #> 4 06N Randall Airport 41.4 -74.4 523 -5 A America/Ne… #> 5 09J Jekyll Island Airport 31.1 -81.4 11 -5 A America/Ne… #> 6 0A9 Elizabethton Municipal Airport 36.4 -82.2 1593 -5 A America/Ne… #> # … with 1,452 more rowsplanes, her uçakla ilgilitailnumkoduyla tanımlanmış bilgileri verir:planes #> # A tibble: 3,322 × 9 #> tailnum year type manufacturer model engines seats speed engine #> <chr> <int> <chr> <chr> <chr> <int> <int> <int> <chr> #> 1 N10156 2004 Fixed wing multi … EMBRAER EMB-… 2 55 NA Turbo… #> 2 N102UW 1998 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo… #> 3 N103US 1999 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo… #> 4 N104UW 1999 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo… #> 5 N10575 2002 Fixed wing multi … EMBRAER EMB-… 2 55 NA Turbo… #> 6 N105UW 1999 Fixed wing multi … AIRBUS INDU… A320… 2 182 NA Turbo… #> # … with 3,316 more rowsweatherNYC havalimanlarına ait saatlik hava durumu bilgisi verir:weather #> # A tibble: 26,115 × 15 #> origin year month day hour temp dewp humid wind_dir wind_speed wind_gust #> <chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> #> 1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4 NA #> 2 EWR 2013 1 1 2 39.0 27.0 61.6 250 8.06 NA #> 3 EWR 2013 1 1 3 39.0 28.0 64.4 240 11.5 NA #> 4 EWR 2013 1 1 4 39.9 28.0 62.2 250 12.7 NA #> 5 EWR 2013 1 1 5 39.0 28.0 64.4 260 12.7 NA #> 6 EWR 2013 1 1 6 37.9 28.0 67.2 240 11.5 NA #> # … with 26,109 more rows, and 4 more variables: precip <dbl>, pressure <dbl>, #> # visib <dbl>, time_hour <dttm>
Farklı tablolar arasındaki ilişkileri göstermenin bir yolu da çizimlerdir:
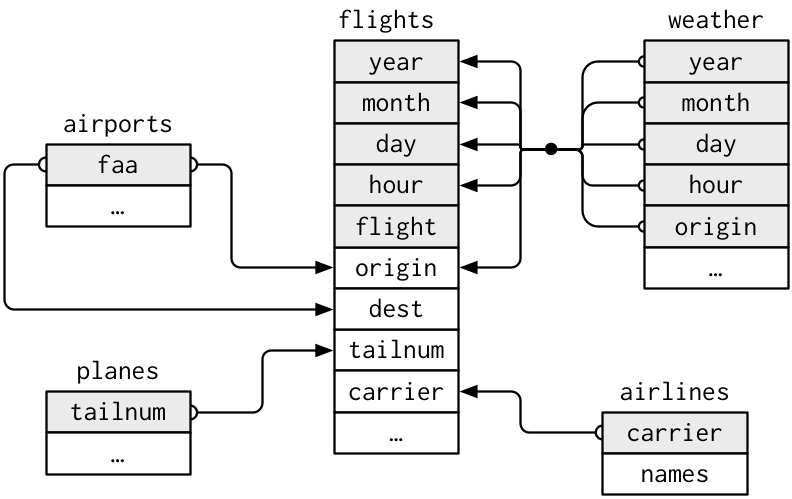
Bu diyagram size biraz karmaşık görünebilir fakat gerçek hayatta göreceklerinize göre yine de basittir! Bu gibi diyagramları anlamanın yolu her ilişkinin her zaman bir çift tablodan oluştuğunu hatırlamaktır. Bütününü anlamanız gerekmiyor; sadece ilgilendiğiniz tablolar arasındaki ilişki zincirini anlamanız yeterli.
nycflights13 için:
flights,planese tek bir değişkenle,tailnumile bağlanıyor.flights,airlinesecarrierdeğişkeniyle bağlanıyor.flights,airportsa iki yolla bağlanıyor:originvedest.flightsweatheraorigin(konum),year,month,dayvehour(zaman) yoluyla bağlanıyor.
13.2.1 Alıştırmalar
Her uçağın başlangıç noktasından hedefine olan varış yolunu (yaklaşık olarak) çizmek istediğinizi hayal edin. Hangi değişkenlere ihtiyacınız olur? Hangi tabloları bir araya getirmeniz gerekir?
weatherveairportsarasındaki ilişkiyi çizmeyi unuttum. Bu ilişki nedir ve diyagramda nasıl görünür?weathersadece (NYC) havalimanları kaynaklarını içeriyor. Eğer USA’daki bütün havalimanlarıyla ilgili hava durumu bilgilerini içerseydi,flightsla hangi ilave bağlantıyı tanımlardı?Yılın bazı günlerinin “özel” olduğunu ve o günlerde normalden az insanın uçtuğunu biliyoruz. Bu veriyi bir veri tablosu olarak nasıl gösterirdiniz? Bu tablonun birincil anahtarları ne olurdu? Varolan tablolara nasıl bağlanırdı?
13.3 Anahtarlar
İki tabloyu birbirine bağlayan değişkenler anahtarlar olarak tanımlanır. Anahtar, bir gözlemi birebir olarak tanımlayan değişkene (ya da değişkenler setine) denir. Basit durumlarda tek bir değişken bir gözlemi tanımlamak için yeterlidir. Mesela, her uçak birebir olarak tailnumıyla tanımlanır. Diğer durumlarda birden fazla değişken gerekebilir. Mesela, weatherda bir gözlemi tanımlamak için beş tane değişkene ihtiyacınız vardır: year, month, day, hour, ve origin.
İki çeşit anahtar vardır:
birincil anahtar bir gözlemi kendi tablosu içinde birebir olarak tanımlar. Mesela,
planes$tailnumbir birincil anahtardır çünküplanestablosundaki her uçağı birebir olarak tanımlar.yabancı anahtar başka bir tablodaki bir gözlemi birebir olarak tanımlar. Mesela,
flights$tailnumbir yabancı anahtardır çünkü her uçuşu spesifik bir uçağa eşleyenflightstablosunda yer alır.
Bir değişken hem birincil anahtar hem de yabancı anahtar olabilir. Örneğin, origin, weather birincil anahtarının parçasıdır ve aynı zamanda airport tablosu için de yabancı anahtardır.
Tablolarınızdaki birincil anahtarları tanımladıktan sonra, gerçekten her gözlemi birebir olarak tanımlayıp tanımlamadıklarını doğrulamak iyi bir pratiktir. Bunu yapmanın bir yolu, birincil anahtarları count() fonksiyonuyla saymak ve nin birden büyük olduğu girdilere göz atmaktır:
planes %>%
count(tailnum) %>%
filter(n > 1)
#> # A tibble: 0 × 2
#> # … with 2 variables: tailnum <chr>, n <int>
weather %>%
count(year, month, day, hour, origin) %>%
filter(n > 1)
#> # A tibble: 3 × 6
#> year month day hour origin n
#> <int> <int> <int> <int> <chr> <int>
#> 1 2013 11 3 1 EWR 2
#> 2 2013 11 3 1 JFK 2
#> 3 2013 11 3 1 LGA 2Bazen bir tablonun belirli bir birinci anahtarı yoktur: her satır bir gözlemdir fakat değişkenlerin hiçbir kombinasyonu onu hatasız olarak tanımlamaz. Örneğin, flights tablosundaki birincil anahtar nedir? Tarih ve uçuş veya kuyruk numarasının olduğunu düşünebilirsiniz ama bunlardan hiçbiri birebir tanımlama değildir:
flights %>%
count(year, month, day, flight) %>%
filter(n > 1)
#> # A tibble: 29,768 × 5
#> year month day flight n
#> <int> <int> <int> <int> <int>
#> 1 2013 1 1 1 2
#> 2 2013 1 1 3 2
#> 3 2013 1 1 4 2
#> 4 2013 1 1 11 3
#> 5 2013 1 1 15 2
#> 6 2013 1 1 21 2
#> # … with 29,762 more rows
flights %>%
count(year, month, day, tailnum) %>%
filter(n > 1)
#> # A tibble: 64,928 × 5
#> year month day tailnum n
#> <int> <int> <int> <chr> <int>
#> 1 2013 1 1 N0EGMQ 2
#> 2 2013 1 1 N11189 2
#> 3 2013 1 1 N11536 2
#> 4 2013 1 1 N11544 3
#> 5 2013 1 1 N11551 2
#> 6 2013 1 1 N12540 2
#> # … with 64,922 more rowsBu veriyle çalışmaya başlarken her uçuş numarasının safça her gün bir kere kullanılacağını varsaymıştım: böyle olması belirli bir uçuşla ilgili problemleri aktarmayı çok daha kolay yapacaktı. Ne yazık ki durum böyle değil! Eğer bir tablonun birincil anahtarı yoksa bazen mutate() veya row_number() ile bir tane eklemek faydalıdır. Bu, eğer filtreleme yaptıysanız ve orijinal veriyle tekrar kontrol etmek istiyorsanız gözlemleri eşleştirmeyi kolaylaştırır. Bunun ismi vekil anahtar dır.
Birincil anahtar ve onun başka bir tablodaki yabancı anahtarı bir ilişki oluşturur. İlişkiler tipik olarak birden-çoğa olur. Örneğin, her uçuşun bir tane uçağı var fakat her uçağın bir çok uçuşu var. Farklı bir veride ara sıra birebir ilişki görebilirsiniz. Bu durumu birden-çoğa ilişkinin özel bir durumu olarak düşünebilirsiniz. Çoktan-çoğa ilişkileri çoktan-bire ve birden-çoğa ilişkilerin bir toplamı olarak düşünebilirsiniz. Örneğin, şu veride hava yolu şirketleriyle hava limanları arasında çoktan-çoğa bir ilişki var: her hava yolu şirketi bir çok havalimanına uçuyor; her havalimanı bir sürü hava yolu şirketini barındırıyor.
13.3.1 Alıştırmalar
flightsa bir tane vekil anahtar ekleyin.Aşağıdaki veri setlerindeki anahtarları belirleyin
Lahman::Batting,babynames::babynamesnasaweather::atmosfueleconomy::vehiclesggplot2::diamonds
(Bazı paketleri yüklemeniz ve biraz dokümantasyon okumanız gerekebilir.)
Lahman paketindeki
Batting,Master, veSalariestablolarındaki
bağlantıları gösteren bir diyagram çizin.Master,Managers,
AwardsManagersarasındaki ilişkileri gösteren başka bir diyagram daha çizin.Batting,Pitching, veFieldingtabloları arasındaki ilişkiyi nasıl tanımlardınız?
13.4 Değiştiren birleştirmeler
Bir çift tabloyu bir araya getirmek için inceleyeceğimiz ilk araç değiştiren birleştirme dir. Değiştiren birleştirme iki tablodaki değişkenleri bir araya getirmenize olanak sağlar. İlk olarak, gözlemleri anahtarlarıyla eşleştirir, sonrasında değişkenleri bir tablodan diğerine kopyalar.
mutate() fonksiyonu gibi, birleştirme fonksiyonları da sağ tarafa değişkenler ekler, yani zaten bir çok değişkeniniz varsa yeni değişkenler ekrana yansıtılmaz. Bu örnekler için, daha ufak bir veri seti yaratarak örneklerde ne olup bittiğini anlamanıza yardımcı olacağız.
flights2 <- flights %>%
select(year:day, hour, origin, dest, tailnum, carrier)
flights2
#> # A tibble: 336,776 × 8
#> year month day hour origin dest tailnum carrier
#> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr>
#> 1 2013 1 1 5 EWR IAH N14228 UA
#> 2 2013 1 1 5 LGA IAH N24211 UA
#> 3 2013 1 1 5 JFK MIA N619AA AA
#> 4 2013 1 1 5 JFK BQN N804JB B6
#> 5 2013 1 1 6 LGA ATL N668DN DL
#> 6 2013 1 1 5 EWR ORD N39463 UA
#> # … with 336,770 more rows(Hatırlatalım, RStudio’nun içindeyken bu sorunla karşılaşmamak için View()i de kullanabilirsiniz.)
Mesela flights2 verisine hava yolu şirketinin tam ismini eklemek istediğinizi düşünün. airlines ve flights2 veri tablolarını left_join() ile birleştirebilirsiniz:
flights2 %>%
select(-origin, -dest) %>%
left_join(airlines, by = "carrier")
#> # A tibble: 336,776 × 7
#> year month day hour tailnum carrier name
#> <int> <int> <int> <dbl> <chr> <chr> <chr>
#> 1 2013 1 1 5 N14228 UA United Air Lines Inc.
#> 2 2013 1 1 5 N24211 UA United Air Lines Inc.
#> 3 2013 1 1 5 N619AA AA American Airlines Inc.
#> 4 2013 1 1 5 N804JB B6 JetBlue Airways
#> 5 2013 1 1 6 N668DN DL Delta Air Lines Inc.
#> 6 2013 1 1 5 N39463 UA United Air Lines Inc.
#> # … with 336,770 more rowsflights2 verisine havayollarını eklemenin sonucu olarak yeni bir değişken oluştu: name. Bu tür birleştirmeleri değiştiren birleştirme olarak adlandırmamın amacı bu. Buöyle bir durumda, mutate() ve R’ın temel alt kümelemesini kullanarak aynı sonuca ulaşabilirdiniz:
flights2 %>%
select(-origin, -dest) %>%
mutate(name = airlines$name[match(carrier, airlines$carrier)])
#> # A tibble: 336,776 × 7
#> year month day hour tailnum carrier name
#> <int> <int> <int> <dbl> <chr> <chr> <chr>
#> 1 2013 1 1 5 N14228 UA United Air Lines Inc.
#> 2 2013 1 1 5 N24211 UA United Air Lines Inc.
#> 3 2013 1 1 5 N619AA AA American Airlines Inc.
#> 4 2013 1 1 5 N804JB B6 JetBlue Airways
#> 5 2013 1 1 6 N668DN DL Delta Air Lines Inc.
#> 6 2013 1 1 5 N39463 UA United Air Lines Inc.
#> # … with 336,770 more rowsAma bir çok değişkeni eşlemeniz gerektiğinde bunu genellemek zorlaşır, ve ana amacı anlamak detaylı okuma gerektirir.
Sonraki bölümler, değiştiren birleştirmelerin nasıl çalıştığını detaylı olarak açıklıyor. Birleştirmelerin faydalı bir görsel anlatımını öğrenerek başlayacaksınız. Daha sonra bunu kullanarak değiştiren birleştirmenin dört fonksiyonunu açıklayacağız: içten birleştirme, ve diğer diğer üç dıştan birleştirme. Gerçek veriyle çalışırken anahtarlar gözlemleri her zaman birebir olarak tanımlamazlar, o yüzden sonrasında birebir eşleşme olmadığında ne olduğunu konuşacağız. Son olarak elinizdeki bir birleştirme için dplyr’a hangi değişkenlerin anahtar olduğunu nasıl söyleyeceğinizi öğreneceksiniz.
13.4.1 Birleştirmeleri anlamak
Birleştirmelerin nasıl çalıştığını öğrenmenize yardım etmek için görsel bir anlatım kullanacağım:
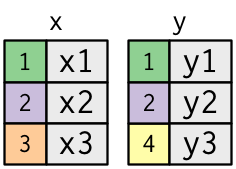
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
3, "x3"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
4, "y3"
)Renkli sütun “anahtar” değişkeni temsil ediyor: bunlar tablolar arasındaki satırları eşleştirmek için kullanılıyor. Gri sütun işlem boyunca taşınan “değer” sütununu temsil ediyor. Bu örnekte size tek bir anahtar değişken göstereceğim fakat anafikir kolayca birden çok anahtara ve birden çok değere genelleştirilebilir.
Birleştirme, xteki her satırı ydeki sıfır, bir veya daha fazla satıra bitiştirmenin bir yoludur. Aşağıdaki grafik her potansiyel eşleşmeyi bir çift satırın kesişimi olarak gösteriyor.
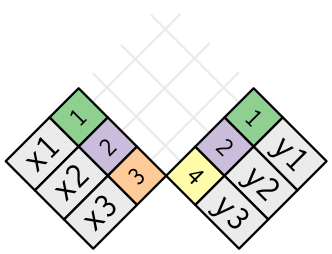
(Yakından bakarsanız xdeki anahtar ve değer sütunlarının sırasını değiştirdiğimizi fark edebilirsiniz. Bu, birleştirmelerin anahtara bağlı olarak eşleştiğini vurgulamak için; değer sadece işlem boyunca taşınıyor.)
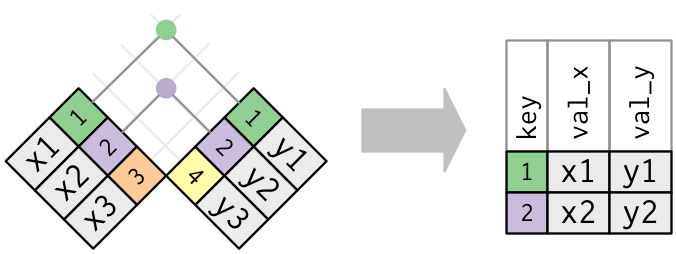
Gerçek bir birleştirmede eşleşmeler noktalarla belirtilmiş olacak. Noktaların sayısı = eşleşmelerin sayısı = çıktıdaki satırların sayısı.
13.4.2 İçten birleştirme
En basit birleştirme biçimi içten birleştirme dir. İçten birleştirme anahtarları birbirine eşit olduğunda gözlem çiftlerini eşleştirir:
(Net olmak gerekirse, bu bir içten eşbirleştirme dir çünkü anahtarlar eşitlik operatörü kullanılarak eşleştirilir. Çoğu birleştirme eşbirleştirme olduğu için genelde bu ayrıntıyı belirtmiyoruz.)
Bir içten birleştirmenin çıktısı, anahtarı, x değerlerini ve y değerlerini içeren yeni bir veri tablosudur. Dplyr’a hangi değişkenin anahtar olduğunu söylemek için by kullanıyoruz:
x %>%
inner_join(y, by = "key")
#> # A tibble: 2 × 3
#> key val_x val_y
#> <dbl> <chr> <chr>
#> 1 1 x1 y1
#> 2 2 x2 y2İçten birleştirmenin en önemli özelliği eşlenmeyen satırların sonuçta yer almamasıdır. Bu demektir ki, genel olarak, içten birleştirmeler analizde kullanmaya uygun değildir çünkü gözlemleri kaybetmek çok kolaydır.
13.4.3 Dıştan birleştirmeler
Bir içten birleştirme her iki tabloda olan gözlemleri tutar. Bir dıştan birleştirme tablolardan en az birinde olan gözlemleri tutar. Dıştan birleştirmelerin üç çeşidi vardır:
- Bir soldan birleştirme
xiçindeki tüm gözlemleri tutar. - Bir sağdan birleştirme
yiçindeki tüm gözlemleri tutar. - Bir tam birleştirme
xveyiçindeki tüm gözlemleri tutar.
Bu birleştirmeler her tabloya “sanal” bir gözlem ekleyerek çalışır. Bu gözlemin her zaman eşleşen bir anahtarı (eğer başka bir anahtar eşleşmiyorsa) ve NA doldurulan bir değeri vardır.
Grafiksel olarak bu şu şekilde görünür:
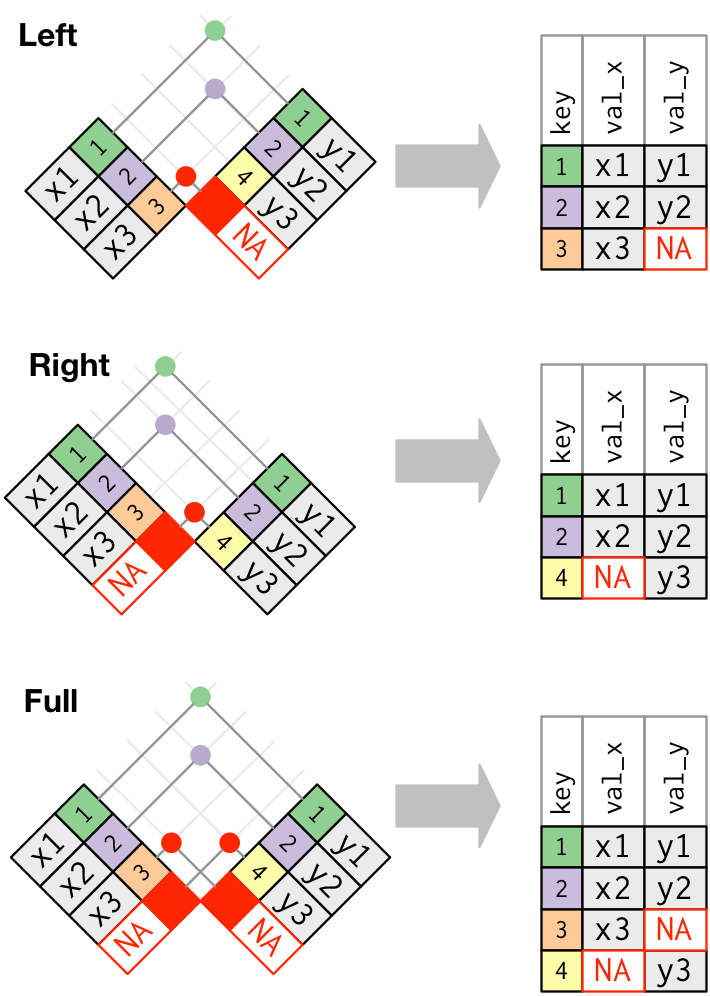
En yaygın kullanılan birleştirme soldan birleştirmedir: ne zaman başka bir tablodan ek veri ararsanız bunu kullanırsınız çünkü eşleşme olmadığında bile asıl gözlemleri korur. Soldan birleştirme sizin ilk seçiminiz olmalıdır: diğerlerinden birini kullanmak için güçlü bir sebebiniz olmadığında onu kullanın.
Farklı birleştirme seçeneklerini göstermenin başka bir yolu Venn şemasıdır:
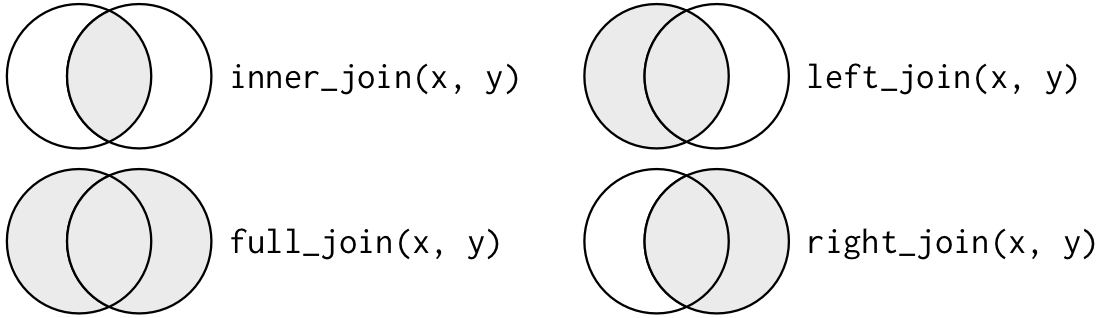
Yine de bu anlatım kusursuz değildir. Hangi birleştirmenin hangi tablodaki gözlemleri tutacağını hafızanıza kazıyabilir ama temel bir dezavantajı vardır: bir Venn şeması, anahtarlar birebir olarak bir gözleme eşleşmediğinde başlarına ne geldiğini gösteremez.
13.4.4 Çoğul anahtarlar
Şimdiye kadar bütün grafikler anahtarların birebir olduğunu varsaydı. Fakat bu her zaman böyle değil. Bu bölüm anahtarlar birebir olmadığında ne olduğunu açıklıyor. İki seçenek vardır:
Bir tabloda çoğul anahtarlar vardır. Bu, fazladan bilgi eklemek
istediğinizde faydalıdır çünkü tipik olarak birden-çoğa ilişki vardır.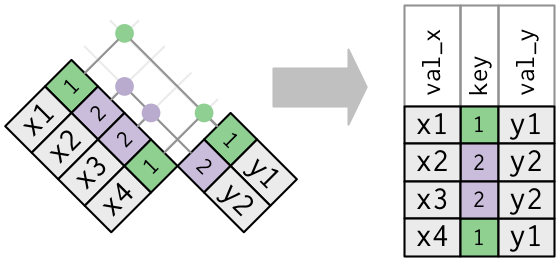
Çıktıda anahtar sütununu biraz farklı bir yere koyduğuma dikkatinizi çekerim. Bu, anahtarın
yde birincil anahtar vexde yabancı bir anahtar olduğunu yansıtır.x <- tribble( ~key, ~val_x, 1, "x1", 2, "x2", 2, "x3", 1, "x4" ) y <- tribble( ~key, ~val_y, 1, "y1", 2, "y2" ) left_join(x, y, by = "key") #> # A tibble: 4 × 3 #> key val_x val_y #> <dbl> <chr> <chr> #> 1 1 x1 y1 #> 2 2 x2 y2 #> 3 2 x3 y2 #> 4 1 x4 y1İki tablonun da çoğul anahtarı vardır. Bu genelde bir hatadır çünkü hiçbir tabloda anahtarlar bir gözlemi birebir olarak tanımlamaz. Çoğul anahtarları birleştirdiğinizde, Kartezyen çarpımı, tüm olası kombinasyonları elde edersiniz:
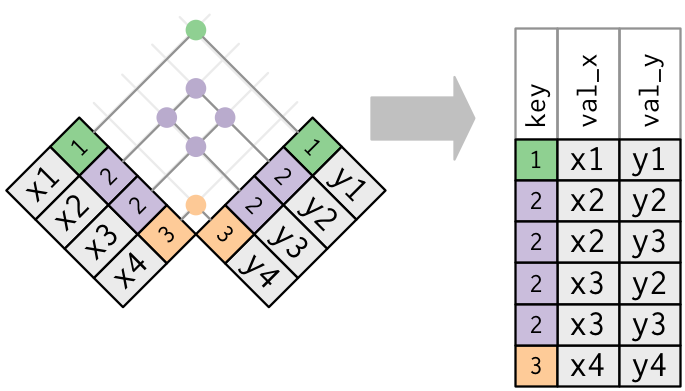
x <- tribble( ~key, ~val_x, 1, "x1", 2, "x2", 2, "x3", 3, "x4" ) y <- tribble( ~key, ~val_y, 1, "y1", 2, "y2", 2, "y3", 3, "y4" ) left_join(x, y, by = "key") #> # A tibble: 6 × 3 #> key val_x val_y #> <dbl> <chr> <chr> #> 1 1 x1 y1 #> 2 2 x2 y2 #> 3 2 x2 y3 #> 4 2 x3 y2 #> 5 2 x3 y3 #> 6 3 x4 y4
13.4.5 Anahtar sütunların tanımlanması
Şimdiye kadar tablo çiftleri her zaman tek bir değişkenle birleştirildi ve o değişken her zaman iki tabloda da aynı isme sahipti. Bu kısıtlama by = "key" ile kodlanmıştı. Tabloları başka şekillerde bağlamak için by ile birlikte diğer değerleri kullanabilirsiniz:
Otomatik olarak,
by = NULL, her iki tabloda bulunan tüm değişkenleri
doğal birleştirme diye geçen şekilde kullanır. Örneğin, uçuşlar ve hava durumu tabloları ortak değişkenlerinde eşleşirler:year,month,day,hourveorigin.flights2 %>% left_join(weather) #> Joining, by = c("year", "month", "day", "hour", "origin") #> # A tibble: 336,776 × 18 #> year month day hour origin dest tailnum carrier temp dewp humid #> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> #> 1 2013 1 1 5 EWR IAH N14228 UA 39.0 28.0 64.4 #> 2 2013 1 1 5 LGA IAH N24211 UA 39.9 25.0 54.8 #> 3 2013 1 1 5 JFK MIA N619AA AA 39.0 27.0 61.6 #> 4 2013 1 1 5 JFK BQN N804JB B6 39.0 27.0 61.6 #> 5 2013 1 1 6 LGA ATL N668DN DL 39.9 25.0 54.8 #> 6 2013 1 1 5 EWR ORD N39463 UA 39.0 28.0 64.4 #> # … with 336,770 more rows, and 7 more variables: wind_dir <dbl>, #> # wind_speed <dbl>, wind_gust <dbl>, precip <dbl>, pressure <dbl>, #> # visib <dbl>, time_hour <dttm>Bir karakter vektörü,
by = "x". Bu doğal birleştirmeye benzer fakat sadece ortak değişkenlerin bir kısmını kullanır. Örneğin,flightsveplanesninyear
değişkenleri var fakat farklı anlamlara geliyorlar ve bu yüzden sadecetailnumile birleştirmek istiyoruz.flights2 %>% left_join(planes, by = "tailnum") #> # A tibble: 336,776 × 16 #> year.x month day hour origin dest tailnum carrier year.y type #> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <int> <chr> #> 1 2013 1 1 5 EWR IAH N14228 UA 1999 Fixed wing multi… #> 2 2013 1 1 5 LGA IAH N24211 UA 1998 Fixed wing multi… #> 3 2013 1 1 5 JFK MIA N619AA AA 1990 Fixed wing multi… #> 4 2013 1 1 5 JFK BQN N804JB B6 2012 Fixed wing multi… #> 5 2013 1 1 6 LGA ATL N668DN DL 1991 Fixed wing multi… #> 6 2013 1 1 5 EWR ORD N39463 UA 2012 Fixed wing multi… #> # … with 336,770 more rows, and 6 more variables: manufacturer <chr>, #> # model <chr>, engines <int>, seats <int>, speed <int>, engine <chr>Dikkatinizi çekerim ki
yeardeğişkenleri (her iki veri tablosunda bulunan fakat eşit olmak zorunda bırakılmayan) çıktıda bir son-ek ile ayrıştırılmıştır.İsimlendirilmiş bir karakter vektörü:
by = c("a" = "b"). Bu,xtablosundakiadeğişkeniniytablosundakibdeğişkenine eşleştirir. Çıktıdaxe ait değişkenler kullanılacaktır.Örneğin, eğer bir harita çizmek istersek uçuşlar verisini, her havalimanının konumunu (
latvelon) içeren havalimanları verisiyle birleştirmemiz gerekir. Her uçuşun bir çıkış ve varışairportu vardır, bu yüzden hangisine birleştirmek istediğimizi belirtmemiz gerekir:flights2 %>% left_join(airports, c("dest" = "faa")) #> # A tibble: 336,776 × 15 #> year month day hour origin dest tailnum carrier name lat lon alt #> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> #> 1 2013 1 1 5 EWR IAH N14228 UA George… 30.0 -95.3 97 #> 2 2013 1 1 5 LGA IAH N24211 UA George… 30.0 -95.3 97 #> 3 2013 1 1 5 JFK MIA N619AA AA Miami … 25.8 -80.3 8 #> 4 2013 1 1 5 JFK BQN N804JB B6 <NA> NA NA NA #> 5 2013 1 1 6 LGA ATL N668DN DL Hartsf… 33.6 -84.4 1026 #> 6 2013 1 1 5 EWR ORD N39463 UA Chicag… 42.0 -87.9 668 #> # … with 336,770 more rows, and 3 more variables: tz <dbl>, dst <chr>, #> # tzone <chr> flights2 %>% left_join(airports, c("origin" = "faa")) #> # A tibble: 336,776 × 15 #> year month day hour origin dest tailnum carrier name lat lon alt #> <int> <int> <int> <dbl> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> #> 1 2013 1 1 5 EWR IAH N14228 UA Newark… 40.7 -74.2 18 #> 2 2013 1 1 5 LGA IAH N24211 UA La Gua… 40.8 -73.9 22 #> 3 2013 1 1 5 JFK MIA N619AA AA John F… 40.6 -73.8 13 #> 4 2013 1 1 5 JFK BQN N804JB B6 John F… 40.6 -73.8 13 #> 5 2013 1 1 6 LGA ATL N668DN DL La Gua… 40.8 -73.9 22 #> 6 2013 1 1 5 EWR ORD N39463 UA Newark… 40.7 -74.2 18 #> # … with 336,770 more rows, and 3 more variables: tz <dbl>, dst <chr>, #> # tzone <chr>
13.4.6 Alıştırmalar
Varış noktasına göre ortalama gecikmeyi hesaplayın, ardından
airportsveri tablosuyla birleştirin ve böylece gecikmelerin konumsal dağılımını gösterin. Amerika Birleşik Devletleri’nin haritasını çizmenin kolay bir yolu şöyledir:airports %>% semi_join(flights, c("faa" = "dest")) %>% ggplot(aes(lon, lat)) + borders("state") + geom_point() + coord_quickmap()(Eğer
semi_join()nin ne yaptığını anlamıyorsanız endişelenmeyin — yakında o konuyu işleyeceğiz.)Her havalimanı için ortalama gecikmeyi göstermek için noktaların
sizeveyacolourözelliğini kullanmak isteyebilirsiniz.Çıkış ve varış noktasının konumunu (
latvelon)flightsa ekleyin.Uçağın yaşı ve gecikmeleri arasında bir ilişki var mı?
Hangi hava durumları gecikmeyle karşılaşma ihtimalini arttırıyor?
13 Haziran 2013 tarihinde ne oldu? Gecikmelerin konumsal örüntüsünü gösterin ve ardından Google’ı kullanarak hava durumuyla doğrulayın.
13.4.7 Diğer kullanımlar
base::merge() değiştiren birleştirmelerin dört çeşidini gerçekleştirebilir:
| dplyr | merge |
|---|---|
inner_join(x, y) |
merge(x, y) |
left_join(x, y) |
merge(x, y, all.x = TRUE) |
right_join(x, y) |
merge(x, y, all.y = TRUE), |
full_join(x, y) |
merge(x, y, all.x = TRUE, all.y = TRUE) |
Özelleşmiş dplyr fiillerinin avantajları kodunuzun amacını daha açık şekilde ifade edebilmelerindedir: birleştirmeler arasındaki fark gerçekten önemlidir fakat merge() argümanlarında gizlenmiştir. dplyr’daki birleştirmeler önemli ölçüde daha hızlıdır ve sütunların sıralamasını da bozmaz.
dplyr yöntemlerinin ilhamını SQL’den alır, bu yüzden tercümeleri basittir:
| dplyr | SQL |
|---|---|
inner_join(x, y, by = "z") |
SELECT * FROM x INNER JOIN y USING (z) |
left_join(x, y, by = "z") |
SELECT * FROM x LEFT OUTER JOIN y USING (z) |
right_join(x, y, by = "z") |
SELECT * FROM x RIGHT OUTER JOIN y USING (z) |
full_join(x, y, by = "z") |
SELECT * FROM x FULL OUTER JOIN y USING (z) |
“INNER” ve “OUTER”ın seçmeli olduğunu ve genelde kullanılmadığını belirtelim.
Tablolar arasındaki farklı değişkenleri birleştirmek, e.g. inner_join(x, y, by = c("a" = "b")) SQL’de farklı bir sözdizimi kullanır: SELECT * FROM x INNER JOIN y ON x.a = y.b. Bu sözdiziliminin gösterdiği gibi, SQL dplyr’a göre daha geniş birleştirme çeşitlerini destekler çünkü tabloları eşitlik dışında kısıtlar kullanarak da birleştirebilirsiniz (bazen eşitsiz-birleştirmeler diye geçen).
13.5 Filtreleyen birleştirmeler
Filtreleyen birleştirmeler gözlemleri, değiştiren birleştirmelerle aynı şekilde eşleştirir fakat değişkenleri değil gözlemleri etkiler. İki çeşidi vardır:
semi_join(x, y)yde bir eşi olanxdeki tüm gözlemleri korur.anti_join(x, y)yde bir eşi olanxdeki tüm gözlemleri dışarıda bırakır.
Yarı-birleştirmeler, filtrelenmiş özet tabloları orijinal sütunlara geri eşleştirmek için kullanışlıdır. Örneğin, en popüler on istikameti bulduğunuzu varsayalım:
top_dest <- flights %>%
count(dest, sort = TRUE) %>%
head(10)
top_dest
#> # A tibble: 10 × 2
#> dest n
#> <chr> <int>
#> 1 ORD 17283
#> 2 ATL 17215
#> 3 LAX 16174
#> 4 BOS 15508
#> 5 MCO 14082
#> 6 CLT 14064
#> # … with 4 more rowsŞimdi ise bu istikametlerden bir tanesine gitmiş olan her uçuşu bulmak istiyorsunuz. Kendinize bir filtre oluşturabilirsiniz:
flights %>%
filter(dest %in% top_dest$dest)
#> # A tibble: 141,145 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 542 540 2 923 850
#> 2 2013 1 1 554 600 -6 812 837
#> 3 2013 1 1 554 558 -4 740 728
#> 4 2013 1 1 555 600 -5 913 854
#> 5 2013 1 1 557 600 -3 838 846
#> 6 2013 1 1 558 600 -2 753 745
#> # … with 141,139 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>Fakat bu yaklaşımı çoklu değişkenlere genişletmek zordur. Örneğin, en yüksek ortalama gecikmeli 10 günü bulmak istediğinizi hayal edin. Tekrardan flightsa eşlemek için year, month, ve dayi kullanan filtreleme komutunu nasıl yaratırdınız?
Onun yerine, değiştiren birleştirme gibi tabloları birleştiren fakat yeni sütunlar eklemek yerine yde bir eşi olan xdeki satırları koruyan bir yarı-birleştirme kullanabilirsiniz:
flights %>%
semi_join(top_dest)
#> Joining, by = "dest"
#> # A tibble: 141,145 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 542 540 2 923 850
#> 2 2013 1 1 554 600 -6 812 837
#> 3 2013 1 1 554 558 -4 740 728
#> 4 2013 1 1 555 600 -5 913 854
#> 5 2013 1 1 557 600 -3 838 846
#> 6 2013 1 1 558 600 -2 753 745
#> # … with 141,139 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
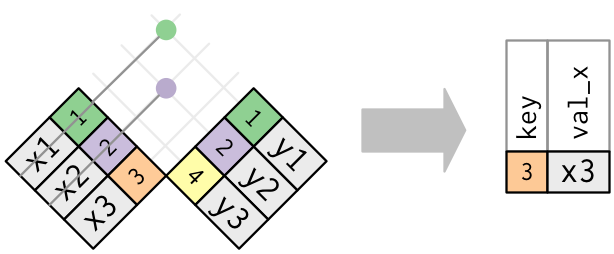
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>Grafik olarak yarı-birleştirme şu şekilde görünür:
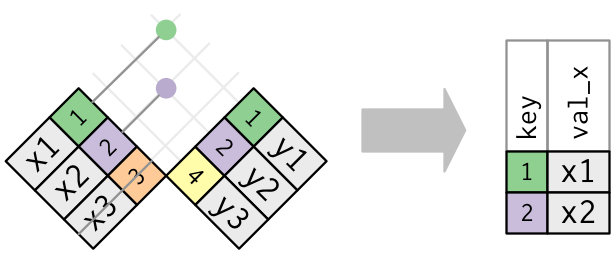
Sadece eşleşmenin olması önemli; hangi gözlemin eşleştiğinin bir önemi yok. Bu demektir ki filtreleyen birleştirmeler değiştiren birleştirmelerin yaptığı gibi asla sütun kopyalama yapmaz:
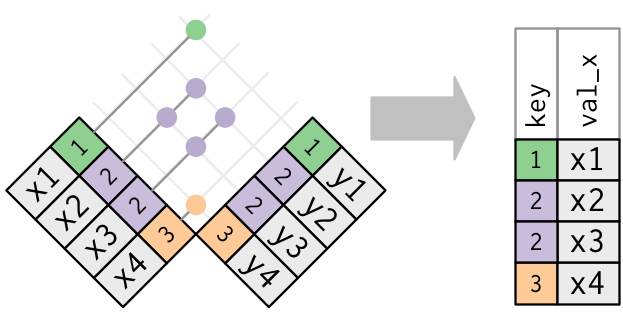
Yarı-birleştirmenin tersi zıt-birleştirmedir. Zıt-birleştirme bir eşi olmayan sütunları muhafaza eder:
Zıt-birleştirmeler, yanlış eşleştirmelerin teşhisinde faydalıdır. Örneğin, flights ve planesi bağlarken, planesde bir eşi olmayan bir çok flights olup olmadığını öğrenmek isteyebilirsiniz :
flights %>%
anti_join(planes, by = "tailnum") %>%
count(tailnum, sort = TRUE)
#> # A tibble: 722 × 2
#> tailnum n
#> <chr> <int>
#> 1 <NA> 2512
#> 2 N725MQ 575
#> 3 N722MQ 513
#> 4 N723MQ 507
#> 5 N713MQ 483
#> 6 N735MQ 396
#> # … with 716 more rows13.5.1 Alıştırmalar
Bir uçuş için
tailnumın olmaması ne anlama gelir?planesde eşleşen bir kaydı olmayan kuyruk numaralarının ortak özelliği nedir? (İpucu: bir değişken problemlerin ~%90 ını açıklıyor.)Sadece en az 100 uçuşu olan uçaklarla yapılan uçuşları gösterecek şekilde filtre uygulayın.
Sadece en yaygın modellerin kayıtlarını bulmak için
fueleconomy::vehiclesvefueleconomy::commonı birleştirin.En kötü gecikmeye sahip 48 saati (bir tam yıl süresince) bulun. Bunu
weatherverisiyle çapraz-referanslayın. Bir örüntü görebiliyor musunuz?Sizce
anti_join(flights, airports, by = c("dest" = "faa"))ne anlatıyor? Sizceanti_join(airports, flights, by = c("faa" = "dest"))ne anlatıyor?Her uçak tek bir havayolu tarafından uçurulduğu için uçak ve havayolu arasında örtülü bir ilişki olduğunu bekleyebilirsiniz. Yukarıda öğrendiğiniz araçları kullanarak bu hipotezi doğrulayın veya reddedin.
13.6 Birleştirme problemleri
Bu bölümde üzerinde çalışıyor olduğunuz veri, olabildiğince az problemle karşılaşmanız için temizlenmiştir. Kendi veriniz büyük ihtimalle bu kadar düzgün olmayacaktır, bu yüzden birleştirmelerinizin pürüzsüz olması için verinizle ilgili yapmanız gereken bir kaç şey var.
Her tabloda birincil anahtarı oluşturan değişkenleri tanımlayarak başlayın. Bunu genelde veriyi anlamanıza dayalı olarak yapmanız gerekir, deneysel olarak özgün bir tanımlayıcı veren değişkenlerin kombinasyonuna bakarak değil. Eğer ne anlama geldiklerini düşünmeden sadece değişkenlere bakarsanız şanslı(ya da şanssız) olup güncel verinizde birebir olan ama genel itibariyle böyle olmayan bir kombinasyon bulabilirsiniz.
Örneğin, rakım ve boylam özgün olarak her havalimanını tanımlar, fakat onlar iyi tanımlayıcılar değildir!
airports %>% count(alt, lon) %>% filter(n > 1) #> # A tibble: 0 × 3 #> # … with 3 variables: alt <dbl>, lon <dbl>, n <int>Birincil anahtardaki hiçbir değişkenin eksik olup olmadığını kontrol edin. Eğer bir değer eksikse o zaman o bir gözlemi tanımlayamaz!
Yabancı anahtarlarınızın başka bir tablodaki birincil anahtarlarla eşleşip eşleşmediğini kontrol edin. Bunu yapmanın en iyi yolu
anti_join()kullanmaktır. Veri girişi hatası sebebiyle anahtarların eşleşmemesi yaygındır. Bunları düzeltmek genelde çok uğraştırır.Eğer gerçekten eksik anahtarlarınız varsa, içten vs. dıştan birleştirmelerinizle ilgili dikkatli olmalı, eşleşmeyen sütunları kaldırmak isteyip istemediğinizi dikkatlice gözden geçirmelisiniz.
Birleştirmelerinizin yolunda gidip gitmediğinden emin olmak için, sadece birleştirmeden önce ve sonraki sütun sayısını kontrol etmenin yeterli olmadığına dikkatinizi çekerim. Eğer her iki tabloda da kopya anahtarlı içten birleştirmeniz varsa kaldırılan sütunların sayısıyla kopyalanmış sütunların sayısının tam olarak birbirine eşit olması gibi şanssız bir durumla karşılaşabilirsiniz!
13.7 Takım işlemleri
İki-tablolu fiilin son çeşidi takım operasyonlarıdır. Genellikle, bunları çok seyrek kullanırım, ama bazen tek bir kompleks filtreyi daha basit parçalara ayırmak istediğinizde işe yararlar. Bu işlemlerin hepsi, her değişkenin değerini karşılaştırarak, bir satırın bütünüyle çalışır. Bunlar x ve y girdilerinin aynı değişkenlere sahip olmasını bekler ve gözlemleri takımlar gibi değerlendirirler:
intersect(x, y): sadece hemxhem deyde olan gözlemleri bildirir.union(x, y):xveydeki eşsiz gözlemleri bildirir.setdiff(x, y):xde olup,yde olmayan gözlemleri bildirir.
Bu basit veriye göre:
df1 <- tribble(
~x, ~y,
1, 1,
2, 1
)
df2 <- tribble(
~x, ~y,
1, 1,
1, 2
)Dört olasılık şunlardır:
intersect(df1, df2)
#> # A tibble: 1 × 2
#> x y
#> <dbl> <dbl>
#> 1 1 1
# 3 değil de 4 tane satır elde ettiğimize dikkat edin
union(df1, df2)
#> # A tibble: 3 × 2
#> x y
#> <dbl> <dbl>
#> 1 1 1
#> 2 2 1
#> 3 1 2
setdiff(df1, df2)
#> # A tibble: 1 × 2
#> x y
#> <dbl> <dbl>
#> 1 2 1
setdiff(df2, df1)
#> # A tibble: 1 × 2
#> x y
#> <dbl> <dbl>
#> 1 1 2